OCR-Data
收藏Hugging Face2026-04-12 更新2026-04-13 收录
下载链接:
https://huggingface.co/datasets/Yesianrohn/OCR-Data
下载链接
链接失效反馈官方服务:
资源简介:
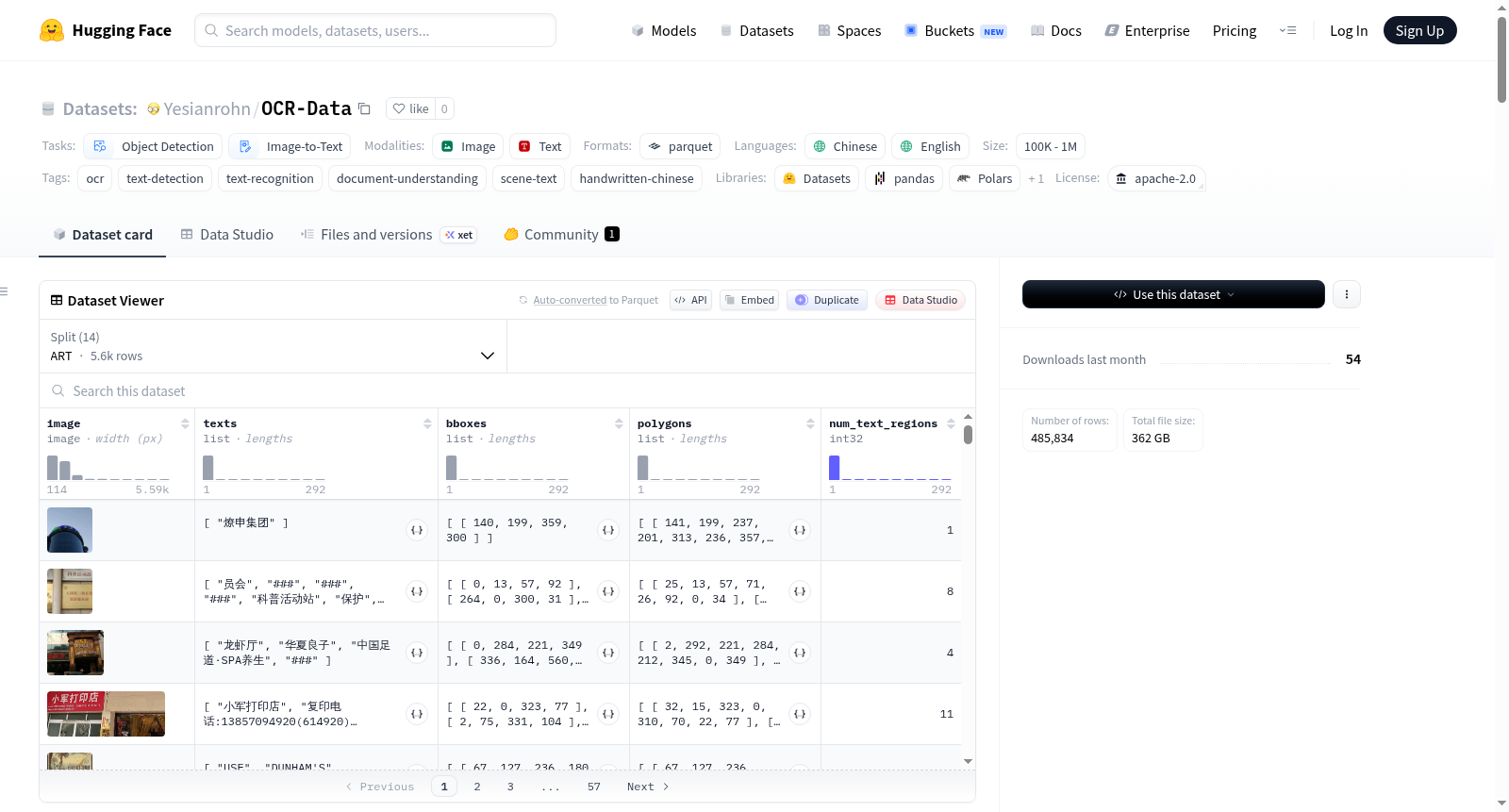
OCR文本检测与识别数据集是一个大规模、多来源的OCR数据集,集成了14个公开基准数据集,用于场景图像和手写文档中的文本检测与识别。每张图像均包含以下标注信息:每个文本区域的转录文本、轴对齐矩形边界框(bounding boxes)以及精确的多边形坐标边界点。数据集以HuggingFace Parquet格式存储,图像以原始字节形式嵌入,支持高效流式加载和零配置使用。每个源基准数据集作为独立的分割存储,用户可以自由加载单个子集或组合多个子集。
数据集包含以下主要特征:
- `image`:文档/场景图像(以原始字节形式嵌入)
- `texts`:每个文本区域的转录文本字符串列表
- `bboxes`:每个文本区域的轴对齐边界框坐标 `[x_min, y_min, x_max, y_max]`
- `polygons`:每个文本区域的多边形坐标平面数组 `[x1, y1, x2, y2, ...]`
- `num_text_regions`:图像中的文本区域总数
该数据集适用于多种OCR相关任务,包括但不限于:场景文本检测与识别、手写中文识别、文档理解等。数据集支持多种使用方式,包括全量加载、按分割加载、流式处理以及多分割组合等。
创建时间:
2026-04-10
搜集汇总
数据集介绍
构建方式
在光学字符识别领域,数据集的构建质量直接影响模型性能。OCR-Data数据集通过系统整合14个公开基准测试集,构建了一个大规模、多源异构的文本检测与识别数据集。其构建过程采用标准化流程,将每个源数据集作为独立分割存储,确保原始数据的完整性。数据以HuggingFace Parquet格式封装,图像以原始字节形式嵌入,配合统一的Arrow模式结构,实现了高效流式加载与零配置使用。这种模块化设计允许研究者灵活组合不同场景下的文本数据,为跨领域OCR研究提供了坚实基础。
使用方法
使用该数据集时,研究者可通过HuggingFace datasets库实现便捷操作。基础加载方式支持全数据集或特定分割的调用,内置的流式处理模式无需完整下载即可迭代访问数据。对于模型训练场景,可结合concatenate_datasets函数自由组合多个分割,构建定制化的训练集。数据集提供的标准化标注格式可直接用于主流检测与识别框架,示例代码展示了如何可视化带标注图像,以及将数据转换为Pandas DataFrame进行统计分析。这种即插即用的设计极大降低了OCR研究的数据准备门槛。
背景与挑战
背景概述
OCR-Data数据集作为一项大规模、多源的光学字符识别基准,其构建旨在整合14个公开的文本检测与识别基准,涵盖自然场景图像与手写文档两大范畴。该数据集由研究社区通过HuggingFace平台发布,核心研究问题聚焦于提升复杂环境下文本的定位与转录精度,特别是针对中文等非拉丁语系文字以及任意形状文本的识别挑战。通过聚合ART、COCO-Text、CTW等多样化子集,该数据集不仅推动了场景文本理解与文档分析领域的发展,还为多模态人工智能模型提供了关键的训练与评估资源,显著促进了跨语言、跨场景的OCR技术进步。
当前挑战
OCR-Data数据集所应对的领域挑战主要在于解决复杂视觉环境中文本的精准检测与识别问题,包括自然场景下的光照变化、字体多样性、背景干扰以及手写字符的个体差异等。在构建过程中,数据集整合了多个异构基准,面临数据格式统一、标注标准对齐以及多语言文本(如中文与英文)的协调等工程挑战。此外,确保图像嵌入与标注信息(如边界框与多边形坐标)的高效存储与流式加载,同时维持各子集原始数据质量,亦是该数据集构建中的关键难点。
常用场景
经典使用场景
在光学字符识别领域,OCR-Data数据集作为大规模、多源文本检测与识别基准,其经典应用场景集中于模型训练与评估。该数据集整合了14个公开基准,涵盖自然场景图像与手写文档,提供文本区域转录、边界框及多边形坐标标注。研究人员通常利用其丰富标注信息,构建端到端OCR流水线,训练深度学习模型以精准定位并识别图像中任意形状的文本,尤其在复杂背景或低质量图像中展现卓越性能。
解决学术问题
OCR-Data数据集有效解决了文本识别研究中数据稀缺与标注不一致的核心挑战。通过聚合多源基准,它提供了统一格式的大规模标注数据,支持跨语言、跨场景的模型泛化能力评估。该数据集促进了任意形状文本检测、多语言混合识别以及手写字符解析等前沿问题的探索,为学术界建立了可复现的实验基准,显著推动了文档理解与场景文本分析领域的方法创新与理论进展。
实际应用
在实际应用层面,OCR-Data数据集支撑了众多工业级文本识别系统的开发与优化。基于其标注数据训练的模型已广泛应用于智能文档处理、自动驾驶中的路牌识别、零售场景的店铺招牌分析以及金融票据自动化录入等场景。数据集涵盖的街景图像、网络图片与手写文档等多源数据,确保了模型在真实世界复杂环境下的鲁棒性,为商业OCR解决方案提供了关键数据基础。
数据集最近研究
最新研究方向
在光学字符识别领域,大规模多源数据集的整合正成为推动技术革新的关键驱动力。OCR-Data数据集汇聚了14个公开基准,涵盖场景文本与手写文档,其丰富的标注信息为模型训练提供了坚实基础。当前研究前沿聚焦于跨域文本理解与端到端系统优化,借助该数据集的多语言与多场景特性,学者们致力于提升模型在复杂环境下的鲁棒性与泛化能力。热点事件如多模态大模型的兴起,进一步激发了文档智能分析与场景文本识别的融合探索,这些进展不仅深化了对任意形状文本的检测与识别,也为自动驾驶、数字档案管理等实际应用注入了新的活力。
以上内容由遇见数据集搜集并总结生成


