TingChen-ppmc/Tianjin_Dialect_Conversational_Speech_Corpus
收藏Hugging Face2024-05-31 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/TingChen-ppmc/Tianjin_Dialect_Conversational_Speech_Corpus
下载链接
链接失效反馈官方服务:
资源简介:
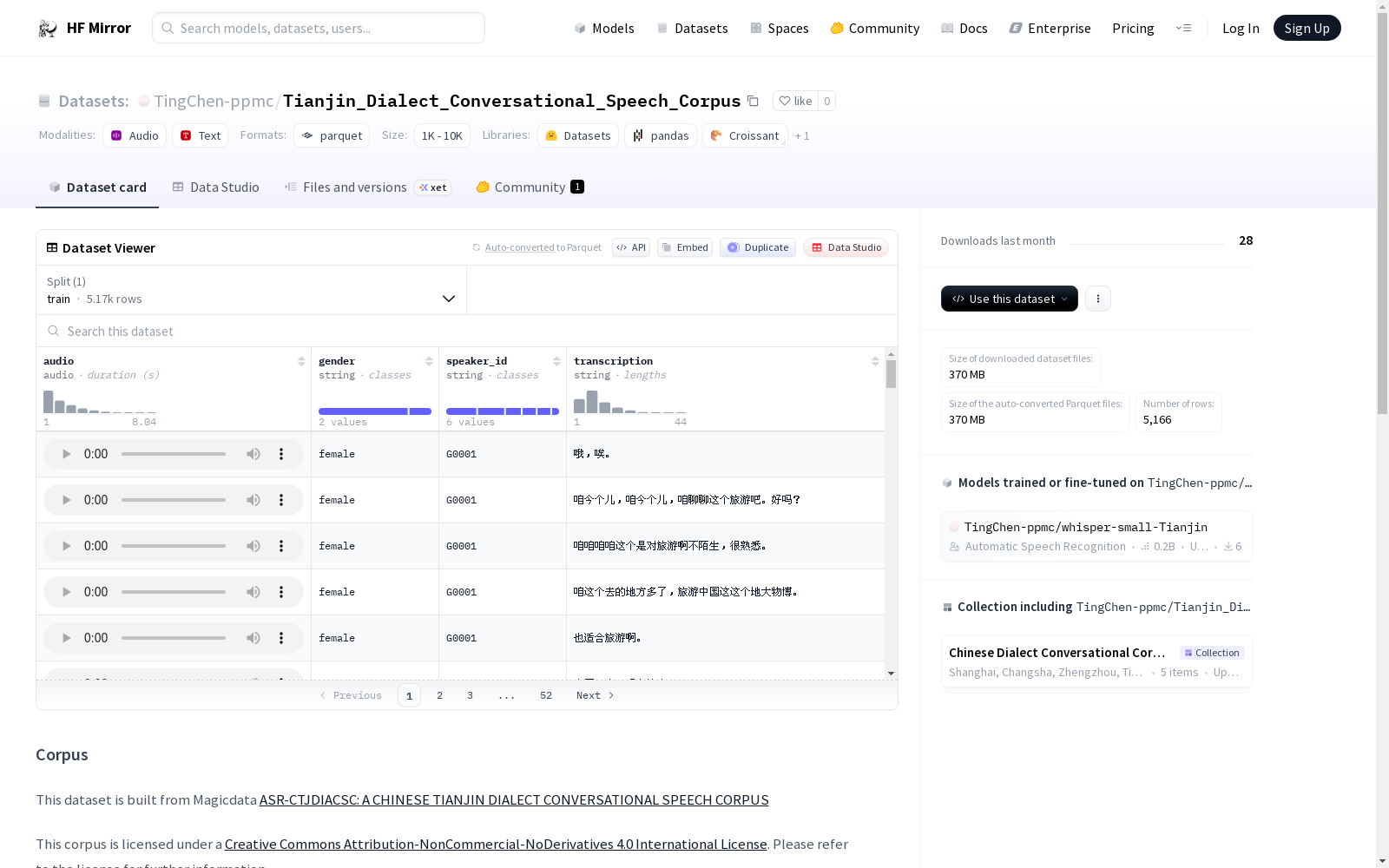
该数据集基于Magicdata的ASR-CTJDIACSC语料库构建,包含天津方言的对话语音。数据集的特征包括音频、性别、说话者ID和转录文本。数据集仅包含训练集,大小为384247410.342字节,包含5166个样本。音频根据转录文件的时间跨度被分割为句子,少于1秒的句子和对话主题被删除。数据集采用Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License许可协议。
该数据集基于Magicdata的ASR-CTJDIACSC语料库构建,包含天津方言的对话语音。数据集的特征包括音频、性别、说话者ID和转录文本。数据集仅包含训练集,大小为384247410.342字节,包含5166个样本。音频根据转录文件的时间跨度被分割为句子,少于1秒的句子和对话主题被删除。数据集采用Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License许可协议。
提供机构:
TingChen-ppmc
原始信息汇总
数据集概述
数据集信息
特征
- audio: 音频数据
- gender: 说话人性别,字符串类型
- speaker_id: 说话人ID,字符串类型
- transcription: 语音转录文本,字符串类型
数据分割
- train: 训练集,包含5166个样本,总大小为384247410.342字节
数据集大小
- download_size: 370228314字节
- dataset_size: 384247410.342字节
配置
- config_name: default
- data_files:
- split: train
- path: data/train-*
- data_files:
数据集加载
python from datasets import load_dataset dialect_corpus = load_dataset("TingChen-ppmc/Tianjin_Dialect_Conversational_Speech_Corpus")
数据样本
python {audio: {path: A0001_S001_0_G0001_0.WAV, array: array([-0.00030518, -0.00039673, -0.00036621, ..., -0.00064087, -0.00015259, -0.00042725]), sampling_rate: 16000}, gender: 女, speaker_id: G0001, transcription: 北京爱数智慧语音采集 }
搜集汇总
数据集介绍
构建方式
在方言语音资源日益受到重视的背景下,Tianjin_Dialect_Conversational_Speech_Corpus的构建源于MagicData平台发布的ASR-CTJDIACSC天津方言对话语音语料库。原始语料经过精心处理,依据转录文件中的时间跨度将音频切分为独立句子,并剔除了持续时间不足一秒的片段,同时移除了对话主题信息,以确保数据单元的纯净性与一致性。这一过程旨在为天津方言的语音识别与语言学研究提供结构清晰、质量可控的基础资源。
使用方法
利用Hugging Face的datasets库,用户可通过load_dataset函数直接加载该数据集,默认仅包含训练集。若需划分测试集,可借助train_test_split方法按比例分割,例如设定test_size=0.5即可将一半数据划入测试集。每条数据以字典形式呈现,包含音频路径、数组、采样率及文本标注等信息,便于集成至语音识别或方言分析流程中,支持端到端的模型训练与评估。
背景与挑战
背景概述
在语音技术领域,方言语音资源的稀缺性长期制约着相关研究的深入发展。Tianjin_Dialect_Conversational_Speech_Corpus(天津方言对话语音语料库)由Magicdata机构创建,旨在应对这一挑战。该数据集聚焦于天津方言这一特定地域语言变体,其核心研究问题在于如何构建高质量、大规模的自然对话语音资源,以支持方言语音识别、合成及语言保存等任务。该语料库的出现,为计算语言学与语音技术领域提供了宝贵的方言数据基础,推动了针对汉语方言的自动化处理研究,并对文化遗产的数字化保存产生了积极影响。
当前挑战
该数据集致力于解决方言自动语音识别这一领域核心问题,其首要挑战在于方言本身的语音、词汇及语法特性与标准普通话存在显著差异,这要求模型具备更强的泛化与适应能力。在构建过程中,研究者面临多重困难:采集自然、高质量的方言对话需克服发音人招募与录音环境控制的难题;语音切分与转写需要精细的语音学知识与人工校对,以确保时间戳与文本的精确对齐;此外,在遵循知识共享许可协议的前提下进行数据清洗与格式化,亦需平衡数据效用与合规性要求。
常用场景
经典使用场景
在方言语音识别与保护领域,Tianjin_Dialect_Conversational_Speech_Corpus作为天津方言对话语音的珍贵资源,其经典使用场景聚焦于方言语音识别模型的训练与评估。该数据集通过提供大量真实对话录音及对应转写文本,为构建高精度方言自动语音识别系统奠定了数据基础。研究者可借助其音频特征与文本标注,开发针对天津方言的端到端识别模型,有效捕捉方言在音素、语调及韵律上的独特变异,从而推动方言语音技术的实质性进展。
解决学术问题
该数据集直接应对了方言语音资源匮乏这一长期学术挑战,为方言语音学、计算语言学及语音技术研究提供了关键数据支撑。它助力解决方言语音识别中因数据稀缺导致的模型泛化能力不足问题,并支持方言语音变异、音系分析及语言接触现象的研究。通过提供结构化、标注规范的对话语料,该数据集促进了方言语音技术的标准化评估,对保护语言多样性及传承地方文化遗产具有深远意义。
实际应用
在实际应用层面,该数据集可服务于智能语音助手、方言教育工具及文化遗产数字化项目。例如,基于此数据集训练的方言语音识别引擎,能嵌入本地化智能设备,为天津地区用户提供更亲切的语音交互体验。同时,在语言教学领域,它可作为发音矫正与听力训练的素材;在文化保护方面,则为方言的录音存档与语音合成提供了高质量数据源,助力方言在数字时代的活态传承。
数据集最近研究
最新研究方向
在方言语音资源日益受到重视的背景下,Tianjin_Dialect_Conversational_Speech_Corpus作为天津方言对话语音的珍贵语料,正推动方言语音识别与合成技术的前沿探索。当前研究聚焦于利用该数据集训练端到端的方言自动语音识别模型,以应对方言音变和词汇特殊性带来的挑战,同时结合说话人身份和性别信息,探索个性化方言语音合成方法。随着语言多样性保护成为热点,该数据集为方言数字人文研究和智能语音交互系统的本土化适配提供了关键支持,对促进非物质文化遗产的数字化传承具有深远意义。
以上内容由遇见数据集搜集并总结生成


