TimTini/coupa-docs-semantic-index
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/TimTini/coupa-docs-semantic-index
下载链接
链接失效反馈官方服务:
资源简介:
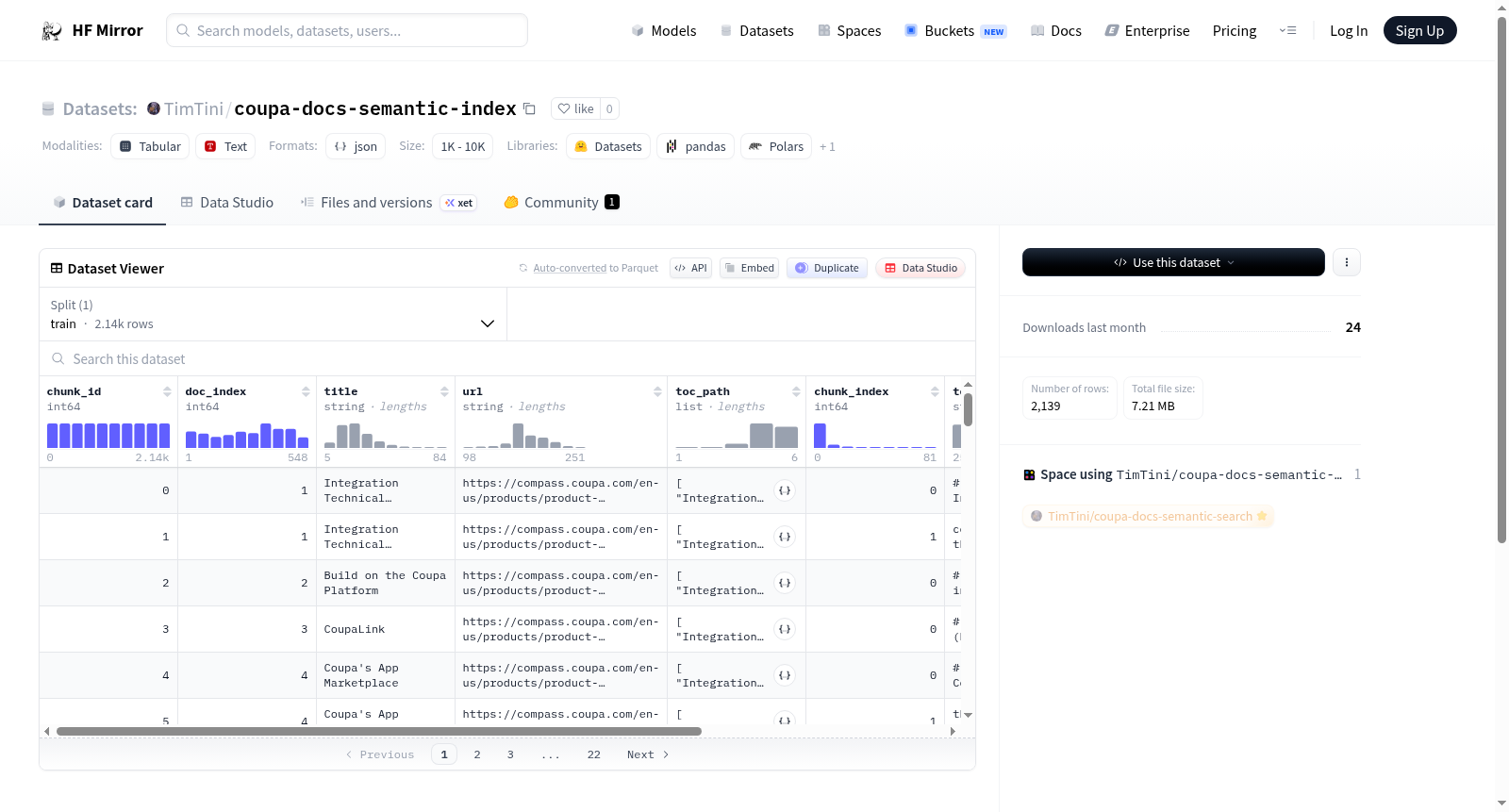
该数据集名为Coupa Docs Semantic Index,用于存储`TimTini/coupa-docs-semantic-index`的语义搜索产物。包含以下文件:chunks.jsonl(用于数据集查看器/训练管道的块行)、embeddings.npy(与chunks.jsonl行索引对齐的密集向量)和index-meta.json(索引元数据,包括模型、维度和块参数)。查看器配置为仅解析chunks.jsonl以避免与元数据文件的模式冲突。
This dataset stores semantic-search artifacts for `TimTini/coupa-docs-semantic-index`. It includes: chunks.jsonl (chunk rows for dataset viewer/training pipelines), embeddings.npy (dense vectors aligned by row index with chunks.jsonl), and index-meta.json (index metadata such as model, dimensions, chunk params). The viewer is configured to parse only chunks.jsonl to avoid schema conflicts with metadata files.
提供机构:
TimTini
搜集汇总
数据集介绍
构建方式
该数据集以语义搜索为核心目标,通过将Coupa文档分割为语义块(chunks)并存储于`chunks.jsonl`文件中构建而成。每个块的行索引与`embeddings.npy`文件中的稠密向量严格对齐,辅以`index-meta.json`记录模型参数、向量维度及分块规则,形成一套结构化的语义索引体系。数据集在HuggingFace平台上仅暴露`chunks.jsonl`供视图查看与训练流水线使用,规避了元数据文件的格式冲突。
特点
数据集的特点在于其高度适配语义检索场景,通过预计算并存储稠密向量,实现了文档块的快速近似匹配。`chunks.jsonl`与`embeddings.npy`的行对齐设计确保了向量与文本的精确对应,而`index-meta.json`则提供了索引构建的透明性与可复现性。这种架构在保持轻量化的同时,兼顾了训练与推理的双重需求。
使用方法
使用时可利用`chunks.jsonl`中的文本块进行模型微调或检索任务,通过加载`embeddings.npy`与目标查询向量进行距离计算以返回最相关块。建议配合`index-meta.json`解析向量维度及模型信息,确保嵌入生成的兼容性。数据集以`default`配置加载,仅包含`train`分割,适用于端到端的语义索引开发与评估。
背景与挑战
背景概述
在自然语言处理与信息检索领域,语义搜索技术通过将文本映射至稠密向量空间,显著提升了对非结构化文档的理解与召回能力。Coupa Docs Semantic Index数据集由TimTini研究团队于近期构建,旨在为Coupa文档提供语义索引,以支持基于向量相似性的高效检索。该数据集的核心研究问题聚焦于如何通过分块(chunk)策略与嵌入向量化,将长文档转化为可被语义搜索系统直接利用的结构化信息。其影响力体现在为商业文档检索提供了标准化的预处理范式,推动了企业级知识库的智能化演进。数据集包含分块文本(chunks.jsonl)、稠密向量(embeddings.npy)及索引元数据,为下游训练与推理奠定了可靠基础。
当前挑战
该数据集所解决的领域问题主要来自工业文档检索中的语义鸿沟,即传统关键词匹配难以捕捉用户意图与文档内容的深层关联,而语义索引需在向量表示的质量与计算效率间取得平衡。构建过程中面临的挑战包括:长文本的合理分块策略制定,需兼顾上下文完整性与向量对齐的一致性;稠密向量生成时模型选择与维度配置对检索精度的敏感影响;以及元数据文件与主数据文件在模式上的冲突,迫使数据处理管线需针对不同文件类型制定差异化加载规则,增加了数据管理的复杂性。
常用场景
经典使用场景
在自然语言处理与信息检索的交叉领域,语义索引数据集扮演着将非结构化文本转化为可检索语义空间的关键角色。coupa-docs-semantic-index数据集专为支撑文档级语义搜索而设计,其经典使用场景在于构建基于稠密向量检索的问答与知识发现系统。数据集提供了经过分块处理的文档片段(chunks.jsonl)及与之对齐的稠密向量表示(embeddings.npy),借助前沿的语义编码模型,研究者可高效地将用户查询与文档片段映射至同一向量空间,通过余弦相似度计算实现精准的语义匹配。这一范式摒弃了传统关键词检索的字面局限,使系统能够理解同义替换、上下文歧义等复杂语言现象,为后续的智能对话、知识图谱构建等高级应用奠定了坚实的数据基础。
实际应用
在工程技术落地过程中,coupa-docs-semantic-index数据集直接赋能企业级知识管理与智能客服系统的构建。以Coupa公司的采购与供应链文档为例,工程师可利用该数据集搭建私有化部署的语义搜索引擎,使员工能够通过自然语言提问(如“如何提交紧急采购申请”)而非精确关键词检索(如“采购申请表_紧急_流程.pdf”)获取相关指导。该数据集同时为自动化文档推荐、合规风险检测等场景提供了数据支撑:系统可基于向量相似度自动推送与当前用户操作耦合度最高的政策条款或更新日志,或在文档内容发生变更时快速识别受影响的上下游依赖。此外,数据集内置的索引元数据(index-meta.json)降低了运维复杂度,使即使没有深度学习专家团队的初创公司也能直接复用社区预计算的向量索引,加速从原型验证到生产部署的进程。
衍生相关工作
围绕coupa-docs-semantic-index数据集的研究与工程实践已催生出一系列衍生工作。在模型优化方面,研究者基于该数据集的向量与分片配对关系,探索了更经济的嵌入压缩技术,例如通过量化感知训练将浮点向量压缩至二值或整型表示,在检索精度损失极小的前提下实现百倍级的存储缩减。在系统架构层面,出现了将数据集中的chunks.jsonl直接接入RAG(检索增强生成)流水线的创新范式,使大语言模型能够动态引用最新文档片段完成事实性问答,显著缓解了模型幻觉问题。数据集的元数据字段还被用于评估不同分块策略(如固定窗口分割、语义边界感知分割)对下游检索召回率的影响,相关实验结论被谱嵌入到向量数据库索引构建的最佳实践指南中。这些衍生工作不仅丰富了语义索引的理论工具箱,更形成了从数据准备到模型部署的完整技术栈闭环。
以上内容由遇见数据集搜集并总结生成


