Lyrics
收藏Hugging Face2025-02-10 更新2025-02-11 收录
下载链接:
https://huggingface.co/datasets/Ahmadsameh8/Lyrics
下载链接
链接失效反馈官方服务:
资源简介:
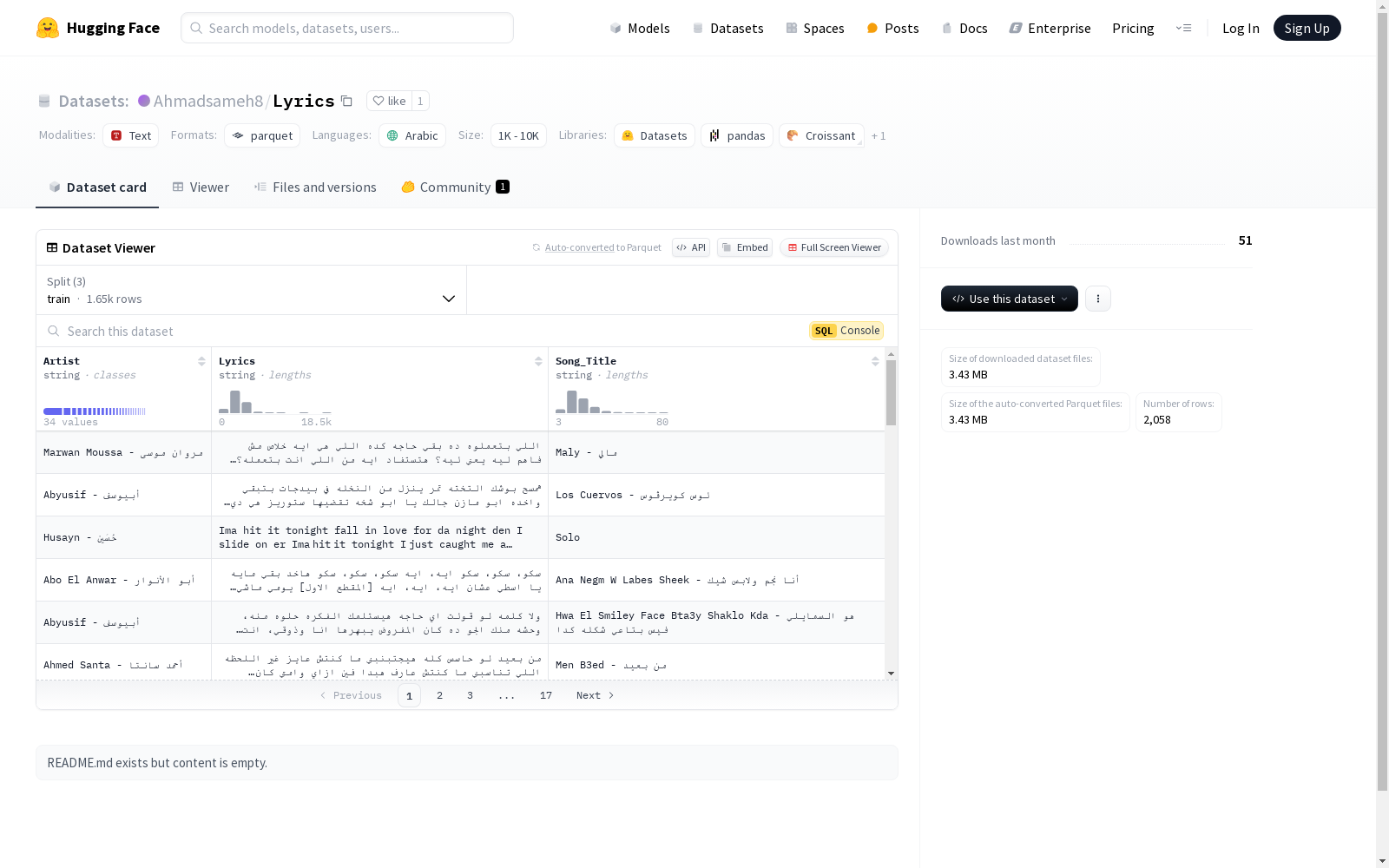
这是一个包含艺术家、歌词和歌曲标题信息的音乐数据集,分为训练集、验证集和测试集,适用于阿拉伯语等语言环境。
创建时间:
2025-02-09
搜集汇总
数据集介绍
构建方式
Lyrics数据集的构建,以音乐领域为切入点,精心挑选了包含阿拉伯语在内的多语种歌词文本。数据集通过整合艺术家(Artist)、歌词(Lyrics)以及歌曲标题(Song_Title)三个维度的信息,形成了结构化的数据集。在数据划分上,遵循机器学习领域常用的三份划分模式,即训练集、验证集和测试集,确保了数据集的可训练性和可评估性。
特点
本数据集的特点在于,其不仅提供了丰富的歌词文本,而且涵盖了与之相关的艺术家和歌曲标题信息,为音乐内容分析、情感分析以及歌手风格研究等领域的学术研究提供了坚实基础。此外,数据集的多样性和规模性使其成为自然语言处理任务中,特别是在歌词生成、风格模仿等任务上的重要资源。
使用方法
使用Lyrics数据集时,用户可根据自己的研究需求,选择适当的配置文件以访问训练集、验证集和测试集中的数据。数据以文件形式存储,用户可通过指定的路径访问各部分数据,进而进行数据加载、预处理以及后续的模型训练和评估工作。数据集提供的默认配置简化了数据访问流程,使得用户能够快速入门并开展相关研究。
背景与挑战
背景概述
Lyrics数据集是一项专注于音乐领域文本信息的研究成果,其创建旨在为音乐情感分析、风格分类以及音乐推荐系统等研究领域提供基础数据支持。该数据集的构建始于对音乐文本内容的深入理解需求,由相关研究人员精心策划与整理,包含了艺术家信息、歌词文本以及歌曲标题等关键信息。自发布以来,Lyrics数据集以其全面性和准确性,对音乐信息处理领域产生了显著影响,成为该领域不可或缺的资源之一。
当前挑战
尽管Lyrics数据集为音乐文本分析提供了宝贵的资源,但在实际应用中仍面临诸多挑战。首先,歌词内容的多样性和复杂性使得情感分析与风格分类任务充满难度。其次,构建过程中,如何保证数据的质量和多样性,以及如何处理版权问题,都是数据集构建者必须面对的难题。此外,数据集的规模虽然相对较大,但对于涵盖全球范围内的音乐文化而言,仍存在覆盖面不足的问题。
常用场景
经典使用场景
在音乐与文学研究领域,Lyrics数据集以其独特的文本属性,被广泛用于分析和探索歌词中的情感、主题及风格。该数据集提供了艺术家、歌曲标题和歌词等信息,使得研究者能够轻松地基于文本内容进行深入的音乐文化研究。
解决学术问题
Lyrics数据集为学术界解决了一系列关于歌词内容分析的问题,如情感识别、主题分类和风格判断等。它为研究者提供了一个坚实的基础,使得对音乐文本进行量化分析成为可能,进而促进了音乐与文学交叉学科的发展。
衍生相关工作
基于Lyrics数据集,学术界衍生出了众多相关工作,包括但不限于情感分析模型的开发、歌词生成算法的研究以及音乐风格演变的历史分析,这些研究进一步拓宽了音乐研究的边界,推动了相关领域的创新。
以上内容由遇见数据集搜集并总结生成


