Complex-Edit
收藏github2025-04-18 更新2025-04-21 收录
下载链接:
https://github.com/UCSC-VLAA/Complex-Edit
下载链接
链接失效反馈官方服务:
资源简介:
Complex-Edit是一个全面的基准测试,旨在系统地评估基于指令的图像编辑模型在不同复杂度指令下的表现。该数据集利用GPT-4o自动收集了多样化的编辑指令,并采用“编辑链”管道生成复杂指令。此外,它还引入了一套评估编辑性能的指标和一个基于VLM的自动评估管道。
Complex-Edit is a comprehensive benchmark designed to systematically evaluate the performance of instruction-based image editing models under instructions of varying complexity. This dataset leverages GPT-4o to automatically collect diverse editing instructions, and adopts an "edit chain" pipeline to generate complex instructions. Furthermore, it introduces a set of metrics for evaluating editing performance and a VLM-based automatic evaluation pipeline.
创建时间:
2025-04-18
原始信息汇总
Complex-Edit 数据集概述
数据集简介
Complex-Edit是一个综合性基准测试,旨在系统评估基于指令的图像编辑模型在不同复杂度指令下的表现。该数据集通过GPT-4o自动收集多样化的编辑指令,并采用“Chain-of-Edit”流程生成复杂指令。
关键特点
- 复杂度控制:支持生成不同复杂度的编辑指令。
- 评估指标:包含多维度评估指标和基于VLM的自动评估流程。
- 性能发现:
- 开源模型性能显著低于闭源模型,且差距随复杂度增加而扩大;
- 复杂度增加主要影响关键元素保留和美学质量保持;
- 逐步分解执行复杂指令会显著降低性能;
- Best-of-N选择策略能提升编辑效果;
- 存在“合成数据诅咒”现象。
数据集生成
bash python build_dataset/generate_edits.py -p <path_to_input_image_dir> -o <path_to_output_dir> --max-complexity 8
评估方法
bash python eval.py --image-type <real_or_syn> -p <path_to_output_image_dir> -c <complexity> --resume --num-processes 16
相关资源
- 论文:https://arxiv.org/abs/2504.13143
- 数据集:https://huggingface.co/datasets/UCSC-VLAA/Complex-Edit
- 项目主页:https://ucsc-vlaa.github.io/Complex-Edit/
引用格式
bibtex @article{yang2025complexedit, title={Complex-Edit: CoT-Like Instruction Generation for Complexity-Controllable Image Editing Benchmark}, author={Yang, Siwei and Hui, Mude and Zhao, Bingchen and Zhou, Yuyin and Ruiz, Nataniel and Xie, Cihang}, journal={arXiv preprint arXiv:2504.13143}, year={2025} }
搜集汇总
数据集介绍
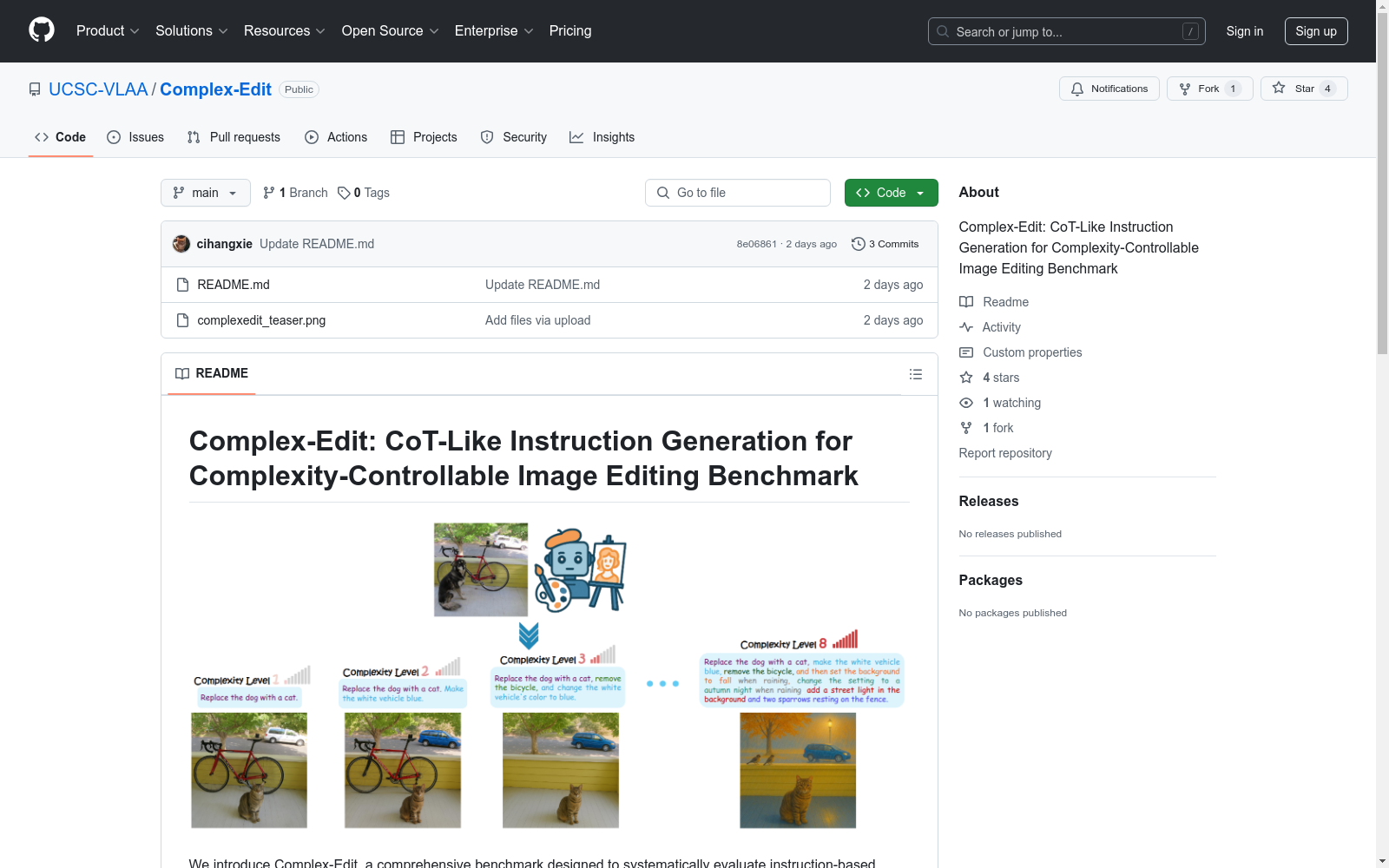
构建方式
在图像编辑领域,Complex-Edit数据集的构建采用了创新的自动化流程。该数据集通过GPT-4o大规模生成多样化的编辑指令,采用分层次的“编辑链”策略:首先生成独立的原子级编辑任务,随后将这些基础任务有机整合为连贯的复杂指令。这种构建方式不仅确保了指令的多样性,还实现了对编辑复杂度的精确控制,为评估模型在不同难度下的表现提供了系统化框架。
使用方法
研究人员可通过HuggingFace平台获取该数据集,其结构化设计支持多种应用场景。基准测试支持端到端的直接编辑评估,也可拆解为原子步骤的序列化执行模式。用户可采用Best-of-N选择策略优化结果,或通过提供的自动评估管道量化模型在复杂度梯度下的表现。数据集配套的标准化度量体系允许跨模型性能对比,特别适合用于研究指令复杂度与编辑质量间的关联性。
背景与挑战
背景概述
Complex-Edit数据集由UCSC-VLAA研究团队于2025年推出,旨在系统评估基于指令的图像编辑模型在不同复杂度指令下的性能表现。该数据集通过GPT-4o自动化生成多样化编辑指令,采用“编辑链”的构建方法,将原子级编辑任务整合为连贯的复杂指令。其创新性体现在首次实现了指令复杂度的可控性评估,为图像编辑领域提供了首个系统性基准测试工具,对推动开放模型与闭源模型的性能对比研究具有重要价值。研究团队提出的视觉语言模型自动评估框架,为大规模图像编辑质量评估建立了新范式。
当前挑战
该数据集面临的核心挑战体现在两个方面:在领域问题层面,随着指令复杂度提升,模型对输入图像关键元素的保留能力和美学质量保持能力显著下降,且开源模型与闭源模型的性能差距呈现扩大趋势;在构建技术层面,如何通过合成数据生成具有语义连贯性的多层次复杂指令,以及避免“合成数据诅咒”现象——即模型输出随指令复杂度增加而呈现过度合成化特征,成为关键技术难点。此外,将复杂指令分解为原子步骤的逐步执行策略反而导致多指标性能下降,这一反直觉现象也构成了重要的研究挑战。
常用场景
经典使用场景
在计算机视觉领域,Complex-Edit数据集为基于指令的图像编辑模型提供了系统化的评估基准。该数据集通过GPT-4o生成的多样化编辑指令,涵盖了从简单到复杂的多层次任务,特别适合用于测试模型在处理不同复杂度指令时的表现。研究人员可以利用这一数据集,深入探究模型在保留关键元素、维持美学质量等方面的能力,从而推动图像编辑技术的发展。
解决学术问题
Complex-Edit数据集解决了图像编辑领域中的关键学术问题,包括模型在复杂指令下的性能评估、合成数据对编辑质量的影响以及逐步执行策略的有效性。通过提供标准化的评估指标和自动评估流程,该数据集为研究者提供了可靠的实验平台,揭示了开源模型与闭源模型之间的性能差距,并为进一步优化模型设计提供了数据支持。
实际应用
在实际应用中,Complex-Edit数据集可广泛应用于图像编辑软件的开发与优化。例如,设计智能修图工具时,开发者可以利用该数据集测试模型对用户复杂指令的理解与执行能力,从而提升产品的用户体验。此外,广告设计、影视后期制作等领域也可借助这一数据集,训练出更高效、精准的图像编辑模型,满足多样化的创作需求。
数据集最近研究
最新研究方向
在图像生成与编辑领域,Complex-Edit数据集的推出为基于指令的复杂图像编辑任务提供了系统性评估框架。该数据集通过GPT-4o自动生成多粒度编辑指令,采用“编辑链”策略将原子任务整合为连贯的复杂指令,并开发了基于视觉语言模型的自动化评估体系。当前研究热点集中在探索开源模型与闭源模型在复杂指令下的性能差异,以及合成数据对生成图像真实性的影响。值得注意的是,随着指令复杂度的提升,模型在关键元素保留和美学质量维持方面的表现呈现显著下降趋势。这一发现为改进多步骤图像编辑算法提供了重要方向,同时也引发了关于合成数据在模型训练中负面效应的新思考。
以上内容由遇见数据集搜集并总结生成


