enelpol/rag-mini-bioasq
收藏Hugging Face2024-06-27 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/enelpol/rag-mini-bioasq
下载链接
链接失效反馈官方服务:
资源简介:
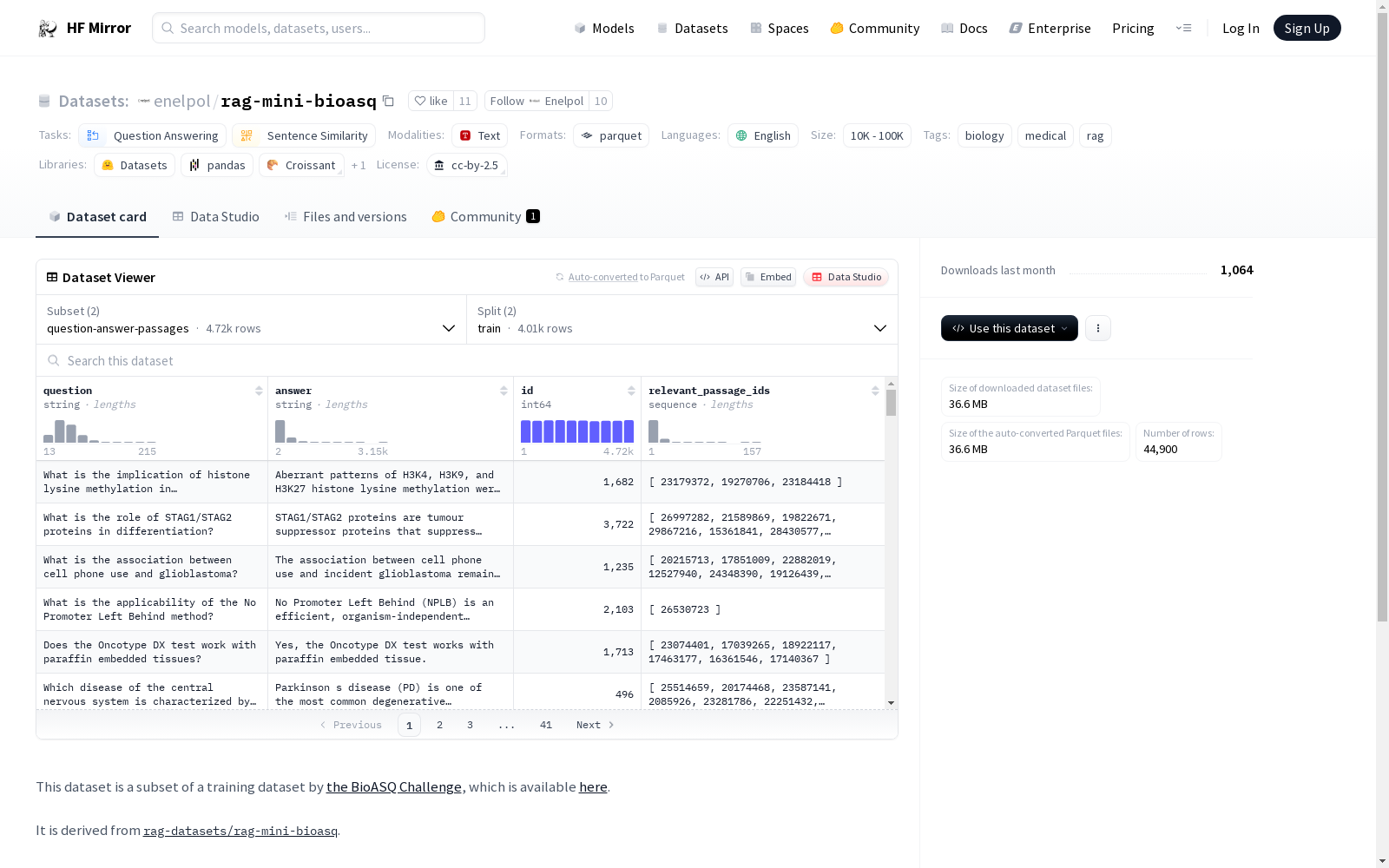
该数据集是BioASQ挑战赛训练数据集的一个子集,主要用于问答和句子相似性任务。数据集包含两个配置:question-answer-passages和text-corpus。question-answer-passages配置包含问题、答案、ID和相关段落ID,分为训练集和测试集;text-corpus配置包含段落和ID,仅包含测试集。数据集经过了一些修改,包括填补缺失的段落、更改相关段落ID的类型、去重段落并修正相关段落ID,以及将问答段落三元组分为训练集和测试集。
This dataset is a subset of the BioASQ Challenge training dataset, primarily utilized for question answering and sentence similarity tasks. It comprises two configurations: question-answer-passages and text-corpus. The question-answer-passages configuration includes questions, answers, IDs, and relevant passage IDs, and is split into training and test sets; the text-corpus configuration consists of passages and IDs, and only contains a test set. The dataset has undergone several revisions, including filling in missing passages, adjusting the data type of relevant passage IDs, deduplicating passages and correcting relevant passage IDs, as well as splitting the question-answer-passage triples into training and test sets.
提供机构:
enelpol
原始信息汇总
数据集概述
数据集配置
配置一:question-answer-passages
- 特征:
question:字符串类型answer:字符串类型id:64位整数类型relevant_passage_ids:64位整数序列类型
- 分割:
train:包含4719个样本,占用1900746字节
- 下载大小:1280794字节
- 数据集大小:1900746字节
- 数据文件:
train:路径为question-answer-passages/train-*
配置二:text-corpus
- 特征:
passage:字符串类型id:64位整数类型
- 分割:
train:包含40221个样本,占用60184778字节
- 下载大小:35288127字节
- 数据集大小:60184778字节
- 数据文件:
train:路径为text-corpus/train-*
其他信息
- 许可证:cc-by-2.5
- 任务类别:
- 问答
- 句子相似度
- 语言:英语
- 标签:
- 生物学
- 医学
- rag
搜集汇总
数据集介绍
构建方式
enelpol/rag-mini-bioasq数据集的构建基于BioASQ挑战的训练数据子集,通过填充缺失的段落、修改数据类型、去重段落以及将QAP三元组拆分为训练集和测试集等步骤,形成了结构化的问题、答案和相关信息的数据集。
使用方法
使用该数据集时,用户可以从HuggingFace平台下载所需的数据配置文件,并根据数据集的结构,分别对问题回答和文本相似度任务进行训练和测试。数据集的每一部分均通过特定的路径进行标识,方便用户进行数据加载和处理。
背景与挑战
背景概述
enelpol/rag-mini-bioasq数据集,作为BioASQ挑战训练数据集的一个子集,旨在为自然语言处理领域的研究者提供一份专注于生物医学问答和句子相似度任务的资源。该数据集的创建,基于BioASQ挑战这一由国际生物医学文本挖掘社区所发起的年度竞赛,自推出以来,它便成为了评估和提升生物医学信息检索与处理算法的重要基准。数据集的核心研究问题聚焦于如何提高机器对生物医学领域专业问题的理解和回答能力,其研究成果对于推动该领域的信息化进程具有显著影响力。
当前挑战
数据集构建过程中,研究者面临了多重挑战。首先,数据集中存在缺失的文本段落,这要求研究者在数据处理阶段进行填补。其次,原始数据中的`relevant_passage_ids`字段数据类型错误,需要进行转换和修正。此外,数据集中存在重复段落,需进行去重处理,并更新相关的问答三元组中的`relevant_passage_ids`,以保证数据的一致性和准确性。在研究领域问题上,数据集需要解决如何精确识别和抽取生物医学文本中的相关信息,以及如何有效地将这些问题与先前的知识相联系,从而实现高质量的问答匹配。
常用场景
经典使用场景
在生物医学领域,enelpol/rag-mini-bioasq数据集被广泛用于问题回答和句子相似性任务。其经典的使用场景在于,通过训练该数据集,研究者能够构建出能够理解生物医学文献内容,并针对特定问题提供准确答案的人工智能模型。
解决学术问题
该数据集有效地解决了学术研究中,如何从海量的生物医学文献中提取关键信息,以及如何快速准确地回答与生物医学相关的专业问题的挑战。它为生物医学信息检索和自然语言处理领域的研究提供了重要支持。
实际应用
在实际应用中,enelpol/rag-mini-bioasq数据集的应用场景包括但不限于生物医学研究人员的文献检索、医学教育中的问答系统,以及为临床决策提供数据支持的智能系统。
数据集最近研究
最新研究方向
在生物医学领域,enelpol/rag-mini-bioasq数据集作为BioASQ挑战的训练数据子集,正被广泛应用于问题回答和句子相似性任务。近期研究聚焦于提升自然语言处理模型在生物医学文献理解方面的能力,特别是在处理复杂医学问题和检索相关文本段落上。该数据集的优化和细分,为探索模型在理解生物医学概念、语义检索以及提供精确答案方面的前沿技术提供了重要资源,对提升医疗信息处理自动化水平具有显著影响。
以上内容由遇见数据集搜集并总结生成


