kth8/gpt-oss-20b-ValleyBench-benchmark
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/kth8/gpt-oss-20b-ValleyBench-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
ValleyBench是一个用于评估语言模型性能的数据集,具体用于测试模型在数值计算或问题解决任务中的准确率,但README文件未提供其详细描述。
ValleyBench is a dataset used for evaluating the performance of language models, specifically for testing accuracy in numerical computation or problem-solving tasks, but the README does not provide a detailed description.
提供机构:
kth8
搜集汇总
数据集介绍
构建方式
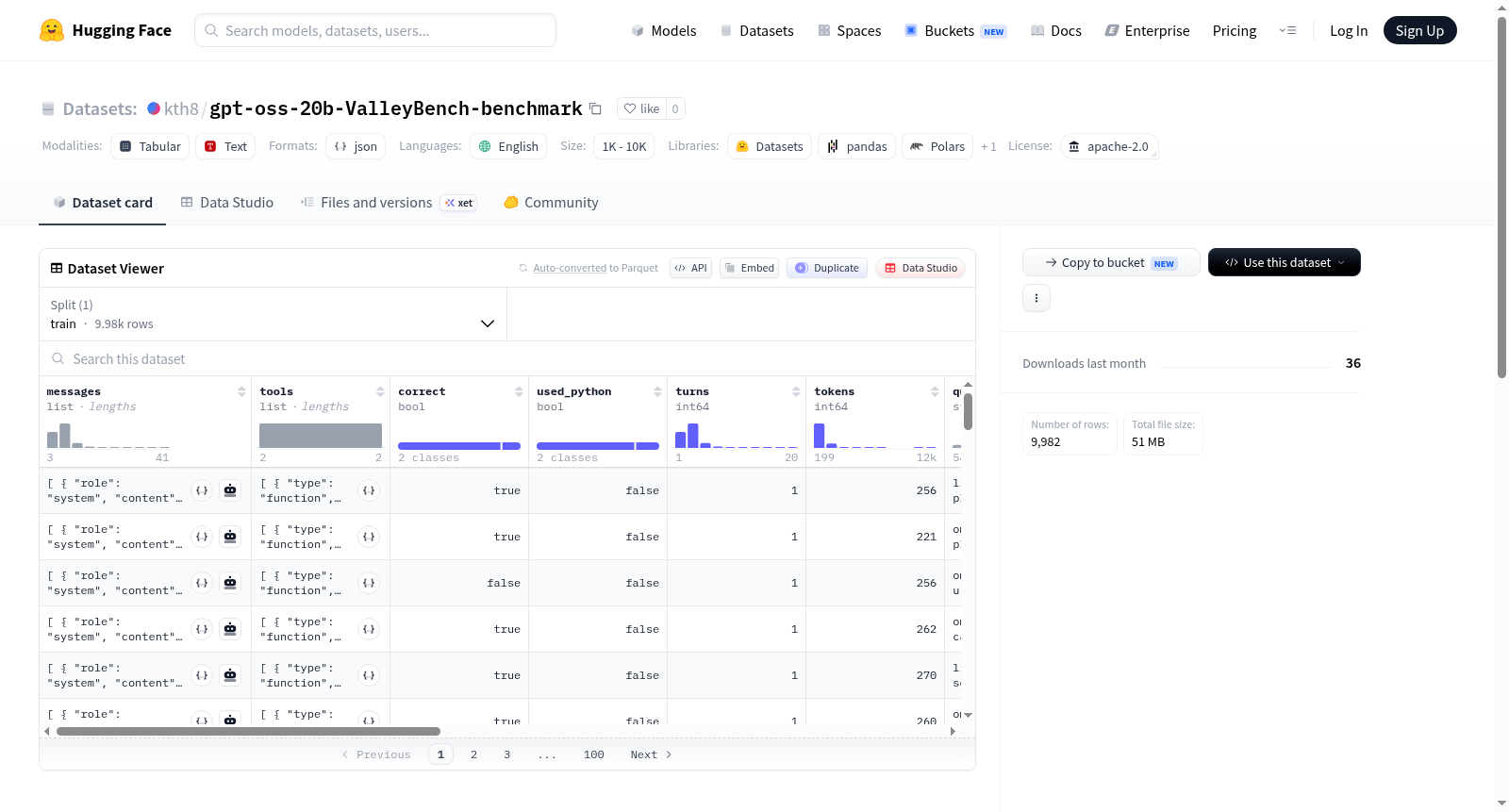
该数据集是基于开源模型openai/gpt-oss-20b在ValleyBench基准测试集上的表现构建而成的。构建过程严格遵循自动评估流程,将模型对ValleyBench中每个样本的预测答案与真实答案进行比对,若预测值与标准答案之差的绝对值不超过0.01,则判定为回答正确。测试样本总量为一万个,共计发起一万一千余次Python工具调用以辅助计算,最终汇总得到正确、错误、异常三类统计结果。
特点
数据集以基准测试的形式呈现,核心特色在于其评估指标的严谨性与透明性。以0.01的容差阈值保证了结果判定的合理性,同时提供了正确数、错误数、异常数、总样本数、工具调用次数及总完成Token数等详尽的元数据。83.7%的准确率直观反映了模型在该任务上的能力水平,为后续性能对比与模型迭代提供了可复现的量化基准。
使用方法
用户可基于该数据集对gpt-oss-20b或其他类似模型进行标准化评测。使用时需准备与ValleyBench格式一致的输入样本,并设定相同的容差标准(0.01)以确保结果可比性。可复用数据集附带的Python工具调用逻辑来简化计算流程,并通过对比原始统计指标(如准确率、错误分类数)来评估模型改进效果或进行跨模型横向比较。
背景与挑战
背景概述
该数据集发布于2024年,由研究团队基于OpenAI的gpt-oss-20b模型与ValleyBench数据集构建而成,旨在评估大语言模型在数学推理和工具调用方面的能力。核心研究问题聚焦于如何通过基准测试量化模型在复杂计算任务中的准确性与稳定性。该数据集包含1万个样本,覆盖了需要Python工具辅助求解的数值问题,对推动语言模型与外部工具协同工作的研究方向具有重要参考价值。其发布为后续模型性能对比提供了标准化评估框架,尤其在高精度要求(误差容忍度0.01)的场景下,凸显了模型推理能力的可靠性。
当前挑战
所解决的领域问题在于:大语言模型在纯粹文本推理中常面临数值精度不足、逻辑链条断裂等挑战,尤其是在需要多步计算或借助外部工具的复杂数学任务上表现欠佳。该数据集通过强制模型调用Python工具并量化其输出精度,暴露了模型在工具使用策略、对整数与浮点数运算的敏感性以及错误恢复机制上的薄弱环节。构建过程中的挑战包括:设计足够多样化且求解路径非唯一的数值问题以确保测试的覆盖度,平衡问题难度以避免天花板效应,以及严格控制工具调用次数与令牌消耗,防止模型因过度计算而掩盖推理缺陷。
常用场景
经典使用场景
在数学推理与计算能力评估领域,大型语言模型的符号运算与逻辑演绎性能始终是学界关注的焦点。gpt-oss-20b-ValleyBench-benchmark数据集通过整合OpenAI的GPT-OSS-20B模型与ValleyBench数据集,构建了一套高精度的基准测试框架。其经典使用场景聚焦于量化模型在数学问题求解、数值计算和代码辅助推理任务中的表现,借助Python工具链实现自动化评估,并以0.01的误差阈值判定答案正确性,为模型数学能力的纵向比较与横向对标提供了标准化度量工具。
解决学术问题
长期以来,大型语言模型在数学任务上的可靠性评估缺乏统一且可复现的标准,尤其在处理复杂数值计算时,模型输出经常出现逻辑偏差或精度不足。该数据集通过引入严格误差容限和自动化脚本验证机制,有效解决了模型数学推理能力量化不精准、人工评估成本高昂等核心学术问题。其意义在于为语言模型的数值稳健性、算法执行效率及错误类型分析奠定了实证基础,推动了从定性描述到定量评估的研究范式转变,对理解模型在形式化推理中的局限性具有里程碑价值。
衍生相关工作
该基准测试的发布催生了一系列衍生研究,包括针对模型数学错误类型的分类体系构建、基于工具增强的推理能力提升方法,以及不同规模模型在数学任务上的能力边界分析。相关工作如Chain-of-Thought与程序辅助语言模型的混合推理策略、错误纠正机制的设计、以及鲁棒性训练技术的开发,均借鉴了该基准提供的细粒度评估视角。这些成果共同推动了语言模型在形式化推理领域的理论深化与工程实践进步。
以上内容由遇见数据集搜集并总结生成


