AAAR-1.0
收藏Hugging Face2024-11-08 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Reza8848/AAAR-1.0
下载链接
链接失效反馈官方服务:
资源简介:
AAAR-1.0数据集包含四个主要任务:方程推理、实验设计、论文弱点和评审评论。方程推理任务包含1049个样本,每个样本有四个字段:前文、后文、选项和答案。实验设计任务包含100篇论文,每篇论文包含文本数据和图像数据。论文弱点任务包含993篇论文,每篇论文包含文本数据和图像数据。评审评论任务的数据存储在另一个GitHub仓库中。
创建时间:
2024-10-31
原始信息汇总
AAAR-1.0 数据集概述
基本信息
- 数据集名称: AAAR-1.0
- 许可证: MIT
- 论文链接: AAAR-1.0 论文
- 官方网站: AAAR-1.0 官方网站
数据集内容
1. 方程推理 (Equation Inference)
- 文件路径:
Equation_Inference/equation.1049.json - 样本数量: 1,049
- 字段说明:
context_before: 输入,目标方程前的论文上下文。context_after: 输入,目标方程后的论文上下文。options: 输入,四个候选方程(1个正确,3个错误)。answer: 输出,正确的方程。
2. 实验设计 (Experiment Design)
- 文件路径:
Experiment_Design - 样本数量: 100篇论文
- 数据结构:
- 每个论文数据存储在一个以论文ID命名的子文件夹中。
- 每个论文包含以下数据源:
data_text.json: 包含所有论文上下文(输入)和目标实验列表及解释(输出)。images: 包含该论文的所有源图像(从arXiv源包中提取)。*_source.tar.gz: 该论文的arXiv源包。
3. 论文弱点 (Paper Weakness)
- 文件路径:
Paper_Weakness/ICLR_2023 - 样本数量: 993篇论文
- 数据结构:
- 每个论文数据存储在一个以论文ID命名的子文件夹中。
- 每个论文包含以下数据源:
data_text.json: 包含所有论文上下文(输入)和目标弱点(输出)。images: 包含该论文的所有图表图像(从论文PDF中提取)。
4. 评审评论 (Review Critique)
- 数据存储: 该任务的数据存储在 GitHub 仓库 中。
引用
bibtex @article{Lou2024AAAR, title={{AAAR-1.0}: Assessing AIs Potential to Assist Research}, author={Renze Lou and Hanzi Xu and Sijia Wang and Jiangshu Du and Ryo Kamoi and Xiaoxin Lu and Jian Xie and Yuxuan Sun and Yusen Zhang and Jihyun Janice Ahn and Hongchao Fang and Zhuoyang Zou and Wenchao Ma and Xi Li and Kai Zhang and Congying Xia and Lifu Huang and Wenpeng Yin}, journal={arXiv preprint arXiv:2410.22394}, year={2024} }
搜集汇总
数据集介绍
构建方式
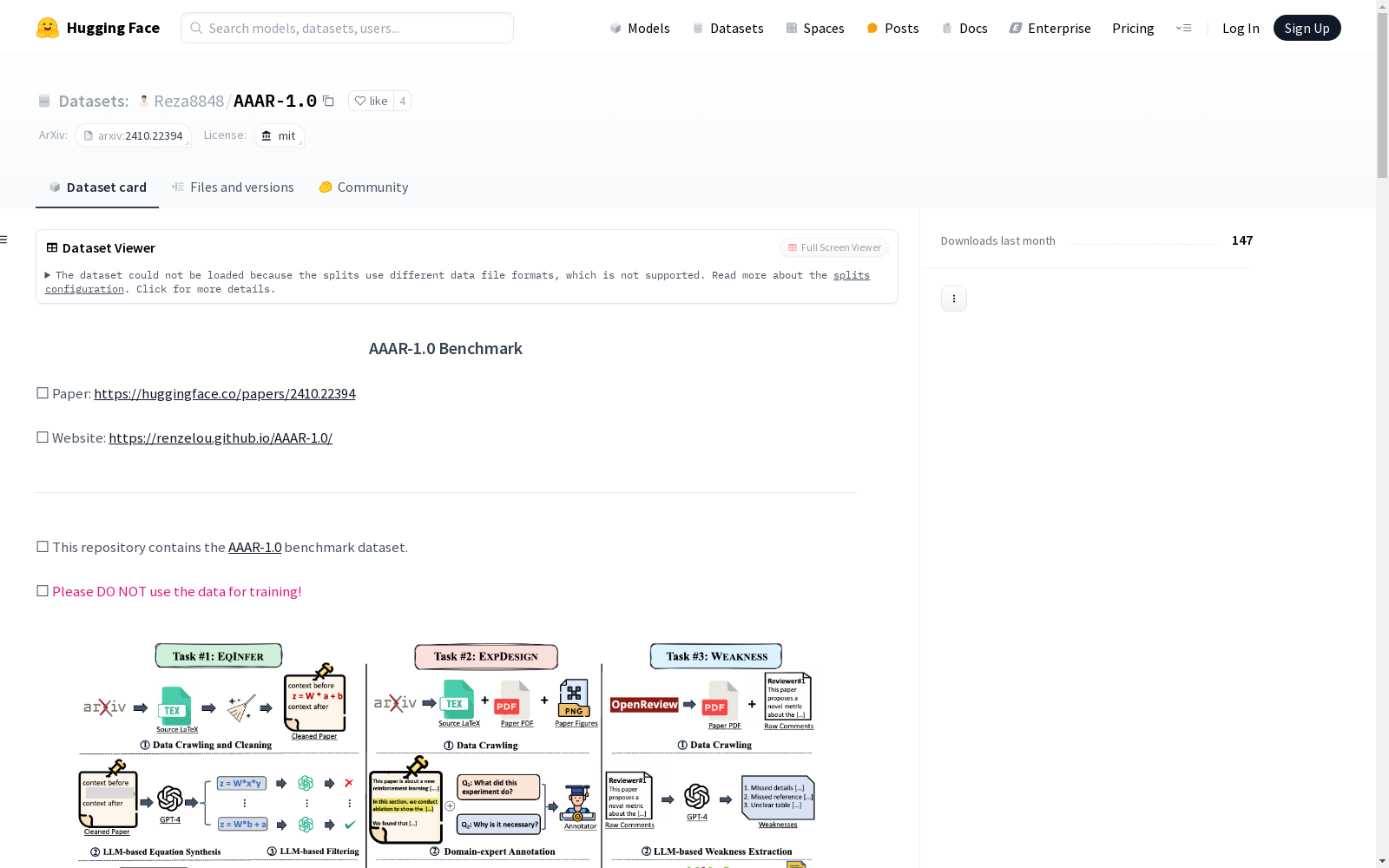
AAAR-1.0数据集的构建基于对科研论文的深度分析与提取,涵盖了方程推理、实验设计、论文弱点识别以及评审批判等多个任务。数据集从arXiv等公开资源中获取论文内容,并通过人工标注与自动化工具相结合的方式,提取出关键信息。每个任务的数据均以结构化JSON格式存储,确保数据的可读性与可扩展性。方程推理任务包含1049个样本,实验设计任务涉及100篇论文,论文弱点识别任务则涵盖了993篇论文,评审批判任务的数据则单独存放在GitHub仓库中。
特点
AAAR-1.0数据集的特点在于其多任务性与高复杂性,涵盖了科研论文中的多个关键环节。数据集不仅提供了丰富的上下文信息,还包含了图像、源代码等多媒体数据,为研究者提供了全面的研究素材。方程推理任务通过提供上下文与候选方程,评估模型的理解能力;实验设计任务则要求模型从论文中提取实验设计与解释;论文弱点识别任务则聚焦于发现论文中的潜在问题。评审批判任务则进一步扩展了数据集的适用范围,使其能够用于评估模型在论文评审中的表现。
使用方法
AAAR-1.0数据集的使用方法主要围绕其多任务特性展开。研究者可以通过GitHub仓库获取详细的代码与运行指南,评估不同大语言模型在各项任务中的表现。方程推理任务通过JSON文件提供上下文与候选方程,研究者需训练模型从中选择正确答案;实验设计任务则要求模型从论文中提取实验设计与解释,并生成相应的输出;论文弱点识别任务则通过分析论文内容,识别其中的潜在问题。评审批判任务的数据单独存放,研究者需参考相关论文与GitHub仓库获取详细信息。数据集的使用需遵循MIT许可协议,且明确禁止用于训练目的。
背景与挑战
背景概述
AAAR-1.0基准数据集由Renze Lou等人于2024年发布,旨在评估人工智能在辅助科学研究中的潜力。该数据集由多个任务组成,包括方程推理、实验设计、论文弱点分析和评审批判,涵盖了科学研究中的关键环节。数据集的核心研究问题在于如何通过人工智能技术提升科研效率与质量,特别是在复杂科学文献的理解与生成方面。AAAR-1.0的发布为自然语言处理领域提供了新的研究方向,推动了AI在学术研究中的应用。
当前挑战
AAAR-1.0数据集在解决科学文献理解与生成的复杂问题时面临多重挑战。首先,科学文献通常包含高度专业化的术语和复杂的逻辑结构,这对模型的语义理解能力提出了极高要求。其次,实验设计任务需要模型具备跨学科的知识整合能力,而现有模型在处理多领域知识时仍存在局限性。此外,数据集的构建过程也面临挑战,包括如何从大量科学文献中提取高质量的任务数据,并确保数据的多样性与代表性。这些挑战不仅考验了模型的性能,也对数据集的构建方法提出了更高要求。
常用场景
经典使用场景
AAAR-1.0数据集在学术研究领域中被广泛用于评估大型语言模型(LLMs)在科研辅助任务中的表现。该数据集包含方程推理、实验设计、论文弱点分析和评审批评等多个任务,旨在全面测试模型在复杂学术场景中的理解和推理能力。研究人员通过该数据集能够深入分析模型在处理科学文献时的准确性和效率,从而推动LLMs在科研辅助领域的发展。
实际应用
在实际应用中,AAAR-1.0数据集被用于开发智能科研辅助工具,帮助研究人员快速理解复杂文献中的关键信息。例如,在方程推理任务中,模型可以辅助识别和验证科学论文中的数学公式;在实验设计任务中,模型能够提供实验方案的优化建议。这些应用显著提高了科研工作的效率,减轻了研究人员的负担。
衍生相关工作
AAAR-1.0数据集衍生了一系列相关研究工作,特别是在LLMs与科研辅助领域的交叉研究中。例如,基于该数据集的研究提出了新的模型评估方法,进一步优化了模型在科学文献处理中的表现。此外,该数据集还激发了更多关于科研自动化工具的开发,推动了人工智能在科研领域的深入应用。
以上内容由遇见数据集搜集并总结生成


