swahili-child-assessment-v2
收藏Hugging Face2025-06-10 更新2025-06-11 收录
下载链接:
https://huggingface.co/datasets/Batazia/swahili-child-assessment-v2
下载链接
链接失效反馈官方服务:
资源简介:
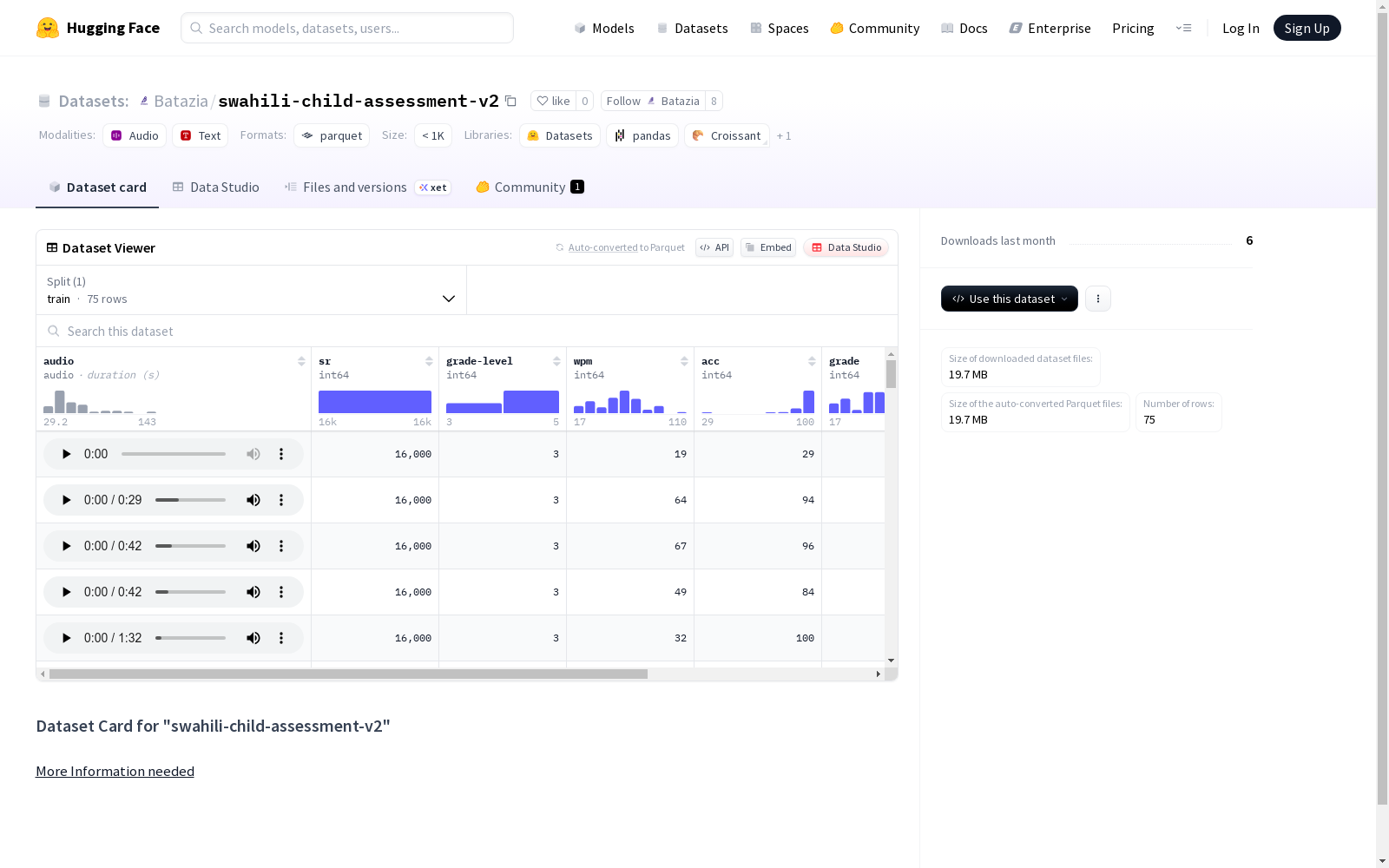
Swahili Child Assessment v2数据集包含斯瓦希里语儿童的朗读录音,以及与每个录音相关的特征,如采样率、朗读速度、准确度等。数据集分为训练集,包含了75个示例。
提供机构:
Batazia
创建时间:
2025-06-10
搜集汇总
数据集介绍
构建方式
在斯瓦希里语儿童语言评估领域,该数据集通过采集75名不同年级学童的朗读音频构建而成,采样率统一设定为16000赫兹。每个样本均包含原始音频及朗读文本句子,并经由专业评估人员标注单词每分钟朗读数、准确率及错误类型等多维指标,形成结构化数据以支持教育语言学分析。
特点
数据集核心特征体现在其多维度标注体系,除基础音频数据外,同步提供年级分级、朗读速度、准确率及具体错误统计等量化指标。所有样本均采用标准化采样率确保声学特征一致性,且错误类型标注为研究儿童语言习得过程中的典型偏误模式提供了细粒度分析基础。
使用方法
研究者可借助音频特征提取技术分析朗读流利度与声学参数关联,结合年级分层数据追踪语言能力发展轨迹。机器学习领域可通过端到端模型预测朗读准确率,或构建错误类型分类器。使用时需注意年级变量作为控制因素,建议采用交叉验证确保模型泛化能力。
背景与挑战
背景概述
斯瓦希里儿童评估数据集v2诞生于东非语言教育技术研究领域,由专业教育机构与 computational linguistics 团队联合构建,旨在通过儿童朗读音频的韵律特征与流利度指标,量化评估语言习得水平。该数据集聚焦于斯瓦希里语母语儿童的阅读能力发展研究,通过采集真实课堂环境下的朗读样本,为教育诊断与自适应学习系统提供关键数据支撑,推动了低资源语言教育评估的实证研究进展。
当前挑战
该数据集核心挑战在于解决低资源语言儿童阅读能力多维评估问题,需从音频特征中提取语速、准确率和错误类型等细粒度指标,并建立与年龄适配能力的关联模型。数据构建过程中面临儿童发音模糊性、背景噪声干扰以及斯瓦希里语方言变体的标注一致性难题,同时需克服教育场景数据采集的伦理合规性与样本规模限制。
常用场景
经典使用场景
在斯瓦希里语教育技术研究中,该数据集被广泛应用于儿童语言能力评估模型的训练与验证。研究者通过分析音频数据中的单词每分钟读数(wpm)、准确率(acc)及错误次数等特征,构建自动化的阅读流畅性评估系统,为教育工作者提供客观的量化工具。
实际应用
在实际应用中,该数据集支撑了斯瓦希里语地区的智能教育系统开发。基于其训练的模型可集成至移动端应用,帮助教师快速筛查学生的阅读障碍,为个性化教学方案制定提供数据支持,尤其在偏远地区教育资源匮乏的场景中发挥重要作用。
衍生相关工作
该数据集衍生了多项跨语言教育技术研究,包括基于迁移学习的低资源语言阅读评估框架、端到端的斯瓦希里语语音识别模型,以及结合多模态数据的儿童语言发展追踪系统。这些工作为全球南方国家的教育数字化提供了重要技术参考。
以上内容由遇见数据集搜集并总结生成


