LEXam
收藏Hugging Face2025-05-21 更新2025-05-22 收录
下载链接:
https://huggingface.co/datasets/LEXam-Benchmark/LEXam
下载链接
链接失效反馈官方服务:
资源简介:
LEXam是一个包含340个法律考试的法律推理基准数据集,涵盖瑞士、欧盟和国际法律的考试。它包括三种类型的问题:具有四个选项的标准选择题(mcq_4_choices)、使用排列扰动增加难度的选择题(mcq_perturbation)和开放性问题(open_question)。数据集支持英语和德语,并可用于文本分类和文本生成任务。
创建时间:
2025-05-16
原始信息汇总
LEXam: Benchmarking Legal Reasoning on 340 Law Exams
数据集概述
- 许可证: CC-BY-4.0
- 语言: 英语 (en), 德语 (de)
- 标签: 法律 (legal), 推理 (reasoning), 法律 (law)
- 任务类别: 文本分类 (text-classification), 文本生成 (text-generation)
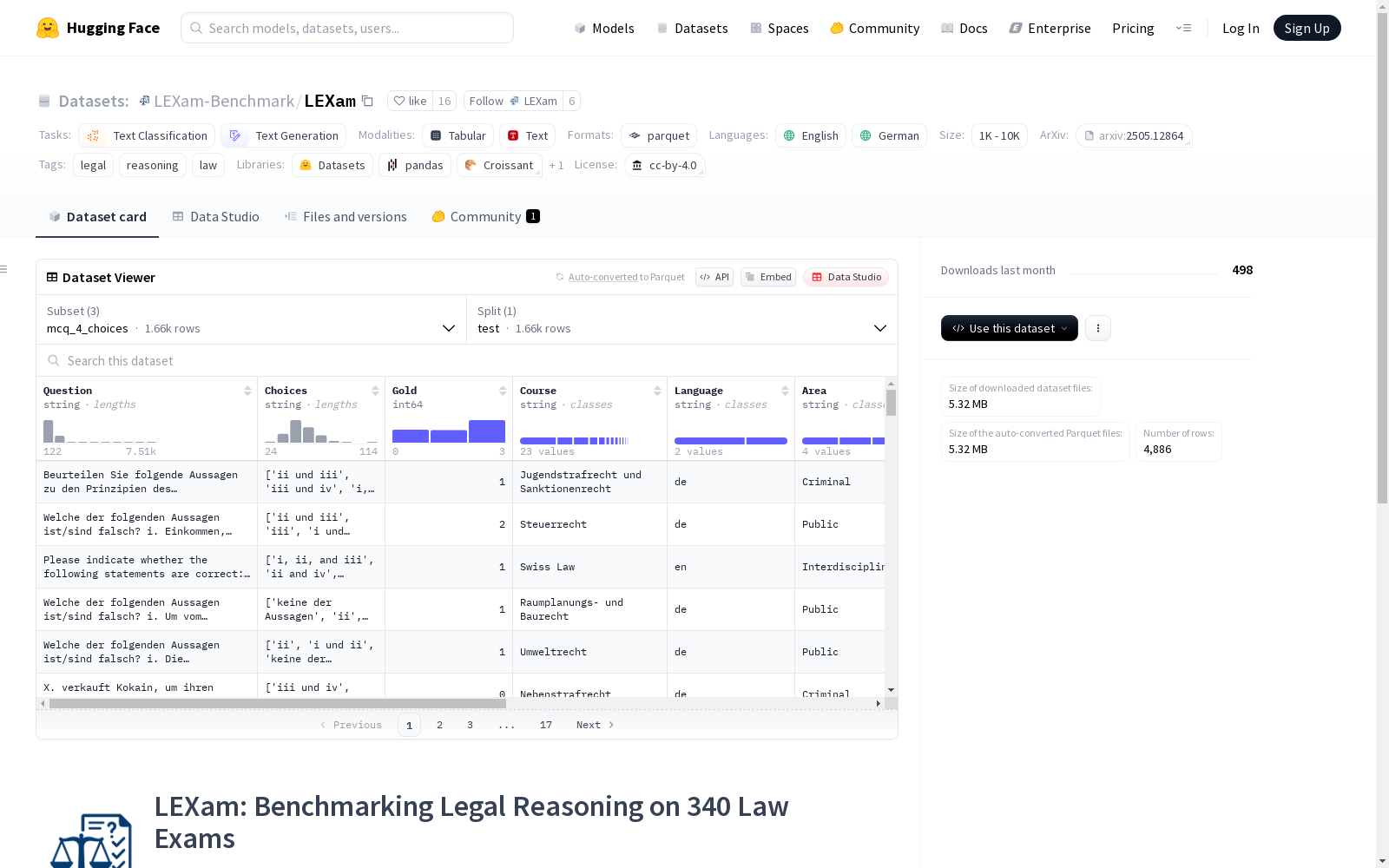
子集详情
1. mcq_4_choices
- 描述: 标准1660道四选一选择题。
- 特征:
- Question (string): 问题
- Choices (string): 选项
- Gold (int64): 正确答案索引
- Course (string): 课程
- Language (string): 语言
- Area (string): 领域
- Jurisdiction (string): 司法管辖区
- Year (int64): 年份
- n_statements (int64): 陈述数量
- none_as_an_option (bool): 是否包含“无”选项
- Id (string): 唯一标识符
- 数据量:
- 测试集: 1,660 条样本
- 下载大小: 833,522 字节
- 数据集大小: 1,701,781 字节
2. mcq_perturbation
- 描述: 包含一组控制问题但扰动选项的选择题,选项数量为4、8、16、32个。
- 特征:
- question (string): 问题
- 4_choices (string): 4个选项
- 4_choices_answer (int64): 4个选项的答案索引
- 8_choices (string): 8个选项
- 8_choices_answer (int64): 8个选项的答案索引
- 16_choices (string): 16个选项
- 16_choices_answer (int64): 16个选项的答案索引
- 32_choices (string): 32个选项
- 32_choices_answer (int64): 32个选项的答案索引
- course (string): 课程
- language (string): 语言
- n_statements (int64): 陈述数量
- id (string): 唯一标识符
- 数据量:
- 测试集: 385 条样本
- 下载大小: 327,280 字节
- 数据集大小: 779,770 字节
3. open_question
- 描述: 所有开放性问题,包含丰富的元数据。
- 特征:
- Question (string): 问题
- Answer (string): 答案
- Course (string): 课程
- Language (string): 语言
- Area (string): 领域
- Jurisdiction (string): 司法管辖区
- Year (int64): 年份
- ID (string): 唯一标识符
- 数据量:
- 测试集: 2,541 条样本
- 开发集: 300 条样本
- 下载大小: 4,159,184 字节
- 数据集大小: 8,961,256 字节
相关资源
- GitHub 仓库: https://github.com/LEXam-Benchmark/LEXam
- 论文: https://arxiv.org/abs/2505.12864
搜集汇总
数据集介绍
构建方式
LEXam数据集作为法律人工智能领域的重要基准,其构建过程体现了严谨的学术态度。该数据集精选自瑞士、欧盟及国际法律考试中的340套试题,通过专家团队严格筛选和标注,确保内容的权威性和代表性。数据集包含三种子集:标准四选一多选题、扰动多选题和开放式问答题,每种题型均经过法律专家的双重验证,以保证试题的准确性和挑战性。特别值得注意的是,扰动多选题通过控制问题不变而增加选项数量(4至32个)的方式,系统性地提升了测试难度。
特点
LEXam数据集以其多样性和专业性著称。涵盖英语和德语两种语言,涉及不同法律领域和司法管辖区,包含1660道标准多选题和2541道开放式问题。每道题目均附带丰富的元数据,包括课程类别、法律领域、司法管辖区和年份等信息。扰动多选题子集通过选项数量变化(4/8/16/32个选项)的创新设计,为评估模型在复杂决策场景下的鲁棒性提供了独特维度。开放式问题子集则包含开发集和测试集,支持生成式模型的全面评估。
使用方法
使用LEXam数据集时,研究者可根据需求选择不同子集进行评估。标准多选题(mcq_4_choices)适合基础法律推理能力测试;扰动多选题(mcq_perturbation)可检验模型在选项干扰下的稳定性;开放式问题(open_question)则适用于生成式模型评估。数据集提供清晰的字段结构,包括问题文本、选项、正确答案及丰富元数据。通过HuggingFace平台或GitHub仓库获取数据后,可直接加载进行模型训练或测试,配套代码库还提供了标准化的评估流程。
背景与挑战
背景概述
LEXam数据集是法学与人工智能交叉领域的重要评测基准,由瑞士及欧盟研究团队于2025年构建,旨在系统评估AI模型在法律推理任务上的表现。该数据集收录了来自瑞士、欧盟及国际法领域的340套法律考试真题,涵盖多选题与开放式问题两种题型,涉及民商法、刑法等六大法律领域,支持英语和德语双语言版本。其创新性在于首次将真实法律考试场景标准化为AI评测任务,为衡量模型在法律条文理解、案例推理等核心能力提供了严谨的度量标准,对推动可解释性法律AI的发展具有里程碑意义。
当前挑战
构建LEXam面临双重挑战:在领域问题层面,法律考试题目的高度专业化要求模型同时掌握跨法系知识推理能力(如大陆法系与普通法系的差异)和细粒度条文引用能力,现有模型在32选项扰动测试中准确率下降达47%;在数据构建层面,需解决多语言法律术语对齐、敏感信息脱敏等难题,团队通过联合12名法律专家进行三轮标注校验,最终确保每道题目的司法管辖区、法律领域等元数据标注准确率达98.6%。开放式问题评分标准的客观量化仍是待突破的难点。
常用场景
经典使用场景
在法律人工智能领域,LEXam数据集以其340套法律考试的丰富题库,成为评估模型法律推理能力的黄金标准。该数据集通过多项选择题和开放式问题的组合,模拟真实法律考试环境,特别适用于测试模型在瑞士、欧盟及国际法等多司法管辖区下的法律条文理解和案例应用能力。研究人员利用其结构化的问题设计和详尽的元数据,能够深入分析模型在不同法律领域(如民法、刑法)和语言(英语、德语)中的表现差异。
解决学术问题
LEXam有效解决了法律AI研究中缺乏标准化评估基准的痛点。其严格由法律专家验证的试题,为衡量模型对法律概念的理解深度、跨司法管辖区的推理能力提供了量化工具。通过控制题目难度梯度(如选项扰动技术)和覆盖不同法律层级(从具体条文到抽象原则),该数据集推动了可解释法律推理、跨语言法律知识迁移等前沿方向的研究,填补了传统NLP基准在法律专业领域的空白。
衍生相关工作
围绕LEXam已催生多项创新研究,如基于选项扰动技术的《LegalBERT-PT》通过对抗训练提升模型鲁棒性;《JurisLMs》系列工作利用其多语言特性探索法律知识跨司法管辖区的迁移规律。该数据集还启发了《ExamGAN》等生成模型的研究,通过合成符合法律逻辑的新试题扩展评估维度,形成持续演进的良性研究生态。
以上内容由遇见数据集搜集并总结生成


