StableText2Lego
收藏arXiv2025-05-09 更新2025-05-10 收录
下载链接:
https://avalovelace1.github.io/LegoGPT/
下载链接
链接失效反馈官方服务:
资源简介:
StableText2Lego 数据集是一个包含超过 47,000 个不同的 LEGO 结构的大型数据集,这些结构覆盖了 ShapeNetCore 数据集中的 28,000 个独特的 3D 对象,共分为 21 个常见的对象类别。每个结构都配有一组文本描述和一个稳定性分数,用于指示其物理稳定性和可构建性。该数据集的构建过程涉及将 ShapeNetCore 中的 3D 形状转换为 LEGO 结构,然后进行结构稳定性和文本描述的生成。该数据集可用于训练生成物理稳定和可构建的 LEGO 设计的模型,并可用于解决实际物体设计中存在的构建难度和结构稳定性问题。
The StableText2Lego dataset is a large-scale collection comprising over 47,000 distinct LEGO constructions, which cover 28,000 unique 3D objects from the ShapeNetCore dataset and are categorized into 21 common object categories. Each construction is paired with a textual description and a stability score that indicates its physical stability and buildability. The construction of this dataset involves converting 3D shapes from ShapeNetCore into LEGO structures, followed by the generation of structural stability metrics and textual descriptions. This dataset can be used to train models that generate physically stable and buildable LEGO designs, as well as to address challenges related to construction difficulty and structural stability in real-world object design.
提供机构:
卡内基梅隆大学
创建时间:
2025-05-09
原始信息汇总
数据集概述:Generating Physically Stable and Buildable LEGO® Designs from Text
基本信息
- 标题: Generating Physically Stable and Buildable LEGO® Designs from Text
- 作者: Ava Pun*, Kangle Deng*, Ruixuan Liu*, Deva Ramanan, Changliu Liu, Jun-Yan Zhu (* denotes equal contribution)
- 机构: Carnegie Mellon University
- 论文链接: arXiv
- 代码: 提供
- Demo: 提供
数据集描述
- 数据集名称: StableText2Lego
- 规模: 超过47,000个LEGO结构,涵盖28,000个独特的3D对象
- 数据生成流程:
- 从ShapeNetCore网格生成LEGO设计,通过体素化到20×20×20网格并应用legolization确定砖块布局。
- 通过随机化砖块布局增强每个形状的多个结构变体,同时保留整体形状。
- 对每个变体进行稳定性分析,过滤掉物理不稳定的设计。
- 通过24个不同视角渲染LEGO设计,使用GPT-4o生成详细的几何描述。
- 特点: 每个形状附带详细描述,确保多样性和稳定性。
方法概述
- 模型名称: LegoGPT
- 方法:
- 将LEGO设计标记化为文本标记序列,按从下到上的光栅扫描顺序排列。
- 创建指令数据集,将砖块序列与描述配对,微调LLaMA-3.2-Instruct-1B。
- 在推理时,LegoGPT根据文本提示逐步生成LEGO设计,每次预测一个砖块。
- 对每个生成的砖块进行有效性检查,确保格式正确、存在于砖块库中且不与现有砖块碰撞。
- 完成设计后验证其物理稳定性,若不稳定则回滚到稳定状态并继续生成。
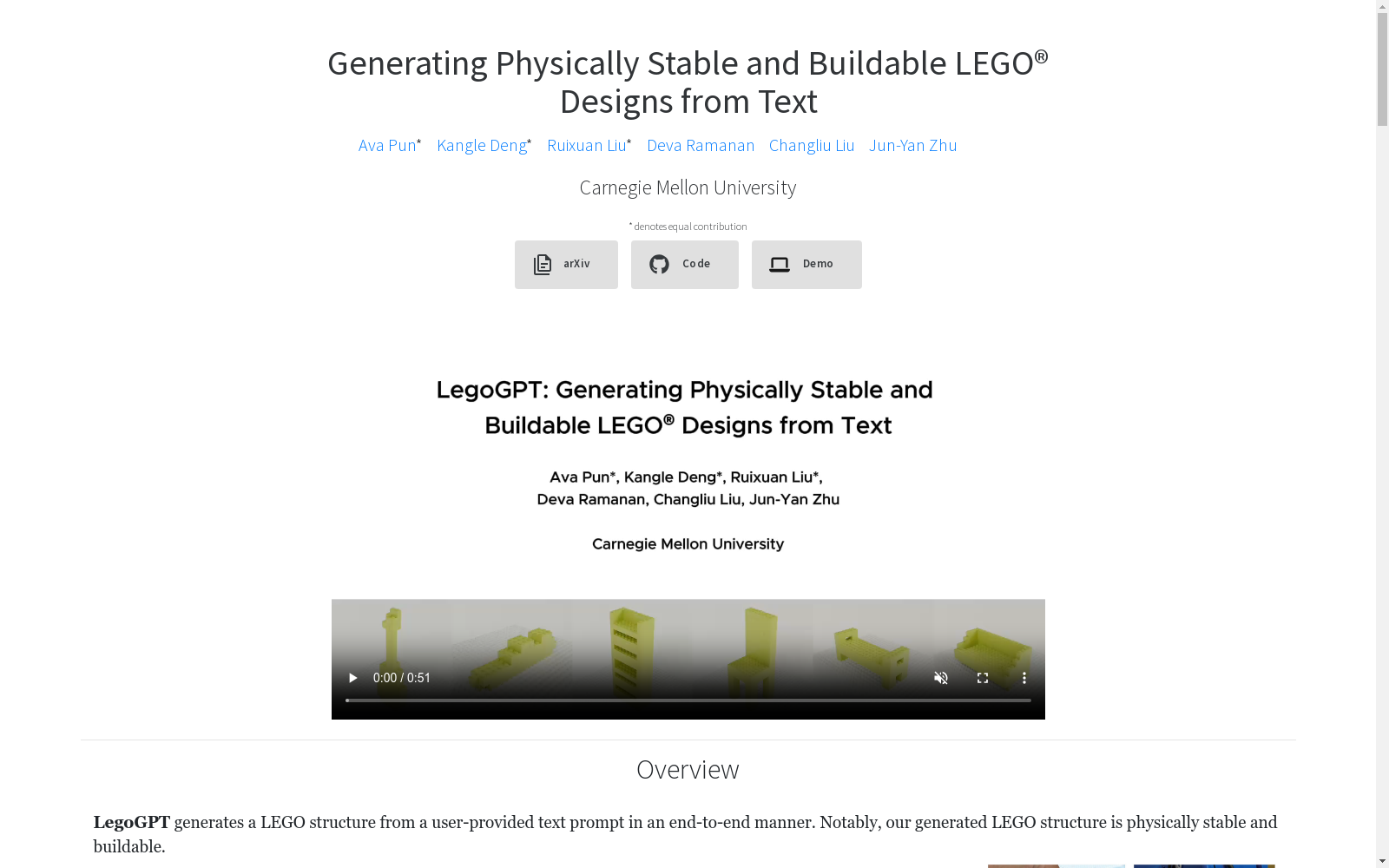
应用示例
- 文本到LEGO结构生成:
- "A streamlined vessel with a long, narrow hull"
- "A classical guitar"
- "A basic sofa"
- "A bookshelf with horizontal tiers"
- "A high-backed chair"
- "A backless bench with armrest"
- 机器人自动组装: 展示生成结构的自动化组装过程(8倍速)。
- 纹理和彩色LEGO模型生成:
- "Rustic stone bench with moss growth [...]"
- "Hot rod with flame paintwork [...]"
- "Electric guitar in metallic purple [...]"
- "Sunburst Les Paul with amber finish [...]"
引用
bibtex @article{pun2025legogpt, title = {Generating Physically Stable and Buildable LEGO Designs from Text}, author = {Pun, Ava and Deng, Kangle and Liu, Ruixuan and Ramanan, Deva and Liu, Changliu and Zhu, Jun-Yan}, journal = {arXiv preprint arXiv:2505.05469}, year = {2025} }
致谢
- 感谢Minchen Li, Ken Goldberg, Nupur Kumari, Ruihan Gao, Yihao Shi的讨论和帮助。
- 感谢Jiaoyang Li, Philip Huang, Shobhit Aggarwal开发的双手机器人系统。
- 支持机构: Packard Foundation, Cisco Research Grant, Amazon Faculty Award, Manufacturing Futures Institute, Carnegie Mellon University, Richard King Mellon Foundation, Microsoft Research PhD Fellowship。
搜集汇总
数据集介绍
构建方式
StableText2Lego数据集的构建基于ShapeNetCore中的3D模型,通过体素化和分割-重合并的乐高化算法,将3D网格转换为乐高积木结构。每个乐高结构由一系列积木块组成,每个积木块的状态由其尺寸和位置定义。为了增强数据的多样性和质量,研究人员引入了随机性,为每个3D对象生成多个不同的乐高结构。此外,通过稳定性分析筛选出物理上稳定的设计,确保每个结构在实际组装中不会倒塌或分离。
特点
StableText2Lego数据集包含超过47,000个乐高结构,涵盖28,000多个独特的3D对象,来自21个常见物体类别。每个乐高结构配有详细的几何描述文本和稳定性评分,确保其物理稳定性和可组装性。数据集支持多样化的乐高设计,包括基本结构和带有外观描述的彩色及纹理模型,适用于生成模型的训练和评估。
使用方法
StableText2Lego数据集可用于训练和评估文本到乐高设计的生成模型。研究人员可以基于该数据集训练自回归语言模型,通过文本提示生成物理稳定的乐高结构。生成的设计可直接用于手动或机器人自动组装。此外,数据集支持乐高纹理和颜色的生成,扩展了创意设计的可能性。具体使用时,可结合提供的代码和模型进行端到端的乐高设计生成和验证。
背景与挑战
背景概述
StableText2Lego数据集由卡内基梅隆大学的研究团队于2025年提出,旨在解决文本到物理可构建LEGO模型生成的挑战。该数据集包含超过47,000个稳定的LEGO结构,覆盖28,000多个独特的3D对象,涉及21个常见物体类别。其核心研究问题是通过文本描述生成物理稳定且可构建的LEGO设计,填补了传统3D生成模型在物理可实现性方面的空白。该数据集的发布推动了文本到3D生成领域的发展,特别是在物理约束和实际应用方面。
当前挑战
StableText2Lego数据集面临的主要挑战包括:1) 领域问题的挑战,即如何从自由文本描述生成物理稳定的LEGO设计,确保结构不会倒塌或包含浮动砖块;2) 构建过程中的挑战,包括大规模物理稳定LEGO设计的收集与标注,以及如何在自回归推理中有效整合物理约束。此外,确保生成的LEGO设计与标准LEGO零件兼容且可由人类或机器人逐步组装也是一大挑战。
常用场景
经典使用场景
在计算机视觉与生成模型领域,StableText2Lego数据集为文本到3D物理稳定结构的生成提供了关键支持。其经典使用场景包括通过自然语言描述直接生成可组装的LEGO模型,例如输入“带有长窄船体的流线型船只”即可输出符合物理稳定性的砖块布局序列。该数据集特别适用于需要兼顾创意设计与工程可行性的跨模态生成任务,研究人员可利用其砖块级装配序列和稳定性评分,验证生成模型在物理约束下的表现。
实际应用
在实际应用中,该数据集支撑了从教育到工业的多场景创新。教育领域可基于其开发交互式设计工具,学生通过自然语言即时获得可拼装的物理模型;智能制造中,机器人能直接解析生成的砖块序列完成自动化装配。例如论文展示的双机械臂系统,成功将生成的“高背椅”设计转化为实体结构,验证了从数字生成到物理落地的完整闭环。
衍生相关工作
该数据集催生了多个衍生研究方向。在方法层面,启发研究者将物理引擎整合至生成流程,如后续工作提出的力学感知扩散模型;在应用层面,推动了文本驱动纹理生成、多智能体装配规划等跨学科研究。典型成果包括基于该数据集训练的LEGOGPT模型,其创新的自回归砖块预测框架已成为文本到实体生成的新范式,相关技术已扩展至建筑模块化设计等领域。
以上内容由遇见数据集搜集并总结生成


