HinFakeNews
收藏Hugging Face2026-05-19 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/nitishs32/HinFakeNews
下载链接
链接失效反馈官方服务:
资源简介:
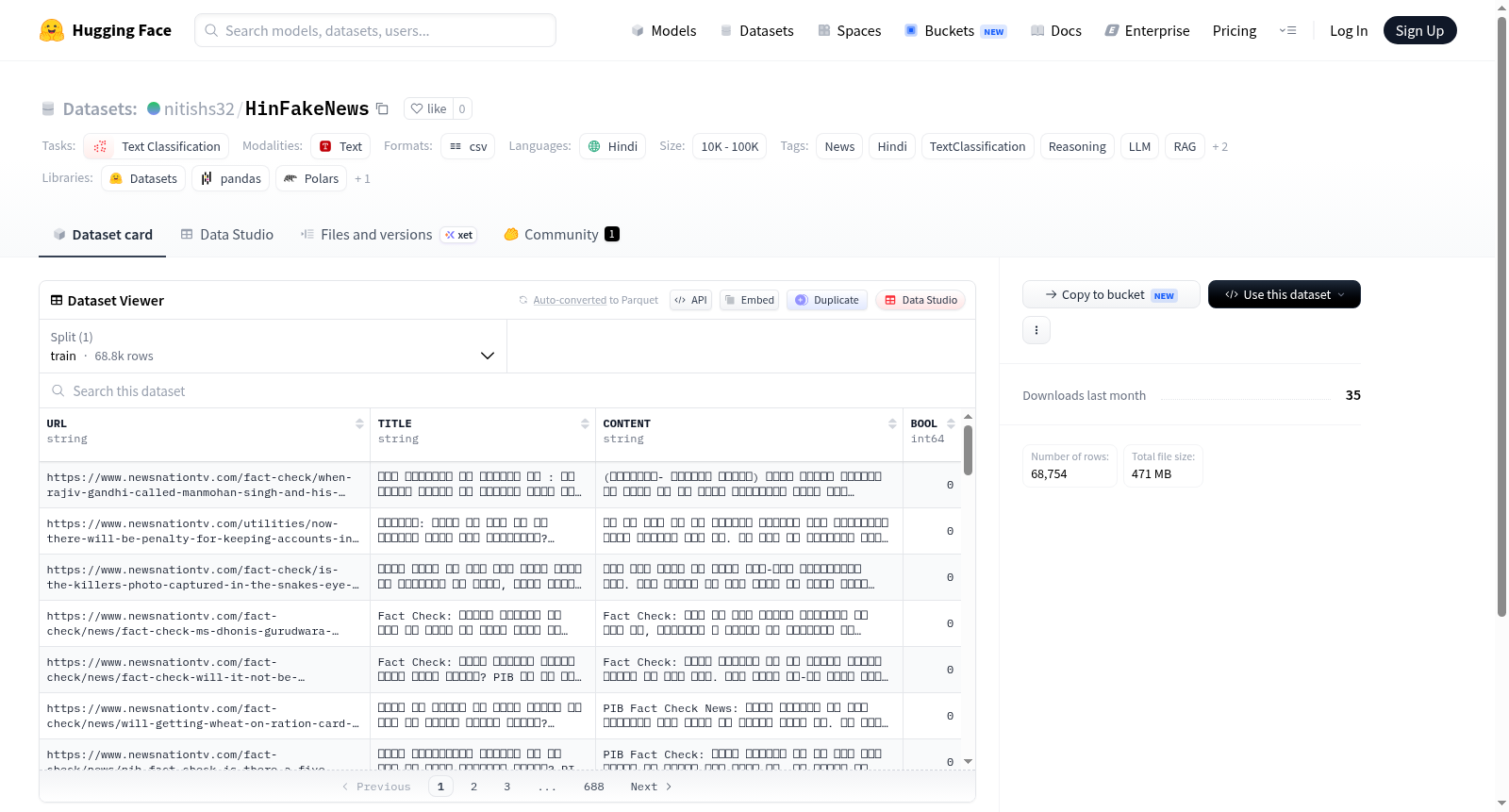
该数据集是一个印地语新闻文本分类数据集,专门用于假新闻检测等相关任务。数据规模在1万到10万样本之间,内容为印地语新闻文本。该数据集适用于文本分类、推理任务,并可用于大语言模型(LLM)、检索增强生成(RAG)以及嵌入技术的研究与开发。
This dataset is a Hindi news text classification dataset, specifically designed for tasks such as fake news detection. The data size ranges from 10,000 to 100,000 samples, with content consisting of Hindi news texts. It is suitable for text classification, inference tasks, and can be used for research and development in large language models (LLM), retrieval-augmented generation (RAG), and embedding technologies.
创建时间:
2026-05-18
搜集汇总
数据集介绍
构建方式
HinFakeNews数据集的构建立足于印地语新闻领域的虚假信息检测需求,通过系统性地收集与标注来自多个印地语新闻源的文本样本,确保数据覆盖真实与虚假新闻的多元场景。构建过程中,研究团队采用人工审核与自动化工具相结合的方式,对新闻内容进行严格筛选与分类,最终形成包含数万条标注样本的高质量语料库。数据集的设计强调类别平衡与文本多样性,以支持文本分类任务的稳健训练。
特点
HinFakeNews数据集的核心特点在于其专注于印地语虚假新闻的细粒度分类,涵盖新闻文本、推理线索与嵌入向量等多维信息。数据集规模介于10K至100K之间,兼顾了数据丰富性与管理效率,尤其适用于低资源语言场景下的自然语言处理研究。此外,其标签系统整合了文本分类与推理属性,为基于检索增强生成(RAG)和大型语言模型(LLM)的进阶应用提供了坚实基础。
使用方法
该数据集主要用于文本分类任务,研究人员可直接加载标签列进行模型训练与评估。在实践应用中,可利用其新闻文本与推理属性,结合嵌入特征构建高效的虚假新闻检测系统。建议采用预训练语言模型进行微调,并结合RAG技术增强检索相关性。数据集的公开格式支持直接导入主流机器学习框架,便于集成到端到端的自然语言处理流程中。
背景与挑战
背景概述
HinFakeNews数据集诞生于虚假信息泛滥的数字时代,由专注于印地语自然语言处理的研究团队创建,旨在应对印度语系中日益严峻的假新闻识别挑战。该数据集聚焦于文本分类任务,涵盖印地语新闻样本,规模介于1万至10万条之间,为低资源语言下的虚假信息检测研究提供了宝贵的资源。其核心研究问题在于如何有效利用语言模型、检索增强生成(RAG)及嵌入技术等手段,精准识别印地语新闻的真伪。自发布以来,HinFakeNews在推动多语言假新闻研究领域产生了重要影响,尤其为印地语文本的深度分析与推理任务奠定了数据基础。
当前挑战
HinFakeNews所解决的领域问题在于,现有假新闻检测方法多集中于英语等资源丰富的语言,印地语等低资源语言面临标注数据稀缺、语言结构复杂及文化语境多样性的挑战。构建过程中,研究团队需克服印地语新闻来源的广泛性与多样性,确保数据集涵盖不同领域和风格的样本,同时应对虚假信息定义的主观性与时效性。此外,如何通过推理、嵌入及RAG技术提升模型对印地语假新闻的泛化能力,成为当前研究中的核心难题。这些挑战不仅限制了数据集的规模与质量,也阻碍了其在真实场景中的实际应用效果。
常用场景
经典使用场景
HinFakeNews数据集专为印地语文本分类任务而设计,其核心应用在于虚假新闻检测。该数据集汇聚了数万条印地语新闻样本,覆盖了丰富的社会议题,使得研究者能够借助监督学习范式,训练出高效甄别虚假信息的分类模型。通过引入预训练语言模型(如BERT的印地语变体)进行微调,可显著提升模型对印地语语义的敏感度与分类精度。这一经典场景不仅验证了多语言自然语言处理的技术边界,更为低资源语言的新闻真实性判定提供了可复现的基准测试平台。
实际应用
在实际应用中,HinFakeNews赋能了面向印度本土的内容审核平台、社交媒体监控工具及新闻聚合服务的可信度预警系统。媒体机构可借助基于该数据集训练的模型,自动筛查印地语新闻文章中的不实信息,降低人工审核成本。此外,该数据集还可用于开发面向公众的浏览器插件或移动应用,辅助用户快速识别潜在的虚假新闻,从而在信息传播链的源头阻断误导性内容的扩散,维护数字空间的公共信任。
衍生相关工作
基于HinFakeNews数据集,衍生出一系列印地语虚假新闻检测的经典工作。研究者通过对比不同嵌入方法(如Word2Vec与BERT)的表现,揭示了上下文感知特征在低资源语言中的优势;亦有工作将检索增强生成(RAG)与分类网络结合,提升了模型对时效性新闻的适应能力。此外,该数据集被用于跨语言迁移学习的实验,探索从高资源语言(如英语)向印地语的知识蒸馏策略,为多语种虚假信息治理提供了理论支撑与技术路线。
以上内容由遇见数据集搜集并总结生成


