有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
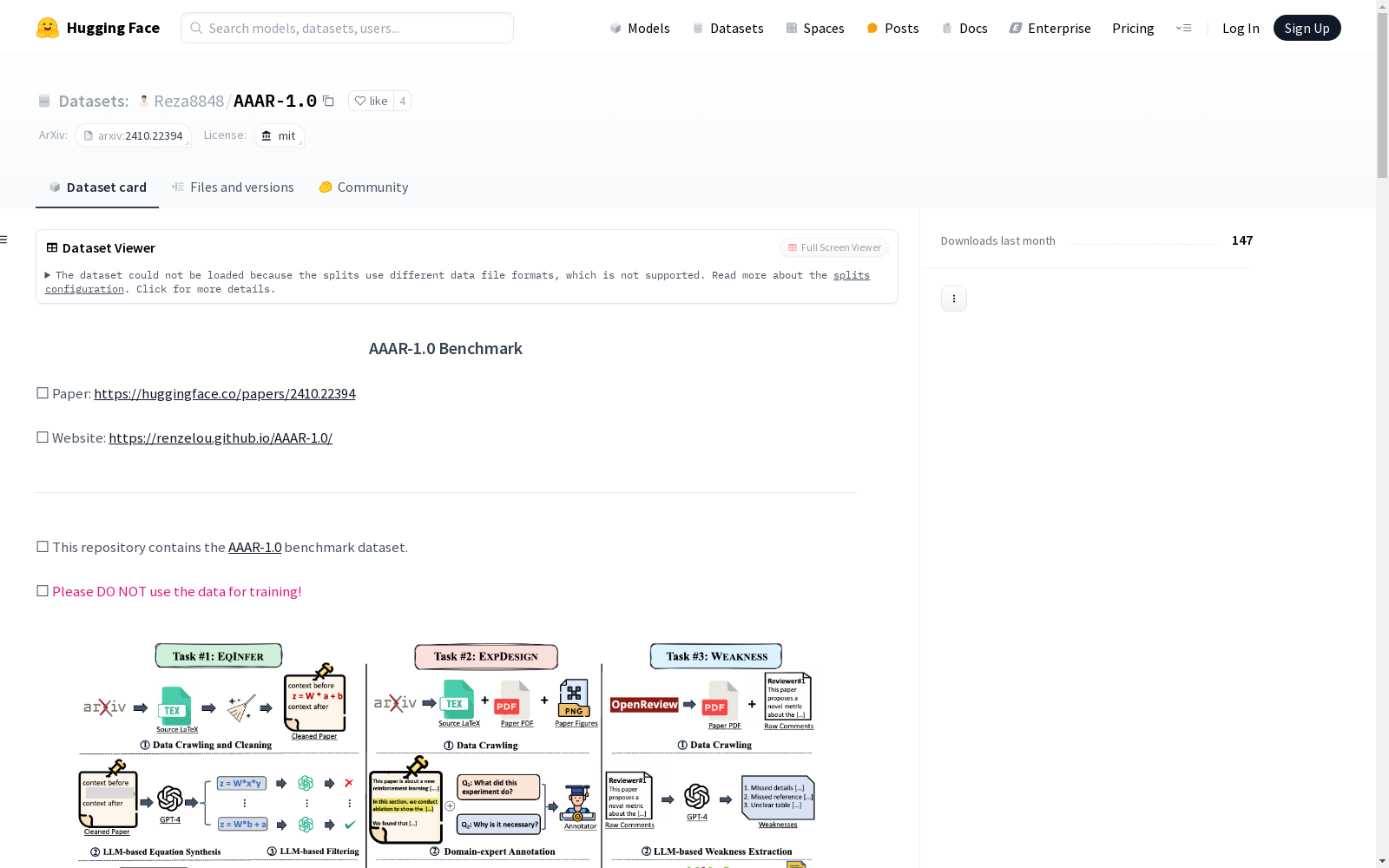
Equation_Inference/equation.1049.jsoncontext_before: 输入,目标方程前的论文上下文。context_after: 输入,目标方程后的论文上下文。options: 输入,四个候选方程(1个正确,3个错误)。answer: 输出,正确的方程。Experiment_Designdata_text.json: 包含所有论文上下文(输入)和目标实验列表及解释(输出)。images: 包含该论文的所有源图像(从arXiv源包中提取)。*_source.tar.gz: 该论文的arXiv源包。Paper_Weakness/ICLR_2023data_text.json: 包含所有论文上下文(输入)和目标弱点(输出)。images: 包含该论文的所有图表图像(从论文PDF中提取)。bibtex @article{Lou2024AAAR, title={{AAAR-1.0}: Assessing AIs Potential to Assist Research}, author={Renze Lou and Hanzi Xu and Sijia Wang and Jiangshu Du and Ryo Kamoi and Xiaoxin Lu and Jian Xie and Yuxuan Sun and Yusen Zhang and Jihyun Janice Ahn and Hongchao Fang and Zhuoyang Zou and Wenchao Ma and Xi Li and Kai Zhang and Congying Xia and Lifu Huang and Wenpeng Yin}, journal={arXiv preprint arXiv:2410.22394}, year={2024} }
中国逐日格点降水数据集V2(1960–2024,0.1°)
CHM_PRE V2数据集是一套高精度的中国大陆逐日格点降水数据集。该数据集基于1960年至今共3476个观测站的长期日降水观测数据,并纳入11个降水相关变量,用于表征降水的相关性。数据集采用改进的反距离加权方法,并结合基于机器学习的LGBM算法构建。CHM_PRE V2与现有的格点降水数据集(包括CHM_PRE V1、GSMaP、IMERG、PERSIANN-CDR和GLDAS)表现出良好的时空一致性。数据集基于63,397个高密度自动雨量站2015–2019年的观测数据进行验证,发现该数据集显著提高了降水测量精度,降低了降水事件的高估,为水文建模和气候评估提供了可靠的基础。CHM_PRE V2 数据集提供分辨率为0.1°的逐日降水数据,覆盖整个中国大陆(18°N–54°N,72°E–136°E)。该数据集涵盖1960–2024年,并将每年持续更新。日值数据以NetCDF格式提供,为了方便用户,我们还提供NetCDF和GeoTIFF格式的年度和月度总降水数据。
国家青藏高原科学数据中心 收录
OpenSonarDatasets
OpenSonarDatasets是一个致力于整合开放源代码声纳数据集的仓库,旨在为水下研究和开发提供便利。该仓库鼓励研究人员扩展当前的数据集集合,以增加开放源代码声纳数据集的可见性,并提供一个更容易查找和比较数据集的方式。
github 收录
IVLLab/MultiDialog
该数据集包含手动注释的元数据,将音频文件与转录、情感和其他属性链接起来。数据集支持多种任务,包括多模态对话生成、自动语音识别和文本到语音转换。数据集的语言为英语,并提供了一个黄金情感对话子集,用于研究对话中的情感动态。数据集的结构包括音频文件、对话ID、话语ID、来源、音频特征、转录文本、情感标签和原始路径等信息。
hugging_face 收录
红外谱图数据库
收集整理红外谱图实验手册等数据,建成了红外谱图数据库。本数据库收录了常见化合物的红外谱图。主要包括化合物数据和对应的红外谱图数据。其中,原始红外谱图都进行了数字化处理,从而使谱峰检索成为可能。用户可以在数据库中检索指定化合物的谱图,也可以提交谱图/谱峰数据,以检索与之相似的谱图数据,以协助进行谱图鉴定。
国家基础学科公共科学数据中心 收录
QM9
QM9数据集包含134k个有机小分子化合物的量子化学计算结果,涵盖了12个量子化学性质,如分子能量、电离能、电子亲和能等。
quantum-machine.org 收录