LinCE 语言转换数据集
收藏超神经2022-10-27 更新2024-05-15 收录
下载链接:
https://hyper.ai/cn/datasets/20385
下载链接
链接失效反馈官方服务:
资源简介:
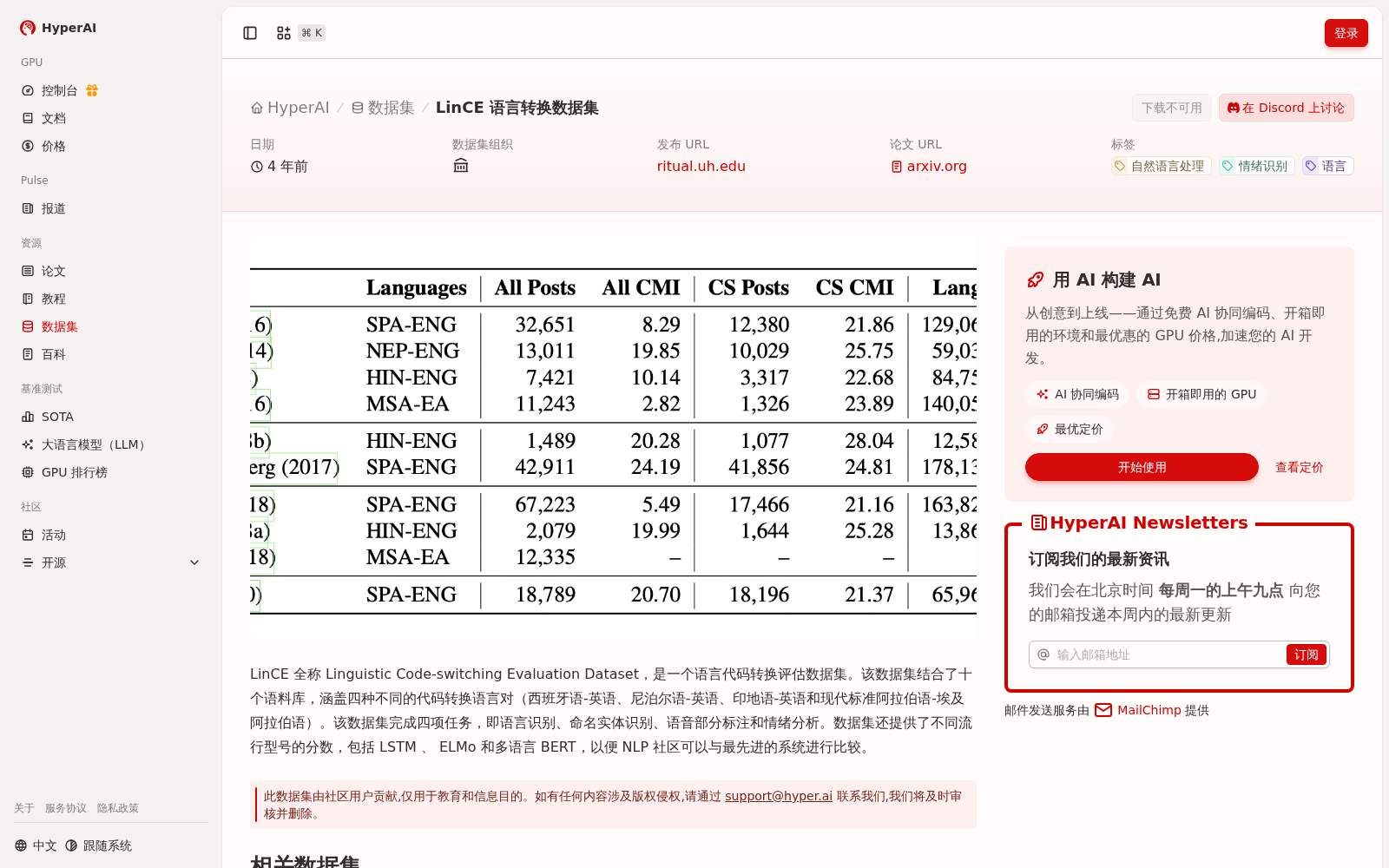
LinCE 全称 Linguistic Code-switching Evaluation Dataset,是一个语言代码转换评估数据集。该数据集结合了十个语料库,涵盖四种不同的代码转换语言对(西班牙语-英语、尼泊尔语-英语、印地语-英语和现代标准阿拉伯语-埃及阿拉伯语)。该数据集完成四项任务,即语言识别、命名实体识别、语音部分标注和情绪分析。数据集还提供了不同流行型号的分数,包括 LSTM 、 ELMo 和多语言 BERT,以便 NLP 社区可以与最先进的系统进行比较。
LinCE, short for Linguistic Code-switching Evaluation Dataset, is a benchmark dataset for code-switching evaluation in natural language processing. It integrates ten corpora and covers four distinct code-switched language pairs: Spanish-English, Nepali-English, Hindi-English, and Modern Standard Arabic-Egyptian Arabic. The dataset supports four core tasks, namely language identification, named entity recognition, part-of-speech tagging, and sentiment analysis. Additionally, it provides benchmark scores from several popular models including LSTM, ELMo, and multilingual BERT, enabling the NLP community to compare their systems with state-of-the-art baselines.
创建时间:
2022-10-27
搜集汇总
数据集介绍
背景与挑战
背景概述
LinCE语言转换数据集是一个用于评估语言代码转换的数据集,整合了十个语料库,涵盖西班牙语-英语等四种语言对,支持语言识别、命名实体识别等四项自然语言处理任务。该数据集还提供了LSTM、ELMo等流行模型的基准分数,便于与先进系统进行比较。
以上内容由遇见数据集搜集并总结生成


