DataScienceUIBK/ComplexTempQA
收藏Hugging Face2024-09-22 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/DataScienceUIBK/ComplexTempQA
下载链接
链接失效反馈官方服务:
资源简介:
ComplexTempQA是一个大规模的数据集,专为复杂的时间问题回答(TQA)设计。它包含超过1亿个问题-答案对,涵盖了1987年至2023年的事件、实体和时间段。问题分为属性、比较和计数三种主要类型,并进一步细分为与事件、实体或时间段相关的子类型。数据集还包含丰富的元数据,如唯一标识符、问题文本、答案、问题类型、难度评分、时间范围等。数据集可用于评估和训练大型语言模型的时间推理能力,支持时间问题回答、信息检索和语言理解的研究。
ComplexTempQA is a large-scale dataset specifically designed for complex temporal question answering (TQA). It contains over 100 million question-answer pairs, covering events, entities and time spans from 1987 to 2023. The questions are categorized into three main types: attribute, comparative and counting, and further subdivided into subtypes related to events, entities or time spans. The dataset also includes rich metadata such as unique identifiers, question text, answer, question type, difficulty rating, time range and so on. This dataset can be used to evaluate and train the temporal reasoning capabilities of large language models, and supports research in temporal question answering, information retrieval and language understanding.
提供机构:
DataScienceUIBK
原始信息汇总
ComplexTempQA 数据集
ComplexTempQA 是一个大规模的复杂时间问答(TQA)数据集。它包含超过 1 亿个问答对,是 TQA 领域中最大的数据集之一。该数据集使用来自 Wikipedia 和 Wikidata 的数据生成,涵盖了 36 年的时间范围(1987-2023)。
数据集描述
ComplexTempQA 将问题分为三种主要类型:
- 属性问题
- 比较问题
- 计数问题
这些类别根据其与事件、实体或时间段的关联进一步细分。
问题类型和数量
| 问题类型 | 子类型 | 数量 |
|---|---|---|
| 属性 | 事件 | 83,798 |
| 属性 | 实体 | 84,079 |
| 属性 | 时间 | 9,454 |
| 比较 | 事件 | 25,353,340 |
| 比较 | 实体 | 74,678,117 |
| 比较 | 时间 | 54,022,952 |
| 计数 | 事件 | 18,325 |
| 计数 | 实体 | 10,798 |
| 计数 | 时间 | 12,732 |
| 多跳 | 76,933 | |
| 未命名事件 | 8,707,123 | |
| 总计 | 100,228,457 |
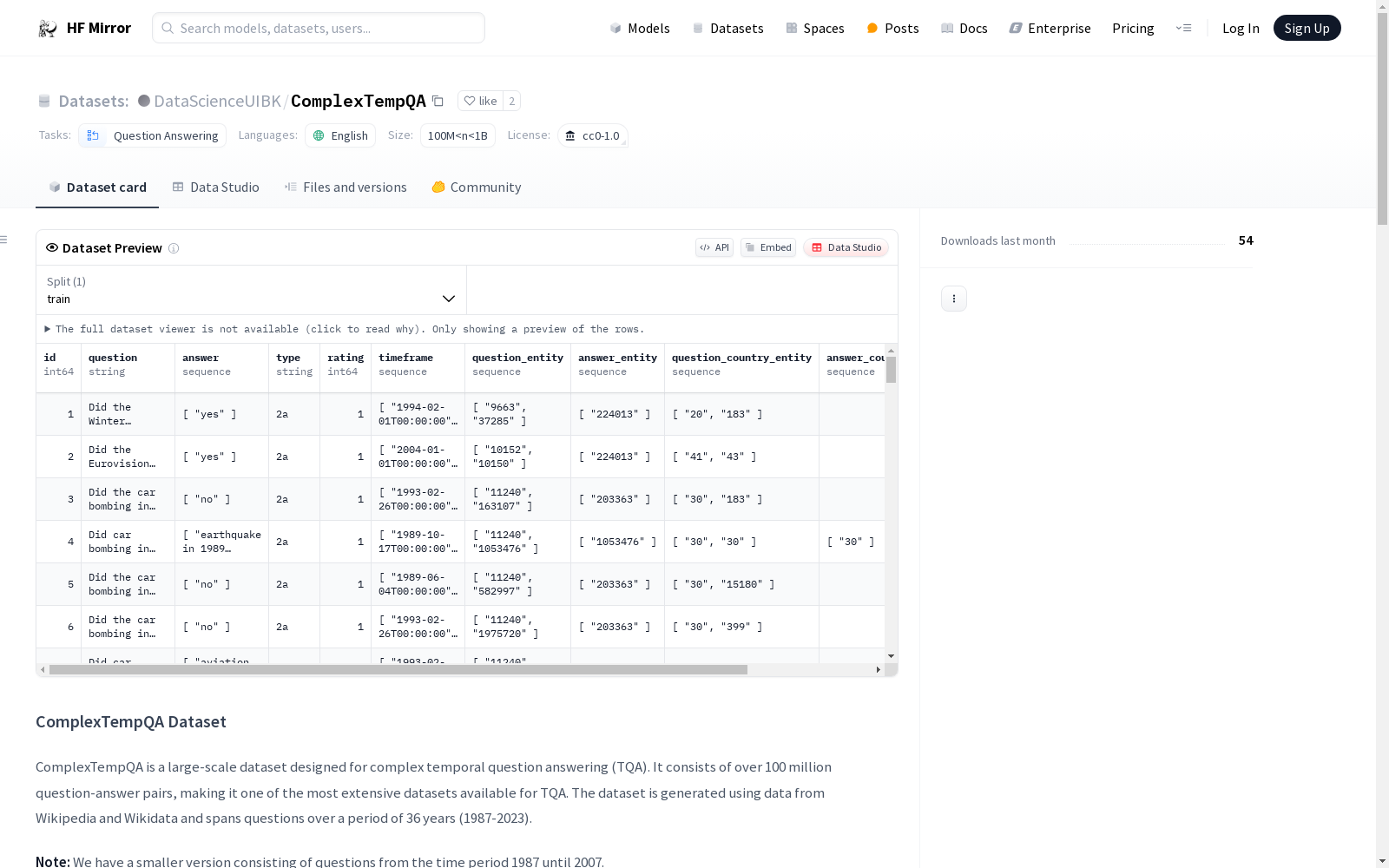
元数据
- id: 每个问题的唯一标识符。
- question: 问题的文本。
- answer: 问题的答案。
- type: 根据数据集分类法的问题类型。
- rating: 问题的难度评级(
0表示简单,1表示困难)。 - timeframe: 问题相关的时间范围。
- question_entity: 与问题中实体相关的 Wikidata ID 列表。
- answer_entity: 与答案中实体相关的 Wikidata ID 列表。
- question_country: 与问题中实体或事件相关的国家 Wikidata ID 列表。
- answer_country: 与答案中实体或事件相关的国家 Wikidata ID 列表。
- is_unnamed: 指示问题是否包含隐式描述的事件(
1表示是,0表示否)。
数据集特征
大小
ComplexTempQA 包含超过 1 亿个问答对,重点关注 1987 年至 2023 年间的事件、实体和时间段。
复杂性
问题需要高级推理技能,包括多跳问答、时间聚合和跨时间比较。
分类法
数据集遵循独特的分类法,将问题分为属性、比较和计数类型,确保全面覆盖时间查询。
评估
数据集已评估可读性、网络搜索前后的回答难易程度以及整体清晰度。人工评分员评估了部分问题,以确保高质量。
用途
评估和训练
ComplexTempQA 可用于:
- 评估大型语言模型(LLMs)的时间推理能力
- 微调语言模型以提高时间理解能力
- 开发和测试检索增强生成(RAG)系统
研究应用
数据集支持以下研究:
- 时间问答
- 信息检索
- 语言理解
适应和持续学习
ComplexTempQA 的时间元数据有助于开发在线适应和持续训练方法,促进时间基础学习和评估的探索。
搜集汇总
数据集介绍
构建方式
ComplexTempQA数据集的构建,是基于Wikipedia和Wikidata的海量数据,通过精心设计的问题-答案对形式,覆盖了从1987年至2023年间的历史事件、实体和时间跨度。该数据集通过三种主要问题类型——属性问题、比较问题和计数问题,进一步细分为与事件、实体或时间相关的子类型,形成了超过一亿的问题-答案对,旨在为复杂时间问题回答任务提供全面的数据支持。
特点
ComplexTempQA数据集以其庞大的规模、复杂的问题类型和详尽的元数据而显著。它不仅包含大量的问题-答案对,而且这些问题在复杂性上要求高级推理技能,包括多跳问题回答、时间聚合和跨时间比较。数据集采用独特的分类法,将问题分类为属性、比较和计数类型,确保了对时间查询的全面覆盖。此外,数据集经过人类评估,保证了高质量的问题和答案。
使用方法
用户可以通过访问数据集的GitHub页面来获取ComplexTempQA数据集和相应的代码。该数据集适用于评估大型语言模型的时序推理能力、微调语言模型以增强其时序理解能力,以及开发和测试检索增强生成系统。此外,其丰富的时序元数据为在线适应和持续训练语言模型提供了便利,有助于探索基于时间的学习和评估方法。
背景与挑战
背景概述
ComplexTempQA数据集,作为一项大规模的复杂时态问题回答(TQA)研究工具,诞生于对时间序列信息处理需求的深刻认识。该数据集由DataScienceUIBK团队开发,并在1987年至2023年的广阔时间跨度内,依托Wikipedia与Wikidata的海量数据,构建了包含超过一亿条问题-答案对。其旨在推动对事件、实体及时间周期相关问题的深入理解与应答,对自然语言处理领域产生了显著影响,特别是在时态理解与问题解答方面。
当前挑战
ComplexTempQA数据集面临的挑战主要在于其问题的复杂性与多样性,这要求模型具备高级推理能力,如多跳问答、时态聚合以及跨时间比较等。构建过程中,确保数据的准确性、问题的合理分布以及答案的相关性是另一大挑战。此外,如何高效利用数据集中的时态元数据,以支持在线适应与持续学习策略,对于提升大型语言模型在时态处理方面的能力至关重要。
常用场景
经典使用场景
在复杂时序问题回答的研究领域中,ComplexTempQA数据集以其庞大的规模和精细的类别划分,成为检验与训练大型语言模型时序推理能力的经典资源。研究者利用该数据集,对模型进行评估,以确定其在处理涉及事件、实体和时间跨度的复杂查询时的表现。
实际应用
实际应用中,ComplexTempQA数据集为信息检索、语言理解等领域提供了强有力的支持。通过该数据集,开发者能够构建更为智能的问答系统,服务于新闻分析、历史研究、事件追踪等多个场景,极大地提升了信息处理的效率和准确性。
衍生相关工作
ComplexTempQA数据集催生了一系列相关研究工作,包括但不限于对大型语言模型进行时序推理能力的评估、检索增强生成系统的开发,以及在线适应和持续训练方法的研究。这些工作进一步拓展了数据集的应用范围,为人工智能领域的发展贡献了重要力量。
以上内容由遇见数据集搜集并总结生成


