depinwang/rnaseq-aligner-toy-benchmark-metrics-v2-subjsweep
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/depinwang/rnaseq-aligner-toy-benchmark-metrics-v2-subjsweep
下载链接
链接失效反馈官方服务:
资源简介:
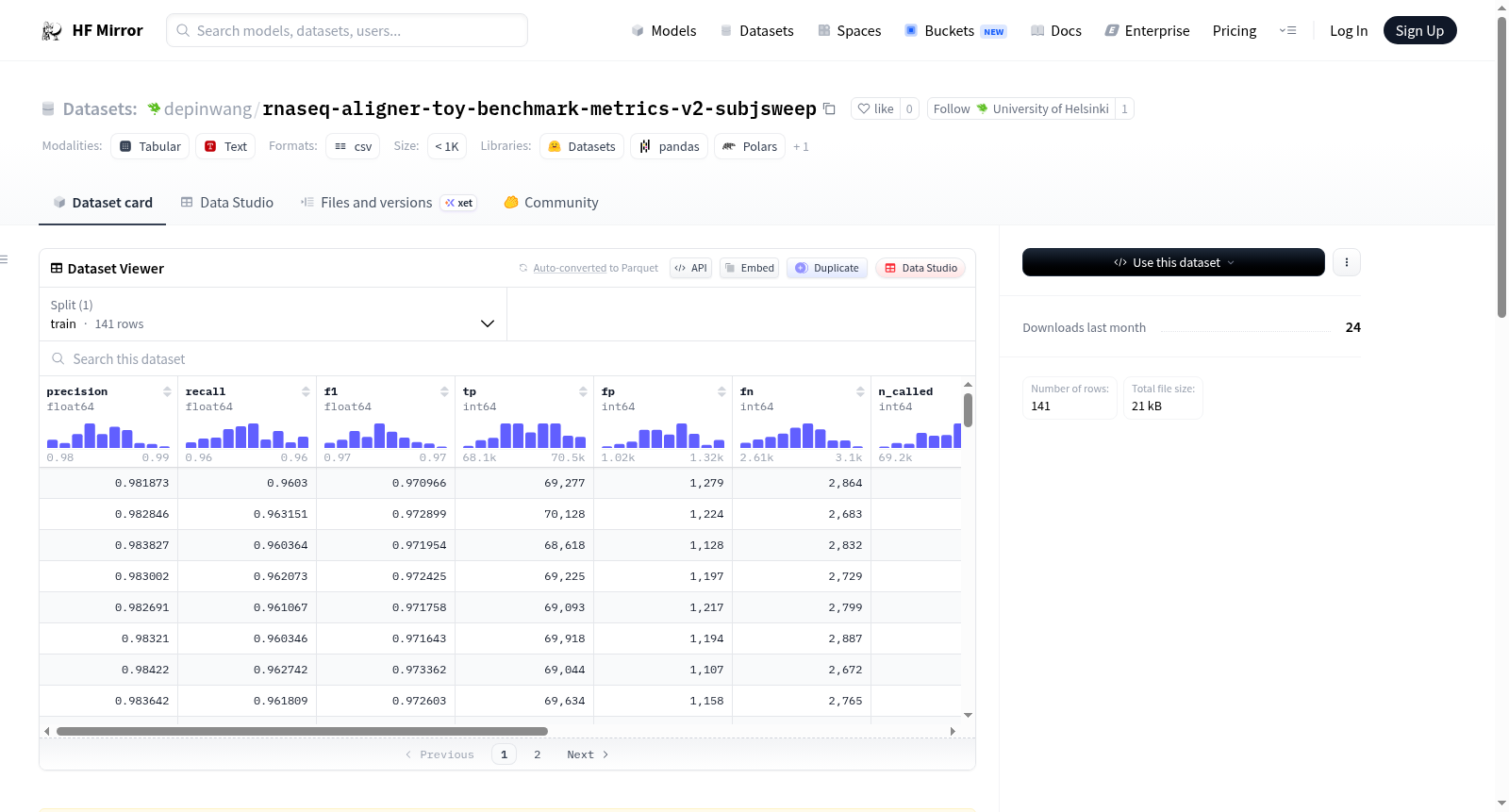
该数据集是一个RNA-seq比对工具性能评估数据集,针对模拟的GRCh38 RNA-seq读取,使用GENCODE v45转录本的真实内含子作为基准,评估了不同比对工具(star、hisat2、subjunc、bwa-mem2、minimap2)在剪接连接点检测上的性能。数据集包含141行数据,每行数据包括比对工具名称、样本ID、数据集标识符、精确度、召回率、F1分数、真阳性、假阳性、假阴性、调用的连接点总数、真实连接点总数以及应用的读取支持过滤器等信息。
This dataset is an RNA-seq aligner benchmark metrics dataset, evaluating the performance of different aligners (star, hisat2, subjunc, bwa-mem2, minimap2) on simulated GRCh38 RNA-seq reads against ground-truth introns from GENCODE v45 transcripts. The dataset contains 141 rows, each representing an (aligner, sample) combination and providing metrics such as splice-junction F1 score, precision, recall, true positives, false positives, false negatives, total junctions called, total junctions in ground-truth, and the read-support filter applied.
提供机构:
depinwang
搜集汇总
数据集介绍
构建方式
该数据集源于对五种主流RNA-seq比对工具(STAR、HISAT2、Subjunc、BWA-MEM2、Minimap2)在模拟GRCh38转录组测序读段上的系统评估。通过均匀采样GENCODE v45注释的转录本生成模拟读段,并采用无误差模型确保基准测试的纯净性。比对结果中提取的外显子-内含子连接位点与真实注释进行严格比对,以精确元组匹配策略计算剪接连接点层面的性能指标,最终构建出包含141条记录的综合评估矩阵。
特点
数据集以比对工具与样本为双重索引,系统记录了精准率、召回率及F1分数三项核心评价指标,并涵盖真假阳性计数、总连接位点数等辅助统计量。特别引入最小读段支持阈值(min_reads=3)作为过滤条件,确保连接位点检测的可靠性。数据来源清晰可溯,依托芬兰CSC的Puhti超级计算集群完成全流程模拟与计算,保证了结果的规范性和可重复性。
使用方法
用户可直接加载该表格化数据集,按比对工具分组汇总各样本的性能指标,快速评估不同工具在剪接连接点检测上的优劣。亦可筛选特定样本或数据集标识后,对精准率与召回率进行深入图谱分析,或利用真假阳性计数进一步计算自定义指标。该数据集适用于RNA-seq比对算法开发中的基准测试、工具选型以及剪接检测敏感度的比较研究。
背景与挑战
背景概述
该数据集创建于高性能计算集群Puhti(CSC)环境下,由研究团队针对RNA-seq比对器的性能评估需求而设计。核心研究问题聚焦于不同比对工具在剪接位点识别上的精确度与完整性,通过与GENCODE v45数据库中的真实内含子数据进行对比,以F1分数、精确率和召回率为指标量化其表现。该数据集汇集了STAR、HISAT2、Subjunc、BWA-MEM2和Minimap2五种主流比对器在141个样本上的测试结果,为RNA-seq数据分析工具的标准化评估提供了基准资源,对推动转录组学研究中比对算法的优化与选择具有重要参考价值。
当前挑战
领域层面,RNA-seq比对面临剪接位点精确识别的核心挑战,尤其是可变剪接事件中内含子边界的准确判定,以及低表达转录本或高噪声数据集中的假阳性与假阴性平衡问题。构建过程中,挑战在于模拟数据的真实性:该数据集使用均匀采样的转录本且未引入错误模型,可能无法完全反映真实测序中的技术偏差与生物学复杂性。此外,不同比对器对读段支持阈值(min_reads=3)的敏感性差异,以及GRCh38参考基因组中重复区域与多态性位点带来的比对歧义,均增加了基准测试构建的难度。
常用场景
经典使用场景
在转录组学研究中,RNA测序数据的比对是解析基因表达与剪接机制的核心步骤。该数据集专为评估比对工具在剪接位点识别上的性能而设计,其经典使用场景涵盖了对STAR、HISAT2、Subjunc、BWA-MEM2及Minimap2等主流比对器在模拟GRCh38 RNA-seq读段上的基准测试。通过精确率、召回率与F1分数的多维度指标,研究者可系统比较不同工具对剪接连接的检测能力,尤其聚焦于最小读段支持阈值(如min_reads=3)下的表现差异,为选择最佳比对策略提供量化依据。
衍生相关工作
该数据集催生了一系列围绕剪接比对评测的经典衍生工作。一方面,它成为多项比对器对比研究的标准化测试床,诸如后续工作在其基础上引入更复杂的测序错误模型或转录本丰度不均一性,扩展了性能评估的维度。另一方面,测评结果的涌现促使研究者开发了针对剪接连接精度的统计校正方法,如基于该数据集的F1分布特征设计加权投票策略,以融合多比对器优势。此外,该基准框架被借鉴用于非模式生物中的RNA-seq比对优化,以及长读段测序数据(如PacBio、ONT)的剪接评估,形成了从方案到泛化应用的研究链条,深刻影响了转录组学方法学的演进方向。
数据集最近研究
最新研究方向
该数据集聚焦于RNA-seq比对工具在剪接接合点检测上的性能评估,围绕GRCh38参考基因组与GENCODE v45注释展开,通过精确率、召回率及F1分数等指标,系统比较了STAR、HISAT2、Subjunc、bwa-mem2及minimap2等主流比对器的表现。这一工作顺应了转录组学研究中精准剪接事件解析的前沿需求,尤其在癌症转录组异常剪接与罕见病致病机制的探索中具有关键意义。通过统一模拟数据与标准化评估流程,该数据集为优化比对算法、提升可变剪接检测的灵敏度与特异性提供了可靠的基准,助力推动精准医学与功能基因组学的发展。
以上内容由遇见数据集搜集并总结生成


