有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
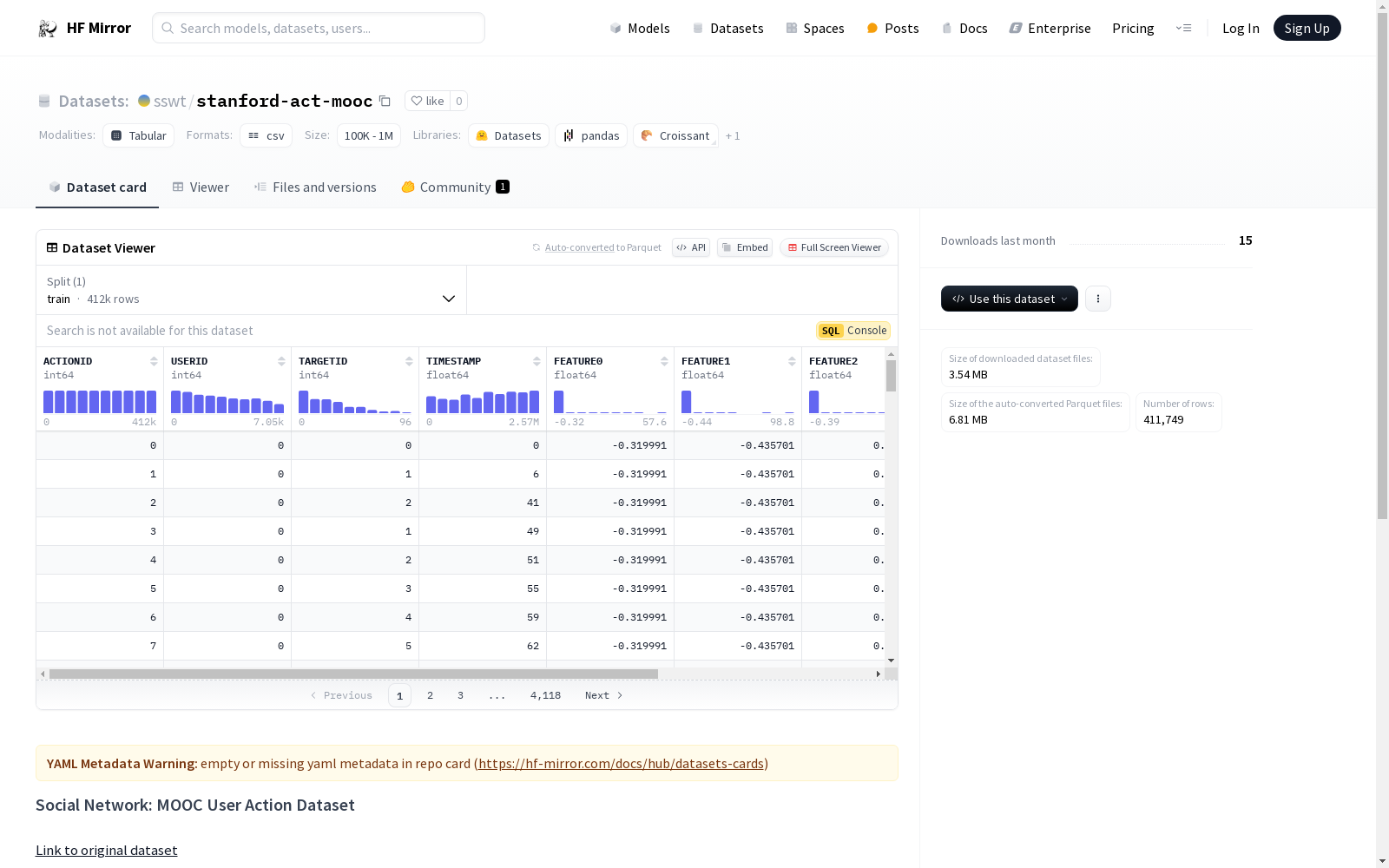
MOOC用户行为数据集代表了用户在一个流行的MOOC平台上的行为。每个行为具有属性和时间戳,并且每个行为都有一个二进制标签,表示用户在该行为后是否退出了课程,即该行为是否是用户的最后一个行为。
该数据集是作为高级用户建模和推荐系统研究项目的一部分生成的。
原始数据集包含三个不同的CSV文件,这里已合并为一个文件。
Subway Dataset
该数据集包含了全球多个城市的地铁系统数据,包括车站信息、线路图、列车时刻表、乘客流量等。数据集旨在帮助研究人员和开发者分析和模拟城市交通系统,优化地铁运营和乘客体验。
www.kaggle.com 收录
Yahoo Finance
Dataset About finance related to stock market
kaggle 收录
Breast Cancer Dataset
该项目专注于清理和转换一个乳腺癌数据集,该数据集最初由卢布尔雅那大学医学中心肿瘤研究所获得。目标是通过应用各种数据转换技术(如分类、编码和二值化)来创建一个可以由数据科学团队用于未来分析的精炼数据集。
github 收录
HazyDet
HazyDet是由解放军工程大学等机构创建的一个大规模数据集,专门用于雾霾场景下的无人机视角物体检测。该数据集包含383,000个真实世界实例,收集自自然雾霾环境和正常场景中人工添加的雾霾效果,以模拟恶劣天气条件。数据集的创建过程结合了深度估计和大气散射模型,确保了数据的真实性和多样性。HazyDet主要应用于无人机在恶劣天气条件下的物体检测,旨在提高无人机在复杂环境中的感知能力。
arXiv 收录
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录