Data4All
收藏github2024-07-13 更新2024-07-16 收录
下载链接:
https://github.com/OpenSourceData2024/Data4All
下载链接
链接失效反馈官方服务:
资源简介:
海纳百川,数聚万象:数据的广泛汇集和无限可能。通过 Data4All 这个平台,开放数据资源如同百川汇海,不断流入,共同形成一个庞大而丰富的数据海洋。
All rivers converge into the sea, data aggregates myriad phenomena: the extensive aggregation and boundless potential of data. Through the Data4All platform, open data resources flow continuously, just as countless rivers merge into the sea, jointly forming a vast and abundant data ocean.
创建时间:
2024-07-13
原始信息汇总
数据集概述
一、定位
- 使命:让开源数据惠及每一个人
- 愿景:通过开源开放数据,推动社会进步和创新
- 核心价值:开放、共享、普惠、创新
二、项目架构
1. 数据平台
- 数据存储:建立高效、安全的数据存储系统,支持多种数据格式和结构。
- 数据管理:开发用户友好的数据管理工具,便于数据的上传、下载和管理。
- 数据分析:提供强大的数据分析工具,支持数据的可视化和多维度分析。
- 数据共享:设计数据共享机制,支持用户间的数据交换和合作。
2. 技术架构
- 前端:采用现代前端框架(如 React 或 Vue.js),提供流畅的用户体验。
- 后端:基于微服务架构,使用流行的编程语言(如 Python 或 Java),确保系统的高扩展性和可靠性。
- 数据库:使用高性能数据库(如 PostgreSQL 或 MongoDB),确保数据的高效存储和检索。
- 安全性:实施严格的安全措施,确保数据的隐私和安全。
三、社区建设
1. 社区平台
- 论坛:建立一个互动论坛,供用户讨论问题、分享经验和提出建议。
- Wiki:创建一个社区Wiki,记录项目的文档、教程和最佳实践。
- 贡献指南:编写详细的贡献指南,鼓励用户参与代码贡献、文档编写和社区活动。
2. 社区活动
- 线上研讨会:定期举办线上研讨会,邀请专家分享数据相关的知识和经验。
- 黑客马拉松:组织黑客马拉松活动,鼓励社区成员合作开发创新项目。
- 线下聚会:在主要城市举办线下聚会,加强社区成员的联系和互动。
四、技术支持
1. 文档和教程
- 提供详细的项目文档和教程,帮助新用户快速上手。
- 制作视频教程和示例项目,降低学习门槛。
2. 支持渠道
- 建立在线支持系统,通过论坛、邮件列表和即时通讯工具,及时解答用户疑问。
- 设立社区支持团队,负责处理用户反馈和技术问题。
五、参考项目
1. Common Crawl
- 简介:一个非营利组织,致力于构建和维护一个开源的互联网数据集,提供免费的网络抓取数据,涵盖网页文本、结构和元数据。
- 目标:推动创新和研究,支持自然语言处理、搜索引擎优化和数据分析等领域的应用。
2. Dolma
- 简介:由 Allen Institute for AI 创建的开源数据集和工具包,专用于语言模型预训练。
- 特点:数据集包含3万亿个标记,来源广泛,并提供在 HuggingFace Hub 上下载。
3. RefinedWeb
- 简介:为 Falcon 大型语言模型 (LLM) 预训练开发的高质量五万亿标记的纯网络数据集。
- 特点:通过严格的过滤和去重处理,证明仅使用网络数据即可训练出超越使用传统精选语料库的模型。
4. Pile
- 简介:一个 825G 的开源数据集,专为语言模型设计,由 22 个高质量的小数据集组成。
- 特点:涵盖了书籍、GitHub 仓库、网页和学术论文等多种文本来源,旨在增强大型语言模型的泛化能力和跨领域知识。
5. Zyda
- 简介:一个开源数据集,包含1.3万亿标记,专为语言模型预训练设计。
- 特点:通过整合RefinedWeb、Starcoder、C4、Pile 等多个高质量数据集,并进行严格的过滤和去重处理,旨在提供一个高性能且易于使用的数据集。
6. RedPajama
- 简介:一个开源数据集项目,提供了30万亿标记的网络数据集,用于语言模型训练。
- 特点:从超过100万亿标记的原始数据中经过严格过滤和去重处理,涵盖了英语、法语、西班牙语、德语和意大利语五种语言。
搜集汇总
数据集介绍
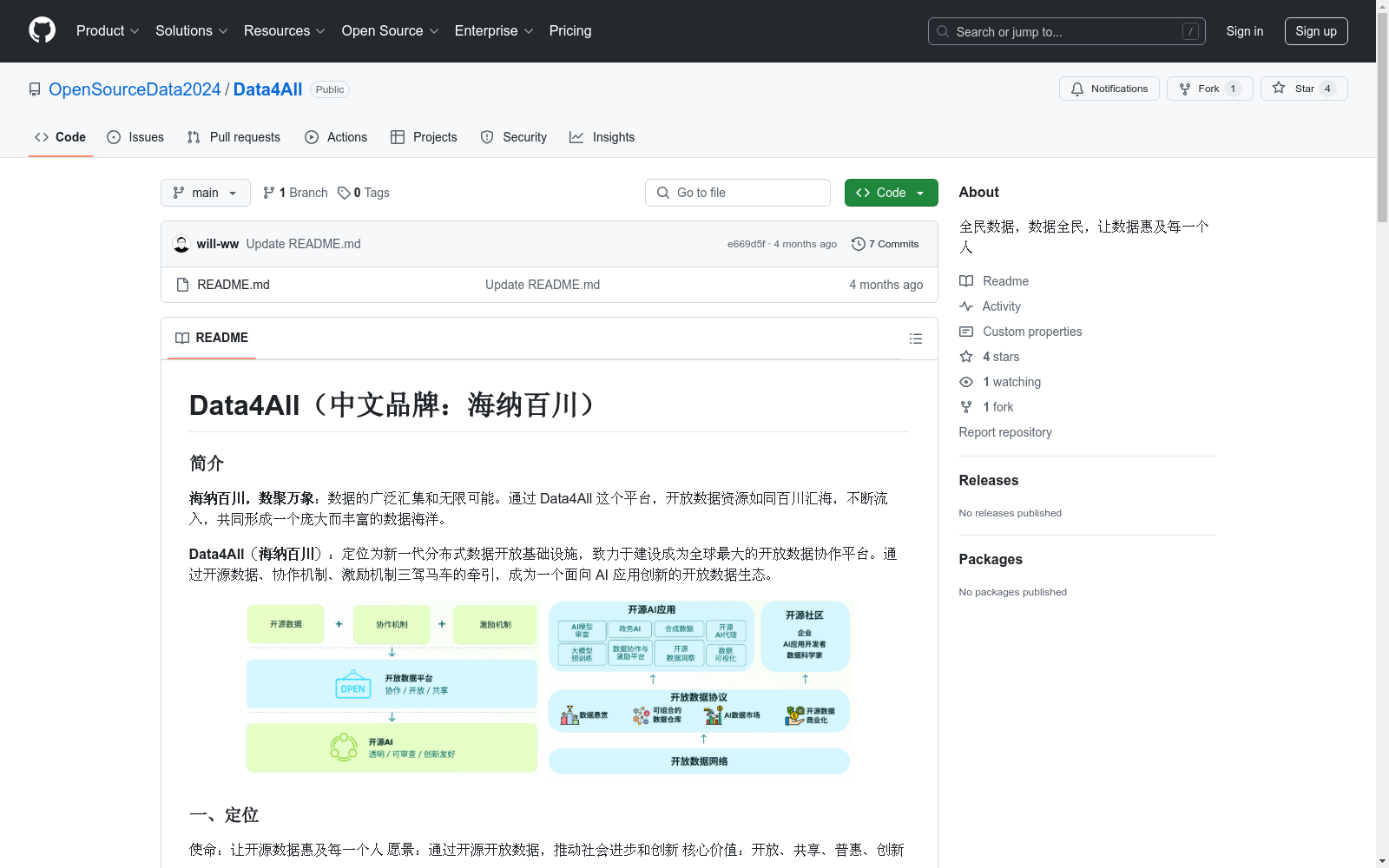
构建方式
Data4All数据集的构建基于分布式数据开放基础设施的理念,通过高效、安全的数据存储系统支持多种数据格式和结构。数据管理工具的开发使得数据的上传、下载和管理变得便捷,而强大的数据分析工具则支持数据的可视化和多维度分析。数据共享机制的设计进一步促进了用户间的数据交换和合作,确保了数据集的丰富性和多样性。
使用方法
Data4All数据集的使用方法简便且多样化。用户可以通过数据管理工具轻松上传、下载和管理数据,利用数据分析工具进行多维度分析和可视化。社区平台提供的论坛、Wiki和贡献指南进一步增强了用户的参与感和互动性。详细的文档和教程以及在线支持系统确保了新用户能够快速上手并充分利用数据集的资源。
背景与挑战
背景概述
Data4All(中文品牌:海纳百川)是一个定位为新一代分布式数据开放基础设施的项目,旨在建设成为全球最大的开放数据协作平台。该项目由一群致力于推动数据开放和共享的研究人员和机构于近年创建,其核心研究问题是如何通过开源数据、协作机制和激励机制,构建一个面向AI应用创新的开放数据生态。Data4All不仅提供高效、安全的数据存储和管理系统,还通过强大的数据分析工具和数据共享机制,推动数据资源的广泛汇集和无限可能。该项目对数据科学和人工智能领域具有深远影响,为全球研究者和开发者提供了一个丰富的数据资源库,促进了跨领域的创新和合作。
当前挑战
Data4All在构建过程中面临多重挑战。首先,数据存储和管理的复杂性要求项目必须建立高效、安全的数据系统,支持多种数据格式和结构。其次,数据分析工具的开发需要强大的技术支持,以确保数据的可视化和多维度分析的准确性和效率。此外,数据共享机制的设计和实施也是一大挑战,需要平衡数据隐私和安全与数据开放和共享之间的关系。最后,社区建设和用户参与度的提升是项目成功的关键,如何通过有效的社区活动和激励机制吸引和维持用户的活跃度,是Data4All需要持续关注和解决的问题。
常用场景
经典使用场景
在数据科学领域,Data4All(海纳百川)数据集的经典使用场景主要体现在其广泛的数据资源和强大的数据分析工具上。研究者和开发者可以利用该数据集进行多维度的数据分析,包括但不限于自然语言处理、搜索引擎优化和数据挖掘。通过其高效的数据存储和共享机制,Data4All支持大规模数据的快速处理和共享,极大地促进了跨领域的数据协作和创新。
解决学术问题
Data4All数据集在学术研究中解决了数据获取和处理的瓶颈问题。其开放的数据资源和强大的数据分析工具,使得研究人员能够更便捷地获取和处理大规模数据,从而推动了自然语言处理、数据挖掘和机器学习等领域的研究进展。此外,Data4All通过提供高质量的数据集和工具,有助于提升研究结果的可靠性和创新性,对学术界产生了深远的影响。
实际应用
在实际应用中,Data4All数据集被广泛用于企业数据分析、市场研究和智能系统开发等领域。企业可以利用该数据集进行市场趋势分析、用户行为预测和产品优化,从而提升决策的科学性和精准性。同时,Data4All的高效数据共享机制也促进了企业间的数据合作,推动了行业的整体进步和创新。
数据集最近研究
最新研究方向
在数据开放与共享的浪潮中,Data4All(海纳百川)数据集凭借其庞大的数据资源和先进的分布式架构,正引领着新一代AI应用的创新研究。当前,该数据集的前沿研究主要集中在如何高效整合和处理多源异构数据,以提升AI模型的泛化能力和跨领域适应性。此外,随着全球对数据隐私和安全的日益关注,Data4All也在探索如何在保障数据安全的前提下,实现数据的广泛共享与协作。这些研究不仅推动了数据科学的发展,也为社会各领域的智能化转型提供了强有力的支持。
以上内容由遇见数据集搜集并总结生成


