ds4sd/PubTables-1M_OTSL
收藏Hugging Face2023-08-31 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ds4sd/PubTables-1M_OTSL
下载链接
链接失效反馈官方服务:
资源简介:
PubTables-1M-OTSL数据集用于评估对象检测模型和图像到文本的方法。该数据集基于PubTables-1M,并添加了OTSL(优化表格结构语言)格式。数据集包含原始注释和新添加的内容,结构包括单元格、表格边界框、OTSL格式、HTML格式等。OTSL是一种新的简化表格结构标记格式,包含特定的标记如fcel、ecel等。数据集分为训练、验证和测试三个部分。数据集由IBM Research的Deep Search团队转换。
PubTables-1M-OTSL数据集用于评估对象检测模型和图像到文本的方法。该数据集基于PubTables-1M,并添加了OTSL(优化表格结构语言)格式。数据集包含原始注释和新添加的内容,结构包括单元格、表格边界框、OTSL格式、HTML格式等。OTSL是一种新的简化表格结构标记格式,包含特定的标记如fcel、ecel等。数据集分为训练、验证和测试三个部分。数据集由IBM Research的Deep Search团队转换。
提供机构:
ds4sd
原始信息汇总
数据集卡片 for PubTables-1M_OTSL
数据集描述
数据集概述
该数据集支持对象检测模型和图像到文本方法的评估。PubTables-1M 是在 Smock 等人的论文《PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents》中引入的。该数据集包括原始注释以及新的 OTSL(优化表结构语言)格式。
数据集结构
cells: 原始数据集单元格标注(内容)。table_bbox: 原始数据集表格检测标注。otsl: 新的简化表结构标记格式。html: 生成的 HTML,以匹配 PubTabNet、FinTabNet 和 SynthTabNet 格式。html_restored: 从 OTSL 生成的 HTML。cols: 网格列长度。rows: 网格行长度。image: PIL 图像。
OTSL 词汇表
OTSL: 新的简化表结构标记格式 更多关于 OTSL 表结构格式及其概念的信息可以从我们的论文中阅读。该数据集的格式扩展了论文中提出的工作,并引入了轻微的修改:
fcel- 包含内容的单元格ecel- 空的单元格lcel- 向左看的单元格(处理水平合并的单元格)ucel- 向上看的单元格(处理垂直合并的单元格)xcel- 2D 跨度单元格,在该数据集中 - 覆盖合并单元格的整个区域nl- 新行标记
数据分割
该数据集提供三个分割:
trainvaltest
附加信息
数据集策展人
该数据集由 IBM Research 的 Deep Search 团队转换。 策展人:
- Maksym Lysak, @maxmnemonic
- Ahmed Nassar, @nassarofficial
- Christoph Auer, @cau-git
- Nikos Livathinos, @nikos-livathinos
- Peter Staar, @PeterStaar-IBM
引用信息
OTSL 论文引用:
@article{lysak2023optimized,
title={Optimized Table Tokenization for Table Structure Recognition},
author={Maksym Lysak and Ahmed Nassar and Nikolaos Livathinos and Christoph Auer and Peter Staar},
year={2023},
eprint={2305.03393},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
PubTables-1M 创建者引用:
@inproceedings{smock2022pubtables,
title={Pub{T}ables-1{M}: Towards comprehensive table extraction from unstructured documents},
author={Smock, Brandon and Pesala, Rohith and Abraham, Robin},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
pages={4634-4642},
year={2022},
month={June}
}
搜集汇总
数据集介绍
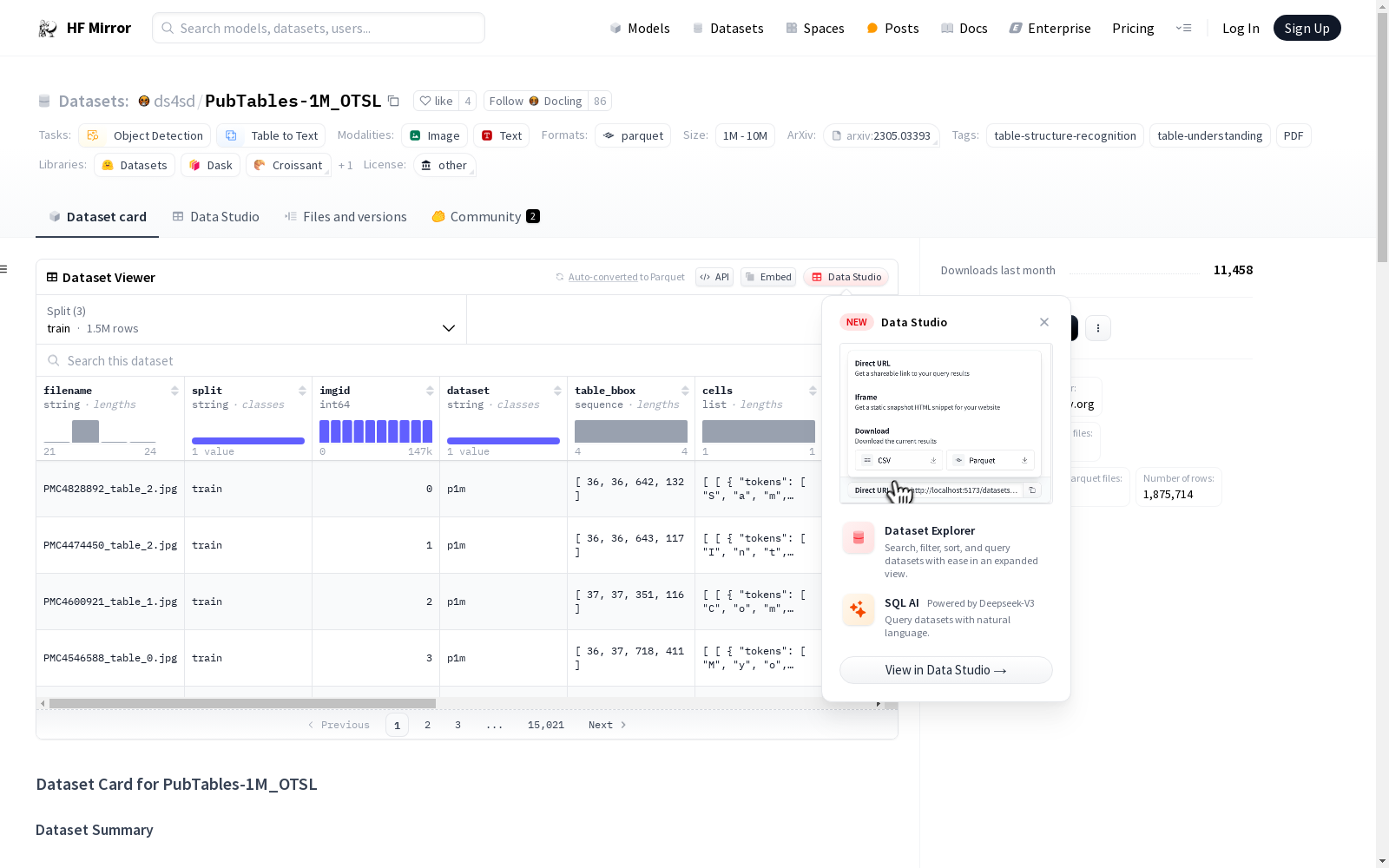
构建方式
PubTables-1M_OTSL数据集的构建,是在原有PubTables-1M数据集的基础上,通过引入Optimized Table Structure Language(OTSL)格式,对表格结构进行简化和优化。该数据集融合了原始数据集的标注信息,并新增了OTSL格式的标注,旨在为表格结构识别任务提供更为精确和高效的训练与评估资源。
特点
该数据集的主要特点在于其采用了OTSL格式,该格式通过使用特定的标记来描述表格的单元格结构和内容,有效减少了标注复杂性。此外,数据集提供了三种不同的划分(训练集、验证集和测试集),并包含了与PubTabNet、FinTabNet和SynthTabNet格式兼容的HTML文件,以便于不同模型之间的比较和评估。
使用方法
使用PubTables-1M_OTSL数据集时,用户可以依据其提供的不同数据格式,如OTSL、HTML以及原始的单元格和表格边界标注,进行模型训练和性能评估。数据集的划分使得研究者能够方便地进行模型的迭代和优化。此外,数据集的Homepage和Paper提供了详细的使用指南和相关研究背景,便于用户更好地理解和利用该数据集。
背景与挑战
背景概述
在表格结构识别与理解领域,PubTables-1M_OTSL数据集的构建标志着对表格数据自动处理能力的一次重要提升。该数据集由IBM Research的Deep Search团队于2023年推出,旨在通过提供大规模的表格检测与文本提取标注,促进相关技术的发展。核心研究问题是提升表格结构识别的准确性与效率,其研究成果已在计算机视觉与模式识别领域产生了显著影响。数据集的创建基于Smock等人的工作,并进一步由Lysak等人进行了优化与格式转换,引入了OTSL(Optimized Table Structure Language)以简化表格结构的表示方法。
当前挑战
PubTables-1M_OTSL数据集面临的挑战主要在于两个方面:一是领域问题上的挑战,即如何精确识别并提取文档中复杂的表格结构;二是构建过程中的挑战,包括如何高效地从PDF文档中提取表格,以及如何生成和转换OTSL格式标注。这些挑战不仅涉及到算法的精确度和鲁棒性,还包括了数据标注的准确性与一致性,以及大规模数据处理的技术难题。
常用场景
经典使用场景
在当前信息化时代,表格数据的自动化处理成为研究热点。PubTables-1M_OTSL数据集为此领域提供了丰富的资源,其经典使用场景在于评估对象检测模型和图像到文本方法的性能。通过对表格结构及内容的精准标注,该数据集支持研究者进行深入的表格结构识别和表格内容提取研究。
解决学术问题
该数据集解决了学术研究中表格提取自动化处理的关键问题,如表格检测、结构识别以及内容理解等。通过提供大规模且多样化的表格实例,PubTables-1M_OTSL数据集极大地推动了表格理解领域的发展,为相关算法的评估和优化提供了标准化基准。
衍生相关工作
该数据集衍生了多项相关工作,如表格结构识别、表格内容解析和表格信息可视化等。相关研究不仅深化了表格处理的理论基础,也推动了表格数据处理技术在多个领域的实际应用,为表格数据的智能化处理开辟了新的道路。
以上内容由遇见数据集搜集并总结生成


