Carousel
收藏arXiv2025-11-07 更新2025-11-13 收录
下载链接:
https://github.com/RafeLoya/carousel
下载链接
链接失效反馈官方服务:
资源简介:
Carousel数据集是由贝勒大学研究人员创建的高分辨率多目标自动图像裁剪数据集。数据集包含277张高分辨率图像,每张图像都至少有两个显著的感兴趣区域,并且具有高美学质量。数据集的平均分辨率为10.58MP,远高于现有的单目标数据集。数据集的标签由人类专家进行标注,使用AnyLabeling平台进行标注,标注内容包括2:3和3:2的固定宽高比。该数据集旨在解决多目标自动图像裁剪问题,并为社交媒体用户提供更高质量的图像浏览体验。
The Carousel dataset is a high-resolution multi-object automatic image cropping dataset developed by researchers at Baylor University. It contains 277 high-resolution images, each featuring at least two salient regions of interest and possessing high aesthetic quality. The average resolution of the dataset reaches 10.58 MP, which is considerably higher than that of existing single-object datasets. The annotations for this dataset were completed by human experts via the AnyLabeling platform, with the fixed cropping aspect ratios set as 2:3 and 3:2. This dataset is designed to address the challenge of multi-object automatic image cropping and provide higher-quality image browsing experiences for social media users.
提供机构:
贝勒大学
创建时间:
2025-11-07
原始信息汇总
Carousel 数据集概述
数据集简介
Carousel 是一个包含 277 张图像的高分辨率数据集,每张图像包含两个或多个显著区域,平均分辨率为 10.58 MP。该数据集专为多目标自动图像裁剪研究设计,旨在通过最小用户输入从单张照片中生成多个裁剪区域。
数据组织结构
原始数据目录 (./dataset)
- 包含原始图像文件及配套元数据文件
- 文件命名结构:
image.jpeg- 原始图像image.json- 包含标签坐标、图像高度和宽度等信息image_metadata.json- 包含以下元数据:website_url- 图像直接访问链接subcrops- 应从图像中导出的裁剪数量,也表示显著区域数量title- 图像来源标题creator- 图像创作者copyright_license_type- 版权许可类型
分区数据目录 (./partitions)
-
包含按显著区域划分的图像子区域
-
目录结构:
partitions/image/ ├── image_{aspect_ratio}partition_1.jpg ├── ... ├── image{aspect_ratio}partition{k}.jpg └── partition_info.json
-
partition_info.json文件记录:original_filename- 源图像文件名aspect_ratio_chosen- 显著分区算法使用的宽高比(3:2 或 2:3)num_partitions- 分区数量(反映subcrops字段)orientation- 分区方向(垂直沿x轴分区,反之亦然)partition_files- 为源图像生成的每个分区文件名
异常文件
hard_failures.txt- 列出分区过程中不成功的图像,这些图像通常包含极端宽高比的分区或切分显著区域
数据来源
- 图像来源于 Wikimedia Commons、Flickr 和 Rawpixel
- 所有图像均采用开放、非商业许可分发
搜集汇总
数据集介绍
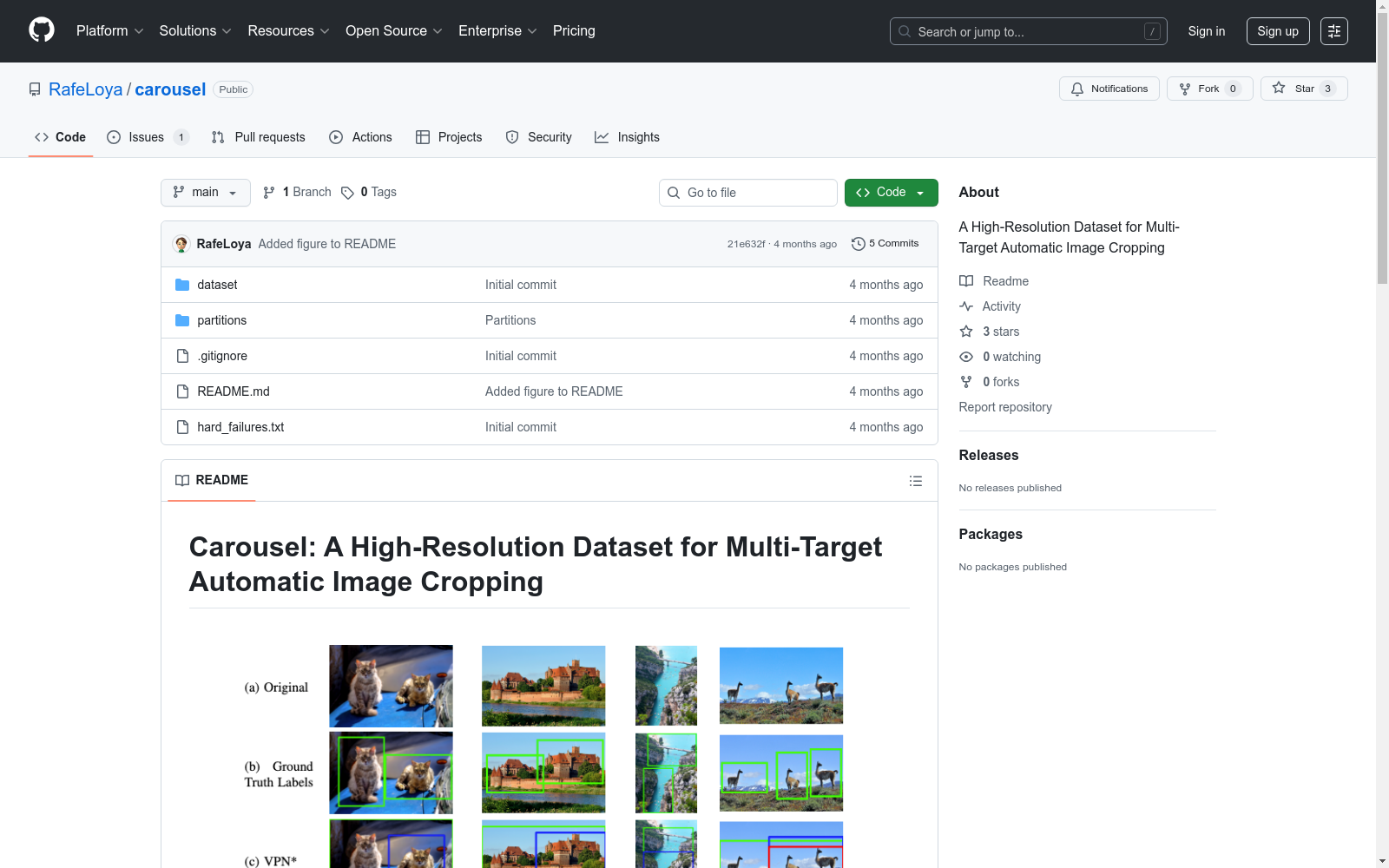
构建方式
在计算机视觉领域,高分辨率图像处理需求日益增长,Carousel数据集通过系统化流程构建而成。研究团队从Wikimedia Commons、Flickr等开放平台筛选具备多重显著区域的图像,严格执行每幅图像不低于1MP的分辨率标准,并确保图像包含至少两个独立显著性区域。专业标注人员采用改进的AnyLabeling工具,依据经典摄影构图原则对2:3与3:2两种长宽比进行边界框标注,最终形成包含277幅平均分辨率达10.58MP的图像集合。
特点
针对现有裁剪数据集分辨率不足的局限,Carousel展现出三大核心特征。其图像平均分辨率超过千万像素,较传统数据集提升一个数量级,为细节保留提供坚实基础;每幅图像均包含多个非重叠的显著性区域标注,突破单目标裁剪的数据范式;标注数据严格遵循专业摄影构图法则,同时提供完整的元数据信息,为多目标美学裁剪研究建立新的基准。
使用方法
该数据集为多目标自动裁剪算法评估提供标准化框架。研究者可通过解析配套JSON文件获取标注边界框与元数据,利用多区域显著性分割算法对图像进行预处理,将复杂场景划分为独立子区域。评估时采用创新的Top-k IoU指标,通过贪心二分匹配策略计算预测裁剪与真实标注的空间重合度,现有实验表明结合分区预处理的GAICv2模型在该任务中表现最佳,为后续端到端多目标裁剪模型研发提供重要参照。
背景与挑战
背景概述
随着社交媒体平台对高分辨率图像处理需求的日益增长,贝勒大学研究团队于2025年推出了Carousel数据集,专门针对多目标自动图像裁剪这一新兴研究方向。该数据集包含277张平均分辨率达10.58兆像素的高质量图像,每张图像均包含多个显著区域的人工标注边界框。其核心研究目标在于解决传统单目标裁剪模型在处理包含多个独立兴趣主体的复杂场景时的局限性,通过引入多区域显著性分割算法,为开发能够同时生成多个美学裁剪结果的智能系统提供了重要基准。
当前挑战
在解决多目标图像裁剪的领域挑战方面,传统模型难以在保持美学质量的同时确保多个裁剪区域的独立性,常出现显著重叠或忽略次要主体的问题。构建过程中的技术挑战主要体现在高分辨率图像标注的复杂性,需要人工专家基于摄影构图原则对每个显著区域进行精确定位;同时,多区域分割算法在面对空间重叠的标注目标时容易产生失败案例,约16%的图像因分割质量不佳而被排除在评估集外。此外,数据采集还需平衡图像分辨率与标注成本之间的矛盾,确保每个裁剪区域既能保留细节信息又符合美学标准。
常用场景
经典使用场景
在计算机视觉领域,Carousel数据集主要应用于多目标自动图像裁剪技术的研究与评估。该数据集通过提供277张高分辨率图像及人工标注的裁剪边界框,为开发能够同时生成多个美学裁剪区域的算法奠定了坚实基础。研究人员利用该数据集训练和验证模型在复杂场景中识别多个显著区域的能力,确保每个裁剪区域既符合摄影构图原则,又能保持视觉上的独立性。
实际应用
在实际应用层面,Carousel数据集的技术成果可直接赋能社交媒体平台的图像展示体验。当用户上传高分辨率全景照片时,系统可自动生成多个聚焦不同主体的美学裁剪,形成可滑动浏览的图像序列。这种交互方式既保留了原始图像的细节信息,又避免了平台强制降分辨率导致的画质损失,特别适用于展示风景摄影、多人合影等多主体场景,显著提升了移动端用户的视觉体验。
衍生相关工作
基于Carousel数据集的研究催生了多区域显著性分割算法等创新方法。这些工作通过结合U2-Net生成的显著性图谱,实现了对图像中多个独立主体的精准定位与分割。后续研究进一步探索了端到端的多目标裁剪模型架构,避免了对预分割步骤的依赖。该数据集还促进了裁剪数量自适应确定、多尺度美学评估等方向的发展,为智能图像处理领域开辟了新的研究路径。
以上内容由遇见数据集搜集并总结生成


