mozzarella
收藏Hugging Face2024-07-18 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/feedback-to-code/mozzarella
下载链接
链接失效反馈官方服务:
资源简介:
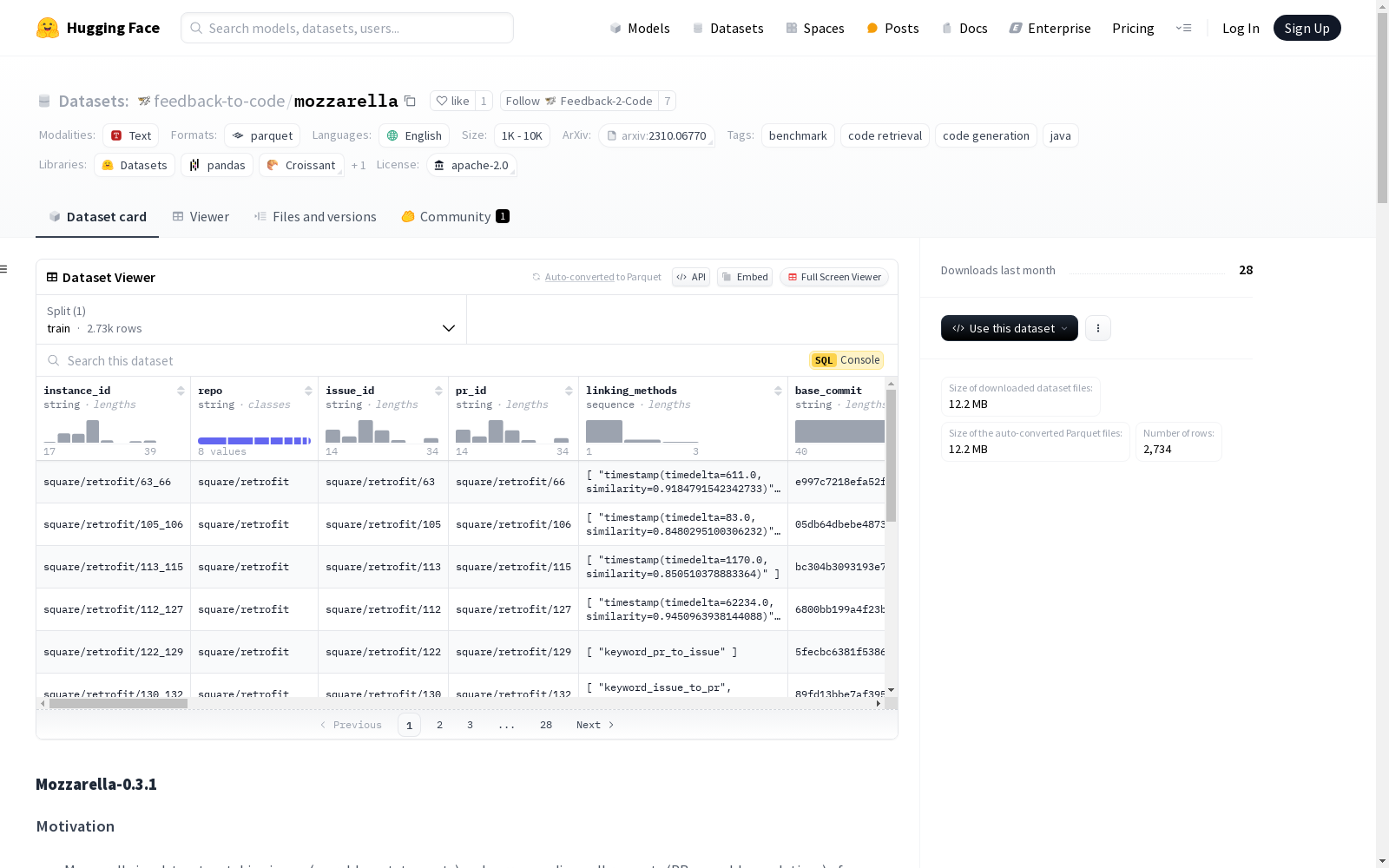
Mozzarella-0.3.1是一个数据集,旨在匹配高质量维护的Java GitHub仓库中的问题(问题陈述)和相应的拉取请求(PR,即问题解决方案)。该数据集最初用于训练和评估关注故障定位和自动化程序修复的机器学习模型。数据集包含2734个任务,来自8个仓库,每个任务包含问题和PR的相关信息,如ID、评论、问题陈述、解决方案等。数据集提供了三种不同的训练/验证/测试分割方式:随机分割、仓库分割和时间分割。数据集的收集过程涉及从GitHub API获取问题和PR信息,并使用多种链接方法(如连接、关键词、时间戳)来创建任务实例。数据预处理包括移除修改超过十个文件的任务和仅修改测试文件的任务。数据集目前用于训练和验证文件和方法级别的故障定位模型,以及自动代码生成/错误修复模型。
创建时间:
2024-07-18
原始信息汇总
Mozzarella-0.3.1 数据集概述
动机
- Mozzarella 数据集匹配问题陈述和相应的拉取请求(PR),来源于一些维护良好的 Java GitHub 仓库。初衷是为机器学习模型提供训练和评估数据,用于故障定位和自动化程序修复。
- 受 SWEBench 论文启发,该论文收集了类似的 Python 代码库数据(仅限于文件级别)。
作者
- Feedback2Code 本科项目,由 Hasso Plattner Institute, Potsdam 与 SAP 合作完成。
组成
- 每个实例称为一个任务,代表一个 GitHub 问题及其对应的修复匹配。每个任务包含问题/PR 的信息(ID、评论等)、问题陈述和人工开发者应用的解决方案,包括相关文件、相关方法和实际更改的代码。
- 数据集目前包含 2734 个任务,来自 8 个仓库。入选数据集的仓库必须主要使用 Java 编写,拥有大量英文问题和拉取请求,具有良好的测试覆盖率,并采用宽松的许可证。
- 数据集包含三种不同的训练/验证/测试拆分:
- 随机拆分:任务按 60/20/20 的比例随机拆分。
- 仓库拆分:按 60/20/20 的比例将仓库分配到训练/验证/测试集,任务跟随所属仓库的拆分。
- 时间拆分:测试集中的所有任务创建时间早于验证集,训练集中的所有任务创建时间早于测试集。
仓库
- mockito/mockito (MIT)
- square/retrofit (Apache 2.0)
- iluwatar/java-design-patterns (MIT)
- netty/netty (Apache 2.0)
- pinpoint-apm/pinpoint (Apache 2.0)
- kestra-io/kestra (Apache 2.0)
- provectus/kafka-ui (Apache 2.0)
- bazelbuild/bazel (Apache 2.0)
列信息
- instance_id: (str) - 任务/实例的唯一标识符。格式:username__reponame-issueid
- repo: (str) - GitHub 仓库的所有者/名称标识符。
- issue_id: (str) - 问题/问题的格式化标识符,通常为 repo_owner/repo_name/issue-number。
- pr_id: (str) - 对应 PR/解决方案的格式化实例标识符,通常为 repo_owner/repo_name/PR-number。
- linking_methods: (list str) - 创建此任务所使用的方法(例如时间戳、关键词...)。
- base_commit: (str) - 解决方案 PR 应用前的仓库 HEAD 提交哈希。
- merge_commit: (str) - PR 合并后的仓库 HEAD 提交哈希。
- hints_text: (str) - 问题上的评论。
- resolved_comments: (str) - PR 上的评论。
- created_at: (str) - 拉取请求的创建日期。
- labeled_as: (list str) - 应用于问题的标签列表。
- problem_statement: (str) - 问题标题和正文。
- gold_files: (list str) - PR 中更改的非测试文件路径列表(在 base commit 时)。
- test_files: (list str) - PR 中更改的测试文件路径列表(在 base commit 时)。
- gold_patch: (str) - 解决问题的黄金补丁,由 PR 生成的补丁(减去测试相关代码),作为 diff。
- test_patch: (str) - 解决方案 PR 贡献的测试文件补丁,作为 diff。
- split_random: (str) - 此任务所属的随机拆分(train/test/val)。
- split_repo: (str) - 此任务所属的仓库拆分(train/test/val)。
- split_time: (str) - 此任务所属的时间拆分(train/test/val)。
收集过程
- 所有数据均来自公开可访问的 GitHub 仓库,采用 MIT 或 Apache-2.0 许可证。
- 数据通过从 GitHub API 收集问题和 PR 信息来收集。创建任务实例时,我们尝试为每个 PR 找到由该 PR 解决的问题,使用以下链接方法:
- connected: GitHub 提供了一个功能,可以将 PR 分配给其解决的问题。我们使用这些预先存在的链接作为数据集中的链接。
- keyword: 每个 PR 和问题都会被扫描以查找提及,然后检查这些匹配的接近度,以确定某些关键词指示解决方案关系。
- timestamp: 通过查看同时关闭的问题和 PR 来确定可能的匹配,然后使用 OpenAI 嵌入检查它们的标题和描述的语义相似性。
预处理
- 从数据集中移除了修改超过十个文件的任务(因为我们认为它们过于复杂)和修改无文件或仅测试文件的任务。
- 为了提高时间戳链接的准确性,如果存在建议不同匹配的关键词/连接任务,或者存在其他仅时间戳任务且相似度更高,则仅通过时间戳链接的任务将被移除。
用途
- 数据集目前用于训练和验证文件和方法级别的故障定位模型。
- 数据集将用于训练和验证自动代码生成/错误修复模型。
- 其他用途可能存在,但尚未由我们的项目探索。
维护
- 可能会很快添加更多仓库。所有字段可能会根据我们的判断进行更改。
- 这是截至 2024 年 7 月 18 日的数据集最新版本。
许可证
- 版权所有 2024 Feedback2Code
- 根据 Apache 许可证 2.0 版(“许可证”)许可;除非遵守许可证,否则不得使用此文件。
- 您可以在以下位置获取许可证的副本: http://www.apache.org/licenses/LICENSE-2.0
- 除非适用法律要求或书面同意,否则根据许可证分发的软件是基于“按原样”基础分发的,没有任何形式的明示或暗示担保。
- 有关许可证下的特定语言管理和限制,请参阅许可证。
搜集汇总
数据集介绍
构建方式
Mozzarella数据集的构建过程基于GitHub上维护良好的Java仓库,通过匹配问题陈述(issues)与相应的解决方案(pull requests)来创建任务实例。数据收集利用了GitHub API,采用多种链接方法(如GitHub内置的连接功能、关键词匹配和时间戳相似性)来确保问题与解决方案的准确对应。预处理阶段移除了修改文件过多或仅修改测试文件的任务,以提高数据集的质量和适用性。
特点
Mozzarella数据集包含2734个任务实例,涵盖8个高质量的Java仓库。每个任务实例详细记录了问题陈述、解决方案、相关文件及代码变更信息。数据集提供了三种划分方式:随机划分、仓库划分和时间划分,以满足不同研究需求。其独特之处在于结合了问题与解决方案的完整上下文,为代码修复和自动化程序生成提供了丰富的训练和评估资源。
使用方法
Mozzarella数据集主要用于训练和验证故障定位及代码修复模型。研究人员可通过随机、仓库或时间划分方式选择数据子集进行实验。数据集中的问题陈述、代码变更和测试文件信息为模型提供了丰富的上下文,支持从文件级别到方法级别的细粒度分析。此外,该数据集还可用于探索其他代码生成和自动化修复的应用场景。
背景与挑战
背景概述
Mozzarella数据集由Hasso Plattner Institute与SAP合作开发,旨在为复杂代码库的故障定位和自动程序修复提供训练和评估数据。该数据集创建于2024年,主要研究人员来自Feedback2Code项目。数据集的核心研究问题是通过匹配GitHub上的问题描述(issues)与相应的拉取请求(pull requests),为机器学习模型提供高质量的代码修复示例。Mozzarella的灵感来源于SWEBench论文,但其专注于Java代码库,并扩展了数据收集的范围。该数据集对代码检索、代码生成以及自动化程序修复领域具有重要影响,推动了相关技术的进步。
当前挑战
Mozzarella数据集在构建过程中面临多重挑战。首先,数据收集依赖于GitHub API,需要精确匹配问题与拉取请求,这一过程涉及复杂的链接方法,如时间戳、关键词匹配以及语义相似性分析,确保数据的高质量对齐。其次,数据预处理阶段需剔除过于复杂的任务(如修改超过十个文件的任务)以及仅修改测试文件的任务,以确保数据集的适用性和可操作性。此外,数据集的扩展与维护也面临挑战,需不断纳入新的代码库并优化数据结构,以满足不断变化的研究需求。这些挑战不仅体现在数据构建过程中,也反映了自动化代码修复领域的技术难点。
常用场景
经典使用场景
Mozzarella数据集主要用于训练和评估涉及复杂代码库的故障定位和自动程序修复的机器学习模型。通过匹配GitHub上的问题描述和相应的拉取请求,该数据集为研究人员提供了一个丰富的资源,用于开发能够自动识别和修复代码错误的算法。
衍生相关工作
Mozzarella数据集衍生了一系列相关研究,特别是在代码生成和自动修复领域。例如,基于该数据集的研究工作已经开发出能够自动生成修复代码的模型,这些模型在多个开源项目上进行了验证,并展示了显著的性能提升。此外,该数据集还启发了其他类似数据集的创建,如针对Python代码库的SWEBench数据集,进一步扩展了自动代码修复的研究范围。
数据集最近研究
最新研究方向
在软件工程领域,Mozzarella数据集的最新研究方向聚焦于利用机器学习模型进行故障定位和自动化程序修复。该数据集通过匹配GitHub上的问题描述和相应的拉取请求,为复杂代码库的修复提供了丰富的训练和评估数据。当前研究热点包括基于该数据集的文件和方法级别的故障定位模型训练,以及自动代码生成和错误修复模型的开发。此外,随着SWEBench等类似数据集的启发,研究者们正在探索如何将Mozzarella数据集应用于更广泛的编程语言和代码库,以提升自动化修复技术的通用性和效率。该数据集的应用不仅推动了软件维护自动化的发展,也为开源社区的协作和代码质量提升提供了新的工具和方法。
以上内容由遇见数据集搜集并总结生成


