自动标注的数据集
收藏arXiv2025-02-13 更新2025-02-26 收录
下载链接:
https://cinemaster-dev.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
本文构建了一个自动标注的数据集,通过从大规模视频数据中提取3D边界框和相机轨迹注释。数据集的创建是为了克服野外观测数据集中3D对象运动和相机姿态注释稀缺的问题。该数据集为文本到视频的扩散模型提供了强大的3D布局指导,确保生成用户期望的视频内容。
This paper constructs an automatically annotated dataset by extracting 3D bounding box and camera trajectory annotations from large-scale video data. The dataset is developed to address the scarcity of annotations for 3D object motion and camera pose in real-world observational datasets. It provides robust 3D layout guidance for text-to-video diffusion models, ensuring the generation of video content that aligns with user expectations.
提供机构:
大连理工大学, 香港中文大学, 快手科技
创建时间:
2025-02-13
搜集汇总
数据集介绍
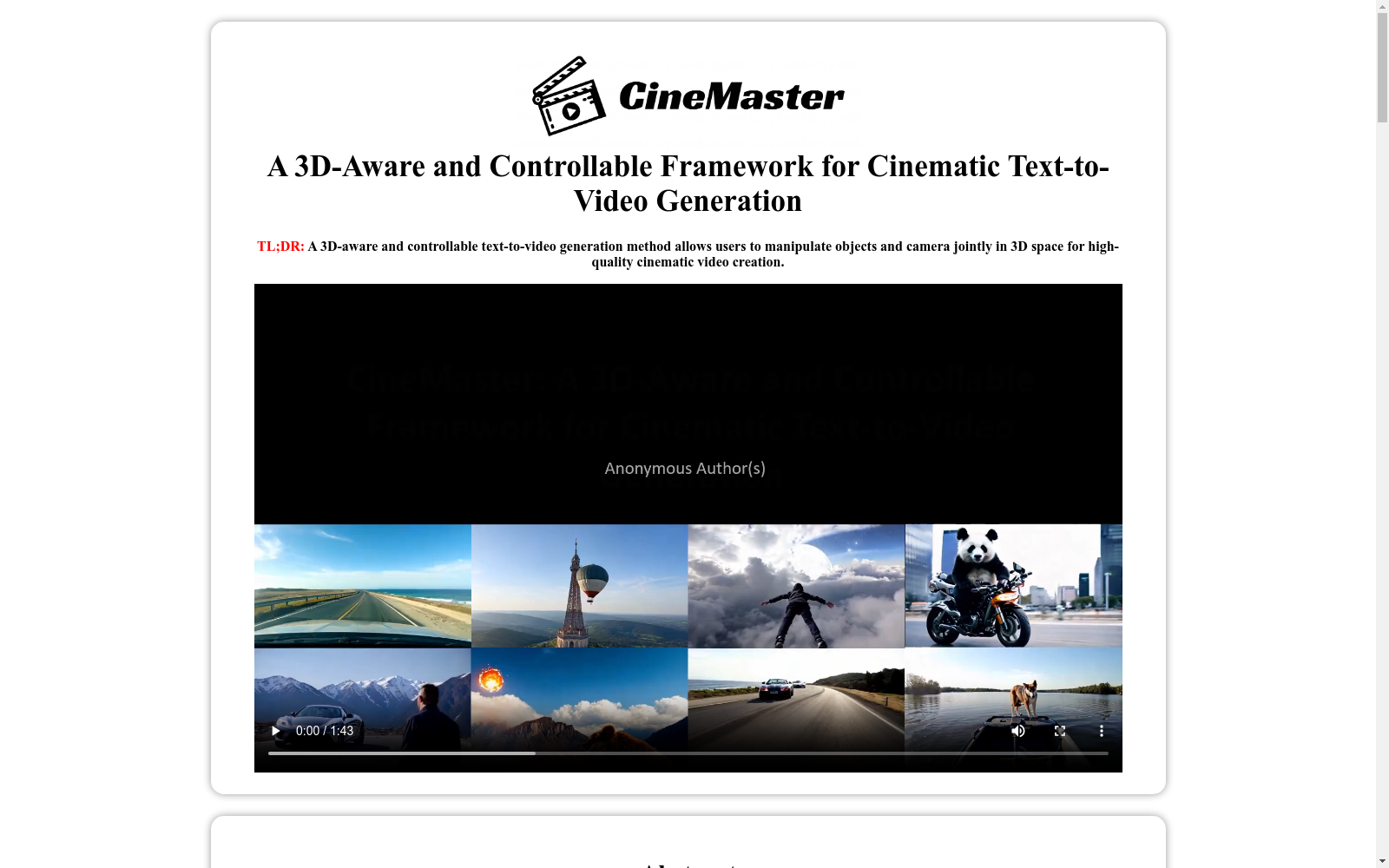
构建方式
CineMaster数据集的构建方式分为两个阶段。首先,通过设计一个交互式工作流程,用户可以直观地构建3D-aware条件信号,通过在3D空间中定位对象边界框和定义相机运动。其次,这些控制信号——包括渲染的深度图、相机轨迹和对象类标签——作为文本到视频扩散模型的指导,确保生成用户期望的视频内容。为了克服现实世界中具有3D对象运动和相机姿态标注的视频数据集稀缺的问题,我们精心建立了一个自动数据标注流程,从大规模视频数据中提取3D边界框和相机轨迹。
特点
CineMaster数据集的特点是它提供了一个高度可控的文本到视频生成框架。用户可以在场景中精确放置对象,灵活地在3D空间中操作对象和相机,并对渲染的帧进行直观的布局控制。该数据集还使用了渲染的深度图作为增强的视觉提示,这些深度图明确地包含每个帧所需的3D布局,为扩散模型生成用户期望的视频内容提供了强大的指导。
使用方法
使用CineMaster数据集的方法包括两个阶段。第一阶段是交互式工作流程,用户可以指定生成视频的要求(条件),类似于电影制作人设计拍摄计划的方式。允许用户使用一组带有语义标签的3D边界框来描述场景中的主要对象。这些边界框以及相机可以在关键帧之间重新定位,使用户能够编排复杂的运动动态。每次修改后,CineMaster都会提供渲染帧的预览,以便进行迭代改进,直到达到所需的渲染效果。在第二阶段,我们微调一个文本到视频扩散模型,以生成由第一阶段提供的控制信号所条件的视频内容。
背景与挑战
背景概述
随着深度学习模型的发展,文本到视频生成(T2V)领域得到了快速的发展。现有的方法往往依赖于预存的视频数据来获取条件图,如深度图、语义图、光流图或边缘图等,这些方法在生成视频内容时往往缺乏精细的控制能力。为了解决这一问题,王庆和 Luo Yawen 等人提出了 CineMaster,这是一个 3D 意识和控制框架,用于电影文本到视频生成。CineMaster 允许用户在 3D 空间中对对象和摄像机进行灵活的操作,从而实现对视频内容的直观布局控制。CineMaster 的目标是为用户提供与专业电影导演相当的操控能力,允许用户在场景中精确放置对象,灵活操作对象和摄像机,并直观地控制渲染帧的布局。为了实现这一目标,CineMaster 采用两阶段工作流程。第一阶段,用户可以通过定位对象边界框和在 3D 空间中定义摄像机运动来直观地构建 3D 意识条件信号。第二阶段,这些控制信号(包括渲染深度图、摄像机轨迹和对象类别标签)作为文本到视频扩散模型的指导,确保生成用户预期的视频内容。此外,为了克服现实世界数据集中 3D 对象运动和摄像机姿态标注稀缺的问题,CineMaster 建立了一个自动数据标注流程,从大规模视频数据中提取 3D 边界框和摄像机轨迹。通过大量的定性和定量实验,CineMaster 显著优于现有方法,实现了突出的 3D 意识文本到视频生成。
当前挑战
CineMaster 面临的挑战主要包括:1) 现有的文本到视频生成方法往往缺乏精细的控制能力,无法实现与专业电影导演相当的操控能力;2) 构建 3D 意识条件图的过程相对复杂,难以从零开始创建;3) 现有的数据集中缺乏 3D 对象运动和摄像机姿态标注,这限制了模型的训练和泛化能力。为了解决这些问题,CineMaster 提出了一个自动数据标注流程,从大规模视频数据中提取 3D 边界框和摄像机轨迹,并设计了一个交互式工作流程,允许用户在 3D 空间中直观地构建 3D 意识条件信号。此外,CineMaster 还引入了渲染深度图作为增强视觉线索,为扩散模型提供更明确的 3D 布局指导。
常用场景
经典使用场景
CineMaster数据集主要用于3D感知和可控的文本到视频生成任务。该数据集允许用户以类似于专业电影导演的方式精确放置场景中的物体,灵活操作物体和摄像机,并对渲染的每一帧进行直观的布局控制。用户可以自由调整物体的大小和位置,通过重新定位关键帧中的物体和摄像机来获得直观的控制,并利用预览机制检查渲染的每一帧,直到达到满意的渲染效果。
实际应用
CineMaster数据集的实际应用场景包括但不限于电影制作、游戏开发、虚拟现实、在线教育和社交媒体内容创作。通过CineMaster,用户可以轻松地创建和控制视频内容,为电影制作提供更高效的工具,为游戏开发提供更丰富的互动体验,为虚拟现实创造更逼真的场景,为在线教育提供更生动的内容,为社交媒体内容创作提供更多的创意和可能性。
衍生相关工作
CineMaster数据集的提出衍生了一系列相关工作,如3D感知视频生成、可控视频生成和联合运动控制等。这些工作进一步推动了文本到视频生成技术的发展,为用户提供了更强大的视频内容创作工具。CineMaster数据集的提出也为其他领域的研究提供了启示,如自动驾驶、机器人视觉和虚拟现实等。
以上内容由遇见数据集搜集并总结生成


