MemeMind
收藏Hugging Face2025-05-28 更新2025-05-29 收录
下载链接:
https://huggingface.co/datasets/yubb66/MemeMind
下载链接
链接失效反馈官方服务:
资源简介:
MemeMind数据集是一个大规模的多模态数据集,用于有害梗图检测,包含40,000多个中英文样本,涵盖了歧视、冒犯、暴力、粗俗和不满意等多种有害内容类别。数据集通过提供链式思维注释来引导语言模型进行决策过程,旨在提高大型模型在多模态有害内容检测任务中的准确性和可解释性。
The MemeMind dataset is a large-scale multimodal dataset dedicated to harmful meme detection, comprising over 40,000 Chinese-English samples that cover a wide range of harmful content categories including discrimination, offense, violence, vulgarity, and dissatisfaction. The dataset provides chain-of-thought annotations to guide language models through their decision-making processes, with the goal of improving the accuracy and interpretability of large language models in multimodal harmful content detection tasks.
创建时间:
2025-05-28
原始信息汇总
MemeMind 数据集概述
数据集简介
- 名称:MemeMind
- 目的:支持基于推理的有害表情包检测模型开发
- 特点:提供思维链标注,增强模型决策过程的可解释性
- 规模:超过40,000个中英文样本
- 覆盖内容:歧视、冒犯、暴力、粗俗、不满等有害内容类别
数据来源
包含5个有害表情包相关数据集:
- MAMI(多媒体自动厌女识别)
- 来源:GitHub
- 引用:Elisabetta Fersini等,2022
- Facebook Hateful Memes(Facebook仇恨表情包)
- 来源:Hateful Memes Challenge
- 引用:Douwe Kiela等,2020
- HarMeme
- 来源:GitHub(MOMENTA项目)
- 引用:Shraman Pramanick等,2021
- MET-Meme
- 来源:Kaggle
- 引用:Bo Xu等,2022
- ToxiCN_MM(中文有害表情包)
- 来源:GitHub
- 引用:Junyu Lu等,2024
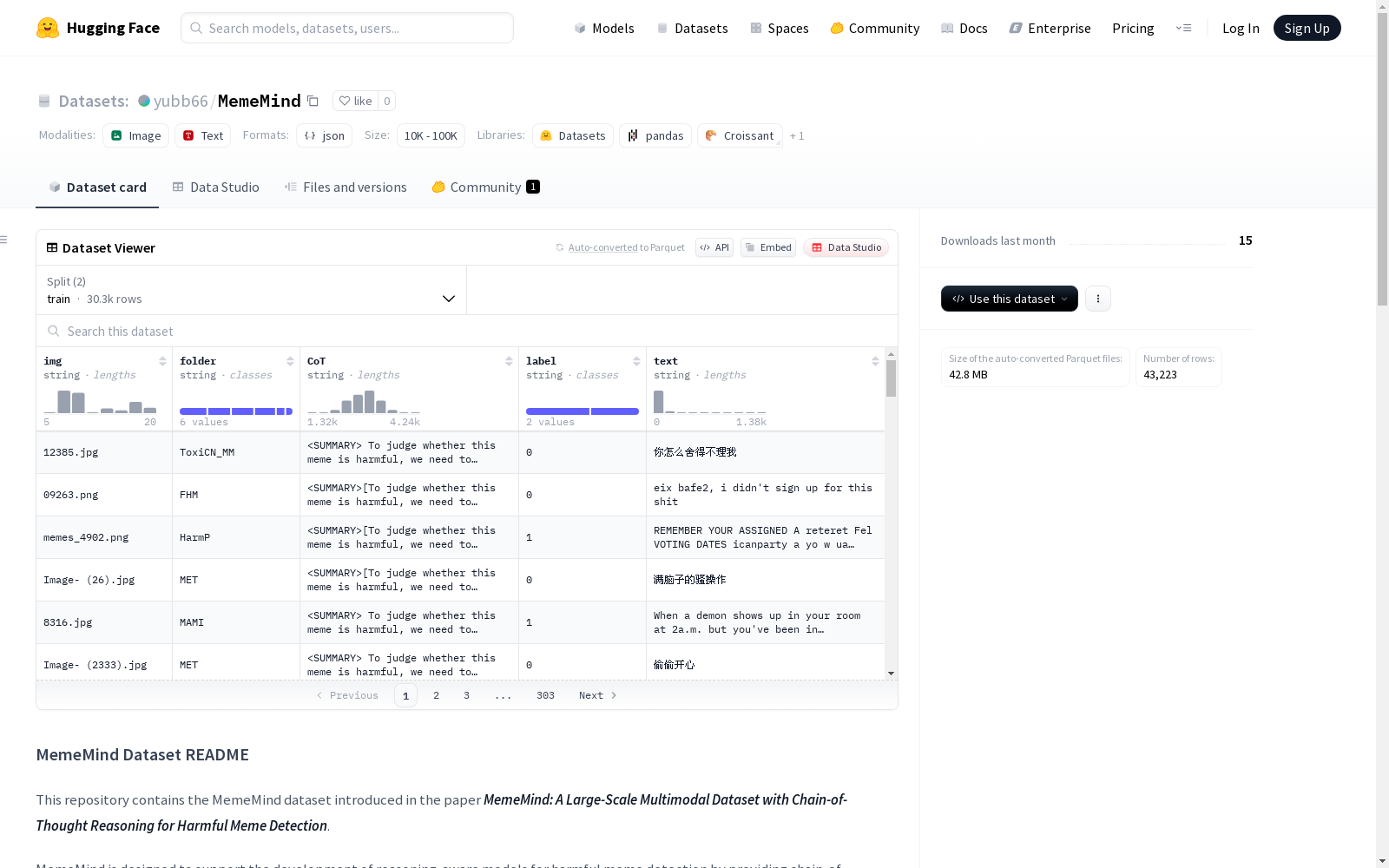
数据集结构
- 划分比例:70%训练集,30%测试集
- 样本字段:
img:图像文件名(如123.jpg)folder:图像存储路径text:表情包文本内容label:二元标签(0:无害,1:有害)CoT:思维链标注(结构化字典)
思维链标注结构
- SUMMARY:五类有害表情包的定义摘要
- CAPTION:表情包内容描述
- REASONING:结合内容与概念的逐步推理过程
- JUDGEMENT:最终判定结果("Harmful"或"Harmless")
数据质量控制
- 对五个源数据集进行严格筛选和精炼
- 确保五个预定义有害类别的代表性
- 调整有害与无害样本分布以达到平衡比例
搜集汇总
数据集介绍
构建方式
MemeMind数据集的构建过程体现了对多源异构数据的系统性整合。研究团队从五个权威的公开数据源(FHM、HarMeme、MAMI、MET和ToxiCN-MM)精选了43,223张图像样本,涵盖冒犯性内容、政治议题、疫情歧视等多个敏感领域。通过严格的筛选机制确保每类有害内容均符合预设的五大分类标准,并对有害/无害样本比例进行平衡处理,最终形成包含中英双语的双模态数据集。数据采集过程严格遵守版权规范,所有原始数据集均获得官方授权或来自开源平台。
特点
该数据集最显著的特征在于其创新的思维链标注体系。每个样本不仅包含基本的图像文件、文本内容和二元标签,还特别设计了结构化的思维链(CoT)注释,由摘要、内容描述、推理过程和最终判断四个逻辑模块组成。这种设计使模型能够模拟人类的渐进式推理过程,尤其适用于需要可解释性的有害内容检测场景。数据集覆盖歧视、冒犯、暴力等五大有害类别,70:30的训练测试划分比例也为模型开发提供了可靠基准。
使用方法
使用该数据集时,研究者可通过加载标准化的JSON格式样本获取完整的多模态信息。图像文件与文本内容的对应关系由folder和img字段明确指示,而CoT字段的层次化结构支持端到端或分阶段的模型训练策略。特别建议利用REASONING子字段开发具有解释能力的分类模型,该字段提供的逐步推理线索能有效提升模型在跨文化语境下的判断准确性。测试集的独立划分确保了评估结果的可靠性,适用于多模态分类、可解释性AI等研究方向。
背景与挑战
背景概述
MemeMind数据集由研究团队在2024年提出,旨在推动多模态有害表情包检测领域的发展。该数据集整合了来自五个公开数据集(FHM、HarMeme、MAMI、MET和ToxiCN-MM)的43,223个样本,涵盖中英双语环境下的歧视、冒犯、暴力、粗俗和不满等五大有害内容类别。其创新性在于引入了思维链(Chain-of-Thought)标注机制,通过显式建模推理过程,提升大模型在多模态有害内容检测中的准确性与可解释性。该数据集由多个国际知名研究机构联合构建,包括Facebook Research、IIIT-Delhi等,相关成果发表于顶级学术会议,为社交媒体内容安全领域提供了重要的基准资源。
当前挑战
MemeMind数据集面临双重挑战。在领域问题层面,多模态有害内容检测需克服视觉-文本语义鸿沟,尤其是隐喻、反讽等复杂修辞的识别;同时,文化差异导致中英文语境下有害性判定标准存在显著分歧。在构建过程中,数据整合涉及异构标注体系的统一,需人工复核五类有害内容的边界定义;思维链标注要求标注者具备跨模态推理能力,导致标注成本激增。此外,平衡数据分布时,非有害样本的稀缺性可能影响模型泛化性能。
常用场景
经典使用场景
在社交媒体内容审核领域,MemeMind数据集因其多模态特性和思维链标注而成为有害表情包检测研究的基准工具。该数据集通过整合五种不同来源的子数据集,覆盖了歧视、冒犯、暴力等多元化的有害内容类别,为研究者提供了丰富的跨语言、跨文化研究素材。其独特的思维链标注机制能够引导模型进行可解释的推理过程,使得该数据集特别适用于探索多模态大模型在复杂语义理解任务中的表现。
衍生相关工作
基于MemeMind的创新研究催生了多个重要方向的发展,包括多模态思维链蒸馏技术、跨文化有害内容迁移学习框架等。其标注范式被AdaptiCOT等后续工作扩展应用于虚假信息检测领域,而数据集构建方法则为MM-Reason等新型基准的建立提供了范本。相关成果在ACL、ICML等顶会形成了专门的研究脉络,持续推动着可解释多模态推理的技术前沿。
数据集最近研究
最新研究方向
在数字媒体与社交网络快速发展的背景下,多模态有害内容检测成为人工智能领域的重要研究方向。MemeMind数据集通过引入链式思维(Chain-of-Thought)标注机制,为研究者提供了理解模型决策过程的窗口,显著提升了有害模因检测的可解释性。当前研究聚焦于如何利用该数据集的多语言特性(中英文)和细粒度分类(歧视、冒犯、暴力等)优化多模态大模型的推理能力,特别是在跨文化语境下的泛化性能。近期相关热点包括社交媒体平台对AI内容审核系统的迫切需求,以及欧盟《数字服务法案》对透明算法的强制要求,这些趋势进一步凸显了MemeMind在构建可信AI系统中的实践价值。该数据集通过整合五个权威子集并保持类别平衡,为探索多模态表征学习与因果推理的结合提供了理想实验平台。
以上内容由遇见数据集搜集并总结生成


