Conceptual Captions Dataset (CC12M) 概念数据集
收藏超神经2024-02-06 更新2024-05-15 收录
下载链接:
https://hyper.ai/cn/datasets/14682
下载链接
链接失效反馈官方服务:
资源简介:
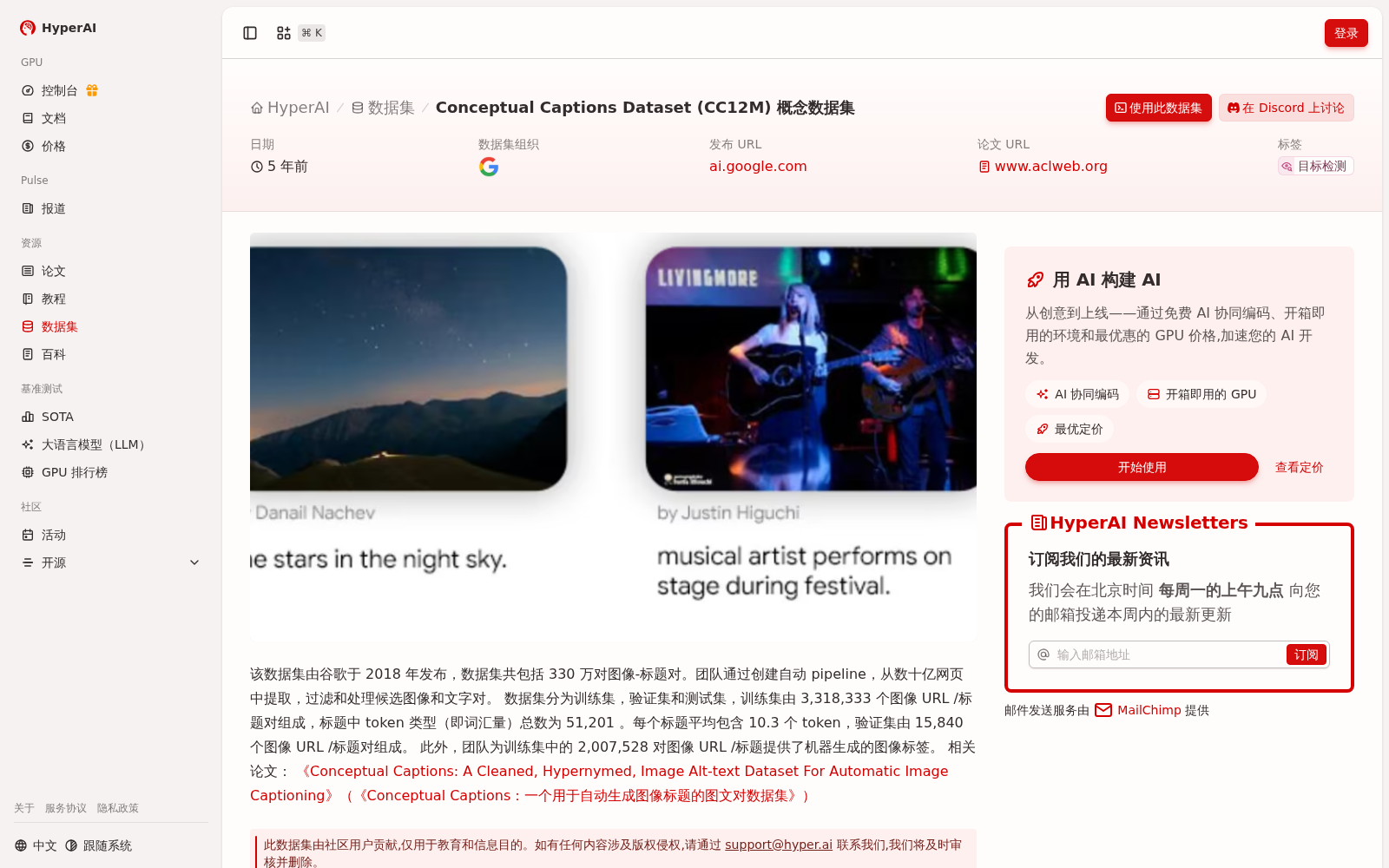
该数据集由谷歌于 2018 年发布,数据集共包括 330 万对图像-标题对。团队通过创建自动 pipeline,从数十亿网页中提取,过滤和处理候选图像和文字对。
This dataset was released by Google in 2018, containing a total of 3.3 million image-caption pairs. The team developed an automated pipeline to extract, filter, and process candidate image-text pairs from billions of web pages.
创建时间:
2021-03-02
搜集汇总
数据集介绍
背景与挑战
背景概述
Conceptual Captions Dataset (CC12M) 是谷歌于2018年发布的一个概念数据集,包含约330万对从网页自动提取的图像-标题对,其中训练集有超过331万对,验证集有1.5万对,标题平均包含10.3个token。该数据集旨在支持自动图像标题生成任务,并附有相关论文介绍其清洗和超类化处理过程。
以上内容由遇见数据集搜集并总结生成


