Kiria-Nozan/TRIM-gpt-5.4-mini-single-mol-only
收藏Hugging Face2026-05-01 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/Kiria-Nozan/TRIM-gpt-5.4-mini-single-mol-only
下载链接
链接失效反馈官方服务:
资源简介:
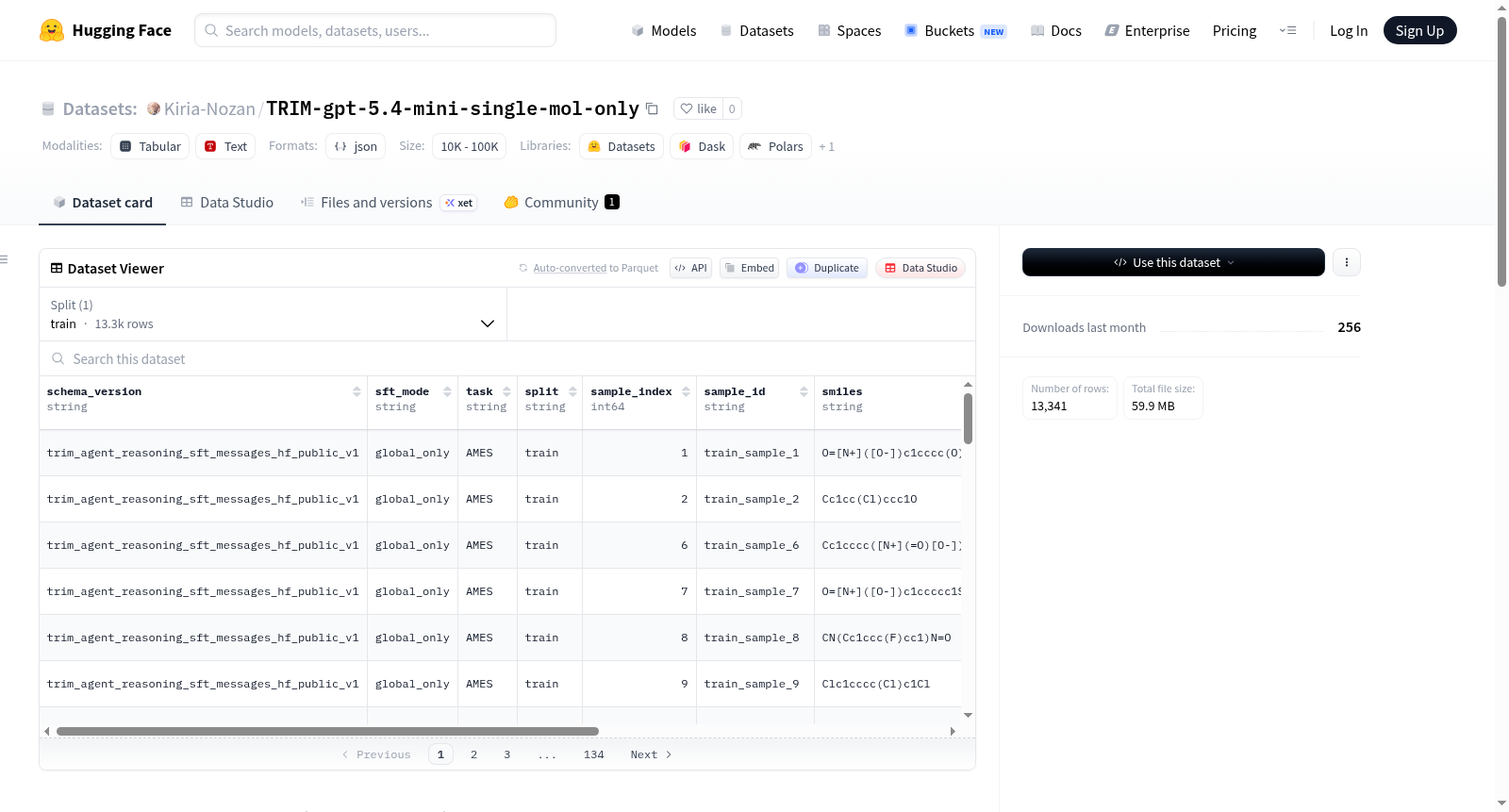
该目录是TRIM agent reasoning SFT数据的Hugging Face友好公开导出。数据由openrouter提供,使用了openai/gpt-5.4-mini模型,SFT模式为global_only。数据集包含train拆分,共有13341条记录,涵盖了多个任务领域,如AMES、BBB_Martins、Bioavailability_Ma等。每条记录是一个JSONL格式的训练示例,包含多个字段,如schema_version、sft_mode、task等,其中messages字段存储了工具增强的聊天记录。数据集经过了公开清洗,移除了本地绝对路径,任务级别的导出元数据存储在metadata/manifest.json中。
This directory is a Hugging Face-friendly public export of the TRIM agent reasoning SFT data. The data is provided by openrouter, using the openai/gpt-5.4-mini model, with SFT mode as global_only. The dataset includes the train split, with a total of 13341 records, covering multiple task areas such as AMES, BBB_Martins, Bioavailability_Ma, etc. Each record is a JSONL-formatted training example containing multiple fields such as schema_version, sft_mode, task, etc., with the messages field storing the tool-augmented chat transcript. The dataset has been publicly sanitized, removing local absolute paths, and task-level export metadata is stored in metadata/manifest.json.
提供机构:
Kiria-Nozan
搜集汇总
数据集介绍
构建方式
TRIM-gpt-5.4-mini-single-mol-only 数据集源自 TRIM 智能体推理系统,采用 OpenAI 的 GPT-5.4-mini 模型通过 OpenRouter 服务生成,专为单分子属性预测任务设计。其构建基于全局 SFT 模式(global_only),从原始智能体推理对话中提取并整理训练示例。每条记录以 JSONL 格式存储,包含标准化字段如 schema_version、task、smiles、gt_label 及 messages,其中 messages 字段记录了带有工具调用的完整对话转录,保留了模型的推理链和最终答案选择。数据集当前仅包含 train 拆分,共 13341 条记录,覆盖 16 项生物活性与毒性预测任务,如 AMES 致癌性、CYP 代谢酶底物、hERG 心脏毒性等。
使用方法
该数据集可通过 Hugging Face Datasets 库直接加载,使用 load_dataset 函数并指定 JSON 数据源即可获取 train 拆分中的全部记录。每条样本可直接解析为字典对象,支持通过 task 字段按 16 种分子属性预测任务进行筛选。messages 字段内的工具增强对话记录可通过 JSON 解析还原,适用于构建基于大语言模型的分子属性预测训练流程,或在原有 SFT 基础上引入推理链信息进行更细粒度的模型微调。用户亦可利用 sample_id 和 split 字段追溯样本来源,结合 gt_label 与 final_answer_option 进行监督学习实验。
背景与挑战
背景概述
TRIM-gpt-5.4-mini-single-mol-only数据集于近年来由OpenRouter与OpenAI团队联合构建,聚焦于将大型语言模型(LLM)的推理能力与分子药物发现任务深度融合。该数据集以GPT-5.4-mini模型生成的工具增强型对话轨迹为核心,涵盖AMES、CYP450亚型底物预测、Pgp转运体活性以及SARS-CoV-2抗病毒活性等20余项关键药物化学任务,旨在解决分子属性预测中知识图谱缺失与推理链条断裂的难题。作为首个大规模单分子推理监督微调(SFT)数据集,其发布推动了AI在药物研发领域的范式革新,为智能分子筛选与靶向药物设计提供了高质量的基准数据支撑。
当前挑战
该数据集面临的核心挑战在于两层面:领域问题上,分子属性预测长期受限于特征稀疏性与实验标签噪声,传统机器学习方法难以捕捉分子结构与生物活性间的复杂非线性关系,尤其在CYP代谢、hERG心脏毒性等高风险预测任务中泛化能力不足;构建过程中,多代理系统需平衡13000余条样本的合成逻辑与化学有效性,同时避免模型在工具调用环节产生虚假关联或过拟合特定任务模式。此外,跨任务知识迁移时,语言模型对SMILES字符串的语义理解偏差与思维链生成的连贯性仍是制约模型稳健性的关键瓶颈。
常用场景
经典使用场景
TRIM-gpt-5.4-mini-single-mol-only数据集在药物发现与分子信息学领域中扮演着关键基准的角色,尤其适用于训练和评估基于分子结构(SMILES表示)的推理与预测模型。该数据集汇集了来自17项不同分子性质预测任务的13341条样本,涵盖了药物代谢动力学、毒性预测、生物活性评估等多个维度,例如hERG心脏毒性、CYP450酶底物特异性、血脑屏障穿透能力以及口服生物利用度等经典ADMET属性。其独特的‘TRIM Agent Reasoning’对话结构,不仅包含分子标签与最终答案,还记录了智能体在工具增强环境下的推理链条,使得该数据集成为少样本学习、思维链推理以及大语言模型在化学领域应用的研究沃土。
解决学术问题
该数据集有效解决了化学信息学与计算制药领域中数据孤岛与推理可解释性的双重难题。传统上,分子性质预测依赖独立的任务专有模型,缺乏跨任务迁移能力与推理过程的透明度。TRIM数据集通过统一的交互式推理格式,促使学术界有望构建出能够同时理解分子结构、执行多步推理并解释决策依据的统一智能体模型。它推动了从简单的分类回归范式向工具增强式推理范式的转变,尤其攻克了小样本学习在药物分子毒性预测与代谢稳定性评估中的瓶颈,为构建更安全、更高效的候选药物筛选流水线提供了理论与实验支持。
实际应用
在实际场景中,该数据集可为制药企业的早期药物研发管线提供智能化决策支持。制药科学家可以利用基于该数据集训练的语言智能体,快速对虚拟筛选出的候选化合物进行多维度ADMET性质预测,无需为每个性质独立配置不同的预测模型。例如,在药物先导化合物优化阶段,智能体能够根据分子SMILES输入,自动调用内部知识库与外部工具,依次评估其CYP酶代谢风险、hERG心脏毒性以及口服生物利用度,并生成结构化的解释报告。此外,该数据集还支持对已上市药物的副作用回溯分析,帮助临床安全团队识别潜在的未知不良反应信号,加速药物警戒流程。
数据集最近研究
最新研究方向
TRIM-gpt-5.4-mini-single-mol-only数据集聚焦于药物化学领域的分子属性预测任务,利用GPT-5.4-mini模型生成的代理推理对话数据,驱动小分子在ADMET(吸收、分布、代谢、排泄、毒性)及生物活性评估中的前沿研究。该数据集涵盖了17个关键任务,如hERG安全性、CYP450代谢稳定性、血脑屏障渗透性及SARS-CoV-2抗病毒活性等,紧密关联当前AI辅助药物发现的热点事件——即通过大语言模型模拟专家推理流程以替代传统实验筛选。其意义在于提供了标准化、可复现的工具增强型监督微调(SFT)样本,推动了从分子表征到智能推理的范式转变,加速了候选分子在临床前阶段的精准评估,显著提升了高通量虚拟筛选的效率和可靠性。
以上内容由遇见数据集搜集并总结生成


