IPEval
收藏arXiv2024-06-18 更新2024-06-20 收录
下载链接:
https://github.com/Mathsion2/IPEval
下载链接
链接失效反馈官方服务:
资源简介:
IPEval是大连理工大学未来技术学院创建的首个双语知识产权机构咨询评估基准数据集,包含2657道多选题,涵盖知识产权的创造、应用、保护和管理四个主要能力维度。数据集来源于美国专利商标局和中国国家知识产权局的历史专利律师考试,旨在评估大型语言模型在知识产权领域的理解和推理能力。该数据集不仅关注知识产权法律的理解,还涉及知识产权活动的认知识别和应用程序,适用于评估模型在处理不同地区和语言问题时的能力。IPEval的建立旨在推动具有更强知识产权能力的专业大型语言模型的发展。
IPEval is the first bilingual intellectual property (IP) institutional consultation and evaluation benchmark dataset developed by the School of Future Technology, Dalian University of Technology. It contains 2,657 multiple-choice questions, covering four core competency dimensions: IP creation, application, protection, and management. The dataset is sourced from the historical patent bar examinations of the United States Patent and Trademark Office (USPTO) and the China National Intellectual Property Administration (CNIPA), aiming to evaluate the understanding and reasoning capabilities of large language models (LLMs) in the intellectual property domain. Beyond focusing on the comprehension of IP laws, the dataset also involves cognitive recognition and application of IP-related activities, and is suitable for assessing a model's ability to handle issues across different regions and languages. The establishment of IPEval is intended to promote the development of professional large language models with stronger intellectual property capabilities.
提供机构:
大连理工大学未来技术学院
创建时间:
2024-06-18
搜集汇总
数据集介绍
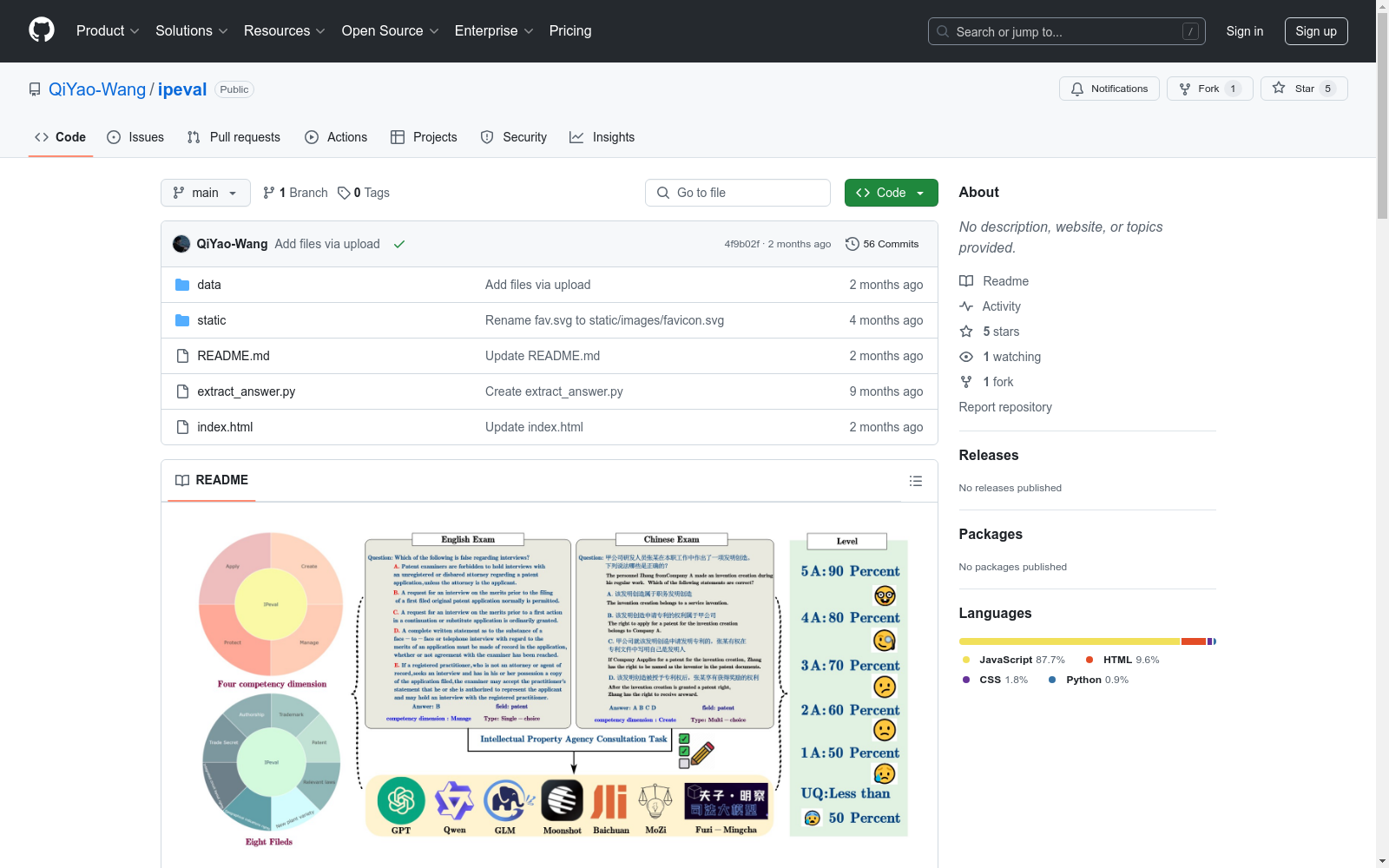
构建方式
IPEval数据集的构建基于美国专利商标局(USPTO)和中国国家知识产权局(CNIPA)的专利代理人资格考试题目。通过从2012年至2019年的中国专利代理人资格考试和1997年至2003年的美国专利代理人资格考试中收集双语选择题,确保了数据的权威性和时效性。数据经过多轮手动验证和清理,确保其结构化和高质量。数据集涵盖了知识产权的四个主要能力维度:创造、应用、保护和管理,并进一步细分为八个领域,包括专利、商标、版权等。
特点
IPEval数据集包含2657道双语选择题,涵盖知识产权的多个领域和能力维度。其独特之处在于其区域性和时效性,数据来自不同国家和不同年份的考试题目,确保了模型在知识产权咨询任务中对不同地区法律和动态变化的理解能力。此外,数据集通过多轮手动验证和清理,确保了数据的准确性和一致性,避免了数据泄露和错误。
使用方法
IPEval数据集主要用于评估大型语言模型在知识产权领域的理解、应用和推理能力。通过三种提示策略(零样本、5样本和思维链)对模型进行评估,确保模型在不同情境下的表现得到全面测试。数据集的使用方法包括对模型进行多维度评估,涵盖不同能力维度、领域和时间段的表现。此外,数据集的开源特性使得研究人员可以将其作为训练数据或评估基准,进一步优化和开发具有更强知识产权能力的模型。
背景与挑战
背景概述
IPEval数据集由大连理工大学的研究团队于2024年提出,旨在评估大语言模型(LLMs)在知识产权(IP)领域的理解、应用和推理能力。该数据集包含2657道中英文选择题,涵盖知识产权的四大能力维度:创造、应用、保护和管理,涉及专利、商标、版权、商业秘密等八个领域。IPEval的创建填补了知识产权领域缺乏专门评估基准的空白,为LLMs在知识产权代理和咨询任务中的表现提供了标准化评估工具。该数据集的设计不仅考虑了区域特性,还强调了时间动态性,确保模型能够理解不同地区知识产权法律的差异及其随时间的变化。
当前挑战
IPEval数据集面临的挑战主要体现在两个方面。首先,知识产权领域的复杂性和动态性使得模型在理解和应用相关法律时面临巨大挑战,尤其是在处理跨区域和跨时间的法律差异时。其次,数据集的构建过程中,研究人员需要从大量的中英文专利代理人考试题目中提取和标注高质量数据,确保数据的权威性和准确性。此外,数据集的多样性和复杂性要求模型具备强大的推理能力,尤其是在处理多选题时,模型不仅需要准确判断每个选项的正确性,还需理解选项之间的关系。这些挑战凸显了开发更具专业性的知识产权领域大语言模型的必要性。
常用场景
经典使用场景
IPEval数据集主要用于评估大型语言模型(LLMs)在知识产权(IP)领域的理解、应用和推理能力。该数据集通过2657道选择题,涵盖了知识产权的四大能力维度:创造、应用、保护和管理,涉及专利、商标、版权、商业秘密等多个领域。研究人员可以通过IPEval对LLMs在知识产权咨询任务中的表现进行系统性评估,尤其是在零样本、少样本和思维链(CoT)等不同提示策略下的表现。
解决学术问题
IPEval解决了当前缺乏专门评估LLMs在知识产权领域能力的基准测试问题。通过提供双语(中英文)选择题,IPEval能够评估模型对知识产权相关法律的理解、认知活动(如侵权处理和保护方法)的识别以及应用程序的推理能力。该数据集还为研究人员提供了区域性和时间性特征的评估框架,帮助模型更好地理解不同地区的知识产权法律差异及其随时间的变化。
衍生相关工作
IPEval的推出催生了一系列相关研究工作,尤其是在知识产权领域的LLMs开发和应用方面。例如,基于IPEval的评估结果,研究人员可以进一步优化模型在知识产权任务中的表现,开发更具针对性的知识产权领域LLMs。此外,IPEval还为其他垂直领域的基准测试提供了参考,推动了法律、医疗等领域的LLMs评估工作。
以上内容由遇见数据集搜集并总结生成


