PROVE
收藏Hugging Face2024-10-24 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Salesforce/PROVE
下载链接
链接失效反馈官方服务:
资源简介:
PROVE是一个用于评估视觉语言模型(VLM)对开放式查询响应的基准测试。它通过提供一个大型语言模型(LLM)与高保真场景图表示,生成多样化的问答对和可执行的程序来验证每个问答对,从而构建了一个包含10.5k个具有视觉基础的挑战性问答对的基准。数据集还介绍了如何使用PROVE进行模型评估,并提供了一个排行榜来展示不同模型在PROVE上的表现。
PROVE is a benchmark dedicated to evaluating open-ended query responses of Vision-Language Models (VLMs). It hosts 10.5k visually grounded challenging question-answer pairs, which are generated by leveraging a Large Language Model (LLM) and high-fidelity scene graph representations to produce diverse QA pairs and executable programs for validating each individual QA pair. The dataset also introduces the workflow for utilizing PROVE to evaluate models, and provides a leaderboard to showcase the performance of different models on the PROVE benchmark.
提供机构:
Salesforce
创建时间:
2024-10-18
原始信息汇总
PROVE 数据集概述
基本信息
- 许可证: Apache 2.0
- 语言: 英语
- 配置:
- 名称: default
- 数据文件:
- 分割: test
- 路径: prove.json
数据集描述
- 名称: Programmatic VLM Evaluation (PROVE)
- 目标: 评估视觉语言模型(VLM)对开放式查询的响应,量化响应中的幻觉效应。
- 构建方法: 使用大型语言模型(LLM)生成多样化的问答(QA)对,并通过场景图对象执行程序来验证每个QA对。
- 规模: 包含10.5k个具有视觉基础的挑战性QA对。
评估方法
- 策略: 基于场景图的程序化评估策略,测量响应的有用性和真实性。
- 模型评估: 评估多个VLM在PROVE上的有用性和真实性权衡。
快速开始
-
安装: bash conda create -n prove python=3.10 conda activate prove; pip3 install -r requirements.txt;
-
使用: bash python evaluate.py --vlm <vlm_name> --response_json <response_json_path> --scores_path <output_json_path>
排行榜
| 模型 | hscore | tscore | average |
|---|---|---|---|
| Qwen2 (2b) | 69.36 | 80.64 | 75.0 |
| Intern-VL2 (2b) | 73.96 | 79.51 | 76.74 |
| Phi-3.5-vision (4B) | 73.35 | 82.27 | 77.81 |
| LLaVA-1.5 (7B) | 72.67 | 82.58 | 77.62 |
| llava-next (7b) | 74.28 | 80.03 | 77.15 |
| Intern-VL2 (8b) | 74.55 | 80.56 | 77.56 |
| pixtral (12b) | 73.34 | 82.43 | 77.88 |
| llava-1.5 (13b) | 72.46 | 82.4 | 77.43 |
| Intern-VL2 (26b) | 74.63 | 79.23 | 76.93 |
| claude3.5-sonnet | 71.06 | 77.31 | 74.19 |
| gpt-4o-mini | 73.18 | 79.24 | 76.21 |
| gemini-1.5-flash | 72.73 | 81.74 | 77.23 |
| gpt-4o | 76.53 | 80.92 | 78.72 |
引用
@misc{prabhu2024prove, title={Trust but Verify: Programmatic VLM Evaluation in the Wild}, author={Viraj Prabhu and Senthil Purushwalkam and An Yan and Caiming Xiong and Ran Xu}, year={2024}, eprint={2410.13121}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2410.13121}, }
搜集汇总
数据集介绍
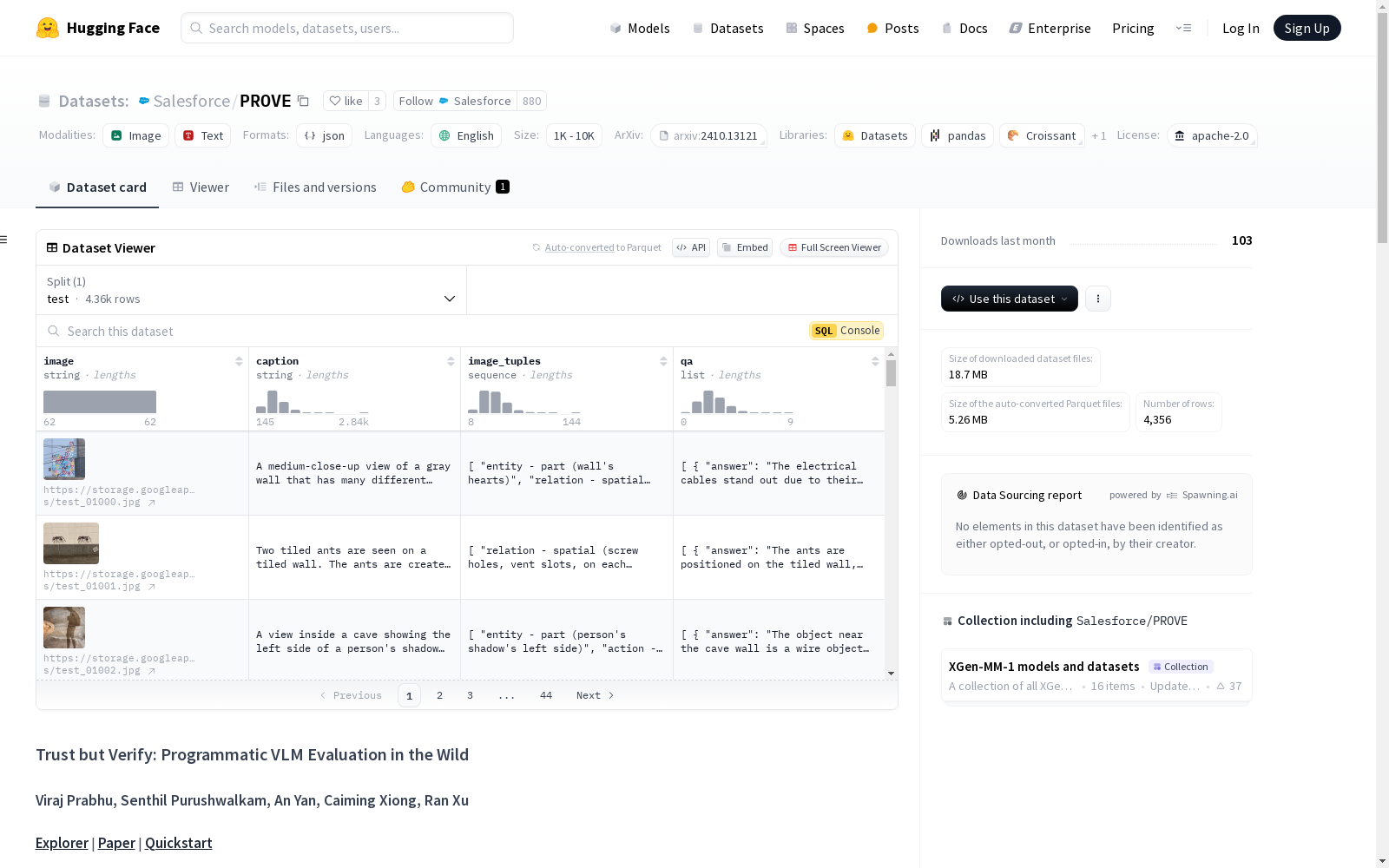
构建方式
在视觉语言模型(VLMs)领域,生成看似合理但实际错误的响应是一个常见问题。为了量化这种幻觉效应,PROVE数据集通过提供高保真场景图表示,利用大语言模型(LLM)生成多样化的问答对(QA pairs),并设计可执行的程序来验证每个问答对的正确性。最终构建了一个包含10.5k个具有视觉基础的问答对的基准数据集。
使用方法
使用PROVE数据集进行VLMs评估时,首先需要生成对prove.json中问答对的响应,并将其保存为指定格式的JSON文件。随后,通过运行evaluate.py脚本,输入模型名称、响应文件路径和输出分数路径,即可获得模型在帮助性和真实性上的评分。这一流程使得研究者能够便捷地比较不同模型在PROVE基准上的表现。
背景与挑战
背景概述
在视觉-语言模型(VLMs)的研究领域,模型在生成对视觉查询的响应时,常常产生看似合理但实际错误的回答。为了量化这种幻觉效应,研究人员需要一种可靠的方法来验证每个响应中的声明。2024年,Salesforce AI Research的研究团队提出了PROVE(Programmatic VLM Evaluation)这一新的基准测试范式,旨在评估VLMs对开放式查询的响应。PROVE通过提供高保真场景图表示,并利用大语言模型(LLM)生成多样化的问答对及验证程序,构建了一个包含10.5k个具有挑战性但视觉上可验证的问答对的基准。该数据集不仅推动了VLMs在生成响应时的真实性和帮助性之间的平衡研究,还为相关领域的模型评估提供了新的方法论。
当前挑战
PROVE数据集在构建和应用过程中面临多重挑战。首先,视觉-语言模型在生成开放式查询响应时,往往难以避免幻觉现象,即生成看似合理但实际错误的内容。如何准确量化这种幻觉效应,是PROVE试图解决的核心问题。其次,在数据集的构建过程中,研究人员需要确保生成的问答对在视觉上具有可验证性,这要求对高保真场景图进行精细的标注和处理。此外,PROVE采用程序化评估策略,要求模型在统一的场景图框架下同时评估响应的帮助性和真实性,这对模型的综合能力提出了更高的要求。最后,尽管PROVE为VLMs的评估提供了新的基准,但如何在更广泛的场景中推广和应用这一方法,仍是一个亟待解决的问题。
常用场景
经典使用场景
PROVE数据集在视觉-语言模型(VLM)评估领域具有重要应用。该数据集通过构建高保真场景图,生成多样化的问答对,并利用程序化方法验证每个问答对的准确性。这一方法使得PROVE成为评估VLM在开放式查询中生成响应的有效工具,特别是在衡量模型生成内容的真实性和有用性方面。
解决学术问题
PROVE数据集解决了视觉-语言模型在生成开放式查询响应时常见的幻觉问题。通过程序化评估策略,PROVE能够量化模型生成内容的真实性和有用性,从而帮助研究者更好地理解模型的表现。这一方法为VLM的评估提供了新的范式,推动了该领域的研究进展。
实际应用
在实际应用中,PROVE数据集被广泛用于评估和改进视觉-语言模型的性能。通过该数据集,开发者可以测试模型在复杂视觉场景中的表现,优化模型生成内容的准确性和可靠性。此外,PROVE还为模型在自动驾驶、智能客服等领域的应用提供了重要的评估依据。
数据集最近研究
最新研究方向
在视觉-语言模型(VLM)领域,PROVE数据集为评估模型在开放式查询中的响应提供了新的基准范式。通过结合大语言模型(LLM)和高保真场景图表示,PROVE生成了10.5k个具有挑战性但视觉上可验证的问答对。该数据集的前沿研究方向集中在程序化评估策略上,旨在统一场景图框架内衡量响应的帮助性和真实性。当前研究热点包括探索不同VLM在PROVE上的表现,特别是如何在帮助性和真实性之间取得平衡。这一研究不仅推动了VLM的评估方法创新,还为模型在实际应用中的可靠性提供了重要参考。
以上内容由遇见数据集搜集并总结生成


