HRScene
收藏arXiv2025-04-25 更新2025-04-29 收录
下载链接:
https://yszh8.github.io/hrscene/
下载链接
链接失效反馈官方服务:
资源简介:
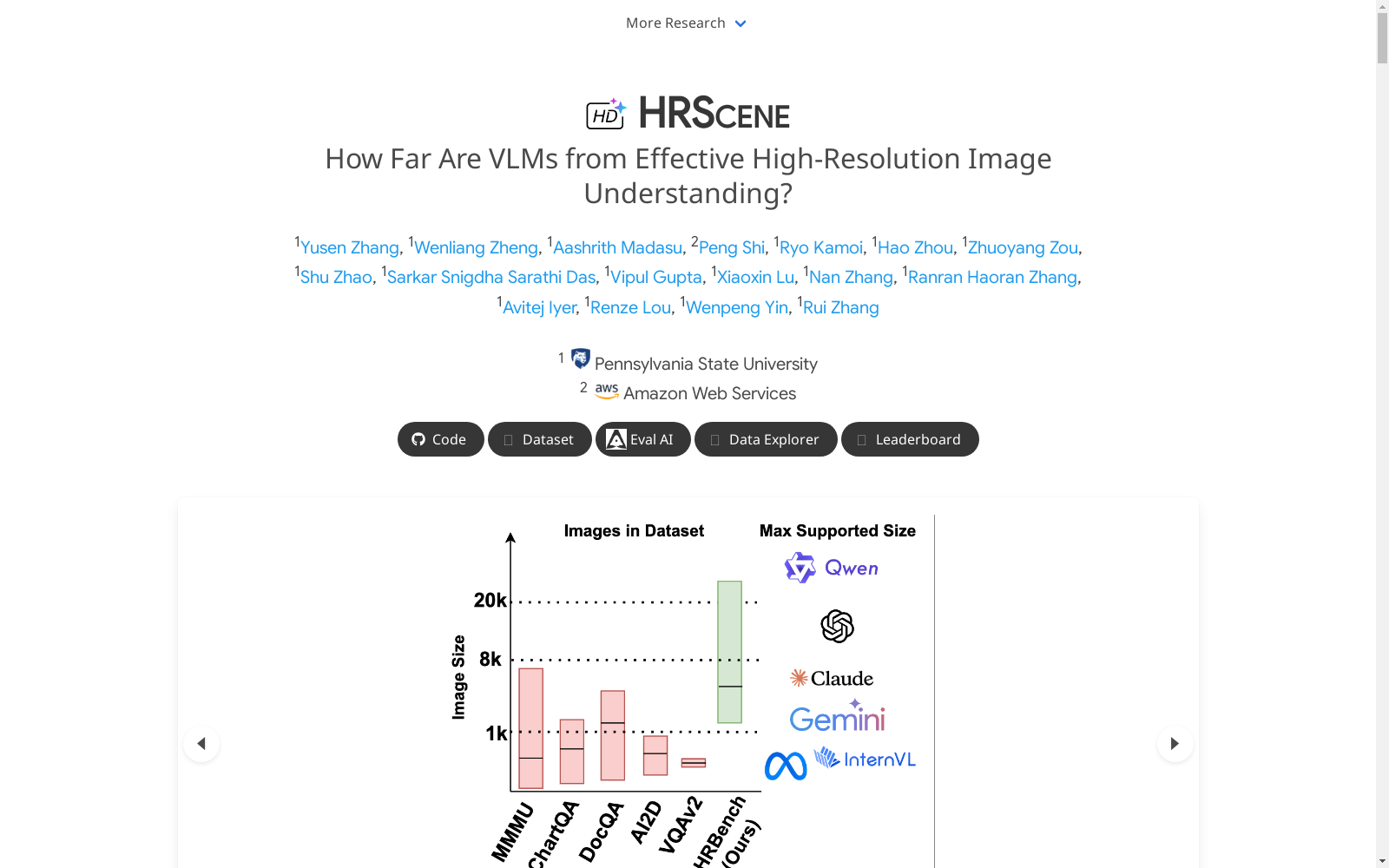
HRScene是一个用于高分辨率图像(HRI)理解的新颖统一基准,包含丰富的场景。它包含了25个真实世界的数据集和2个合成诊断数据集,分辨率范围从1,024 × 1,024到35,503 × 26,627。HRScene由10名研究生级别的标注员收集和重新标注,涵盖了从显微镜到放射学图像、街景、长距离照片和望远镜图像的25个场景。它包括真实世界对象的高分辨率图像、扫描文档和复合多图像。两个诊断评估数据集是通过将目标图像与金标准答案和干扰图像以不同顺序组合来合成的,以评估模型如何利用HRI中的区域。我们进行了广泛的实验,涉及28个VLMs,包括Gemini 2.0 Flash和GPT-4o。HRScene上的实验表明,当前的VLMs在现实世界任务上平均准确率约为50%,揭示了HRI理解中的重大差距。合成数据集上的结果表明,VLMs难以有效利用HRI区域,显示出显著的区域分化和迷失在中部的问题,为未来的研究提供了启示。
HRScene is a novel unified benchmark for high-resolution image (HRI) understanding, encompassing diverse scenarios. It consists of 25 real-world datasets and 2 synthetic diagnostic datasets, with resolutions ranging from 1,024 × 1,024 to 35,503 × 26,627. HRScene was collected and re-annotated by 10 graduate-student-level annotators, covering 25 scenario types spanning microscopic images, radiological images, street views, long-distance photographs, and telescopic images. Its corpus includes high-resolution images of real-world objects, scanned documents, and composite multi-image datasets. The two synthetic diagnostic datasets are constructed by combining target images, gold standard annotations, and distractor images in varying orders, aiming to evaluate how models leverage regional information within HRIs. We conducted extensive experiments involving 28 vision-language models (VLMs), including Gemini 2.0 Flash and GPT-4o. Experimental results on HRScene demonstrate that current VLMs achieve an average accuracy of approximately 50% on real-world tasks, revealing significant gaps in HRI understanding. Results on the synthetic datasets show that VLMs struggle to effectively utilize regional information in HRIs, exhibiting notable regional discrimination issues and the problem of getting trapped in central regions, which provides valuable insights for future research.
提供机构:
宾夕法尼亚州立大学
创建时间:
2025-04-25
原始信息汇总
HRScene数据集概述
数据集简介
- 名称: HRScene
- 目的: 评估视觉大语言模型(VLMs)在高分辨率图像(HRI)理解方面的能力
- 特点:
- 首个统一的HRI理解基准
- 包含丰富场景的高分辨率图像
- 分辨率范围: 1,024×1,024至35,503×26,627像素
数据集构成
- 来源:
- 25个真实世界数据集
- 2个合成诊断数据集
- 标注:
- 由10名研究生级别标注员重新标注
- 覆盖25种场景(从显微镜到望远镜图像)
- 样本量: 7,081张图像(其中2,008张重新标注)
数据集分类
- 8个任务类别:
- Daily pictures
- Urban planning
- Paper scanned images
- Artwork
- Multi-subimages
- Remote sensing
- Medical Diagnosing
- Research understanding
数据集划分
- val: 750个样本(与人工标注样本相同)
- testmini: 1,000个样本(来自各真实世界数据集)
- test: 5,323个样本(答案标签不公开)
评估结果
- 模型表现:
- 当前VLMs平均准确率约50%
- 在合成数据集上表现差距超过20%
- 最佳表现模型: Qwen2-VL 72B(62.03%准确率)
诊断数据集发现
- 区域发散现象: 模型在不同图像区域表现不一致
- 曼哈顿距离现象: 性能随距离呈U型变化
数据访问
- 下载地址: Hugging Face Dataset
- 评估平台: 提供在线评估服务
模型提交
- 提交方式: 通过EvalAI平台
- 工具支持: 提供自动模型预测和提交管道
关键统计
- 图像分辨率分布: 从1k到超过35k像素
- 任务类型分布: 覆盖多种视觉上下文类型
- 问题长度分布: 记录每个问题的单词数分布
搜集汇总
数据集介绍
构建方式
HRScene数据集通过整合25个真实世界数据集和2个合成诊断数据集构建而成,覆盖了从1,024×1,024到35,503×26,627的不同分辨率图像。数据集的构建过程包括从现有数据资源中筛选符合高分辨率标准的图像,并由10名研究生级别的标注者进行重新标注,确保数据质量和多样性。此外,还合成了两个诊断数据集,用于评估视觉语言模型在高分辨率图像理解中的区域利用能力。
特点
HRScene数据集的特点在于其广泛覆盖了多种高分辨率图像场景,包括日常图片、城市规划、医学诊断、遥感图像等25个不同领域。数据集中包含7,068张图像,其中2,008张经过重新标注,确保了标注的准确性和一致性。此外,数据集还提供了人类性能基准,用于对比模型表现。
使用方法
HRScene数据集的使用方法包括三个主要部分:验证集(val)、小型测试集(testmini)和完整测试集(test)。验证集用于模型设置的细粒度验证,小型测试集适用于快速模型开发评估,而完整测试集则用于标准评估。数据集的在线评估平台支持用户提交模型结果,并在官方排行榜上展示评估结果。
背景与挑战
背景概述
HRScene是由宾夕法尼亚州立大学和亚马逊网络服务的研究团队于2025年提出的高分辨率图像理解基准数据集。该数据集旨在填补视觉大语言模型(VLMs)在高分辨率图像理解领域缺乏全面评估工具的空白。HRScene整合了25个真实场景数据集和2个合成诊断数据集,覆盖从1,024×1,024到35,503×26,627的不同分辨率范围,涵盖了从显微图像到遥感图像等多种场景。该数据集的创建为高分辨率图像处理领域的研究提供了重要的评估工具,推动了VLMs在复杂视觉任务中的应用。
当前挑战
HRScene面临的挑战主要包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,高分辨率图像理解需要模型同时处理全局上下文和局部细节,当前VLMs在此类任务上的平均准确率仅为50%左右,显示出明显的性能差距。在构建过程中,数据集的多样性和高质量标注是一大挑战,HRScene通过整合多个现有数据集并重新标注,确保了数据的广泛覆盖和准确性。此外,合成诊断数据集的创建也面临如何有效评估模型区域利用能力的挑战。
常用场景
经典使用场景
HRScene数据集作为高分辨率图像(HRI)理解的统一基准,广泛应用于评估视觉大语言模型(VLMs)在处理百万像素级图像时的性能。其经典使用场景包括病理图像分析、农业航拍图像解析以及复杂文档理解等领域。通过整合25个真实世界数据集和2个合成诊断数据集,HRScene为研究者提供了一个全面的测试平台,覆盖从微观到天文图像的多样化场景。
实际应用
在实际应用中,HRScene支持智能城市监控系统对高分辨率街景图像的实时解析,辅助医疗诊断中的病理切片分析,并提升遥感图像中微小目标的检测精度。例如,在自动驾驶领域,该数据集可验证模型对远距离交通标志的识别能力;在文档数字化场景中,其复合子图像任务能评估模型对复杂排版结构的理解。
衍生相关工作
HRScene的发布催生了多项创新研究:基于其诊断结果开发的Dual-Encoder架构(如InternVL2)通过并行处理高低分辨率特征提升性能;Qwen2-VL等模型针对原生分辨率支持进行优化,在20k像素天文图像任务中表现突出。相关衍生工作还包括针对区域发散问题的注意力机制改进,以及针对中间信息丢失的层次化特征融合策略。
以上内容由遇见数据集搜集并总结生成


