MM-IQ
收藏Hugging Face2025-01-30 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/huanqia/MM-IQ
下载链接
链接失效反馈官方服务:
资源简介:
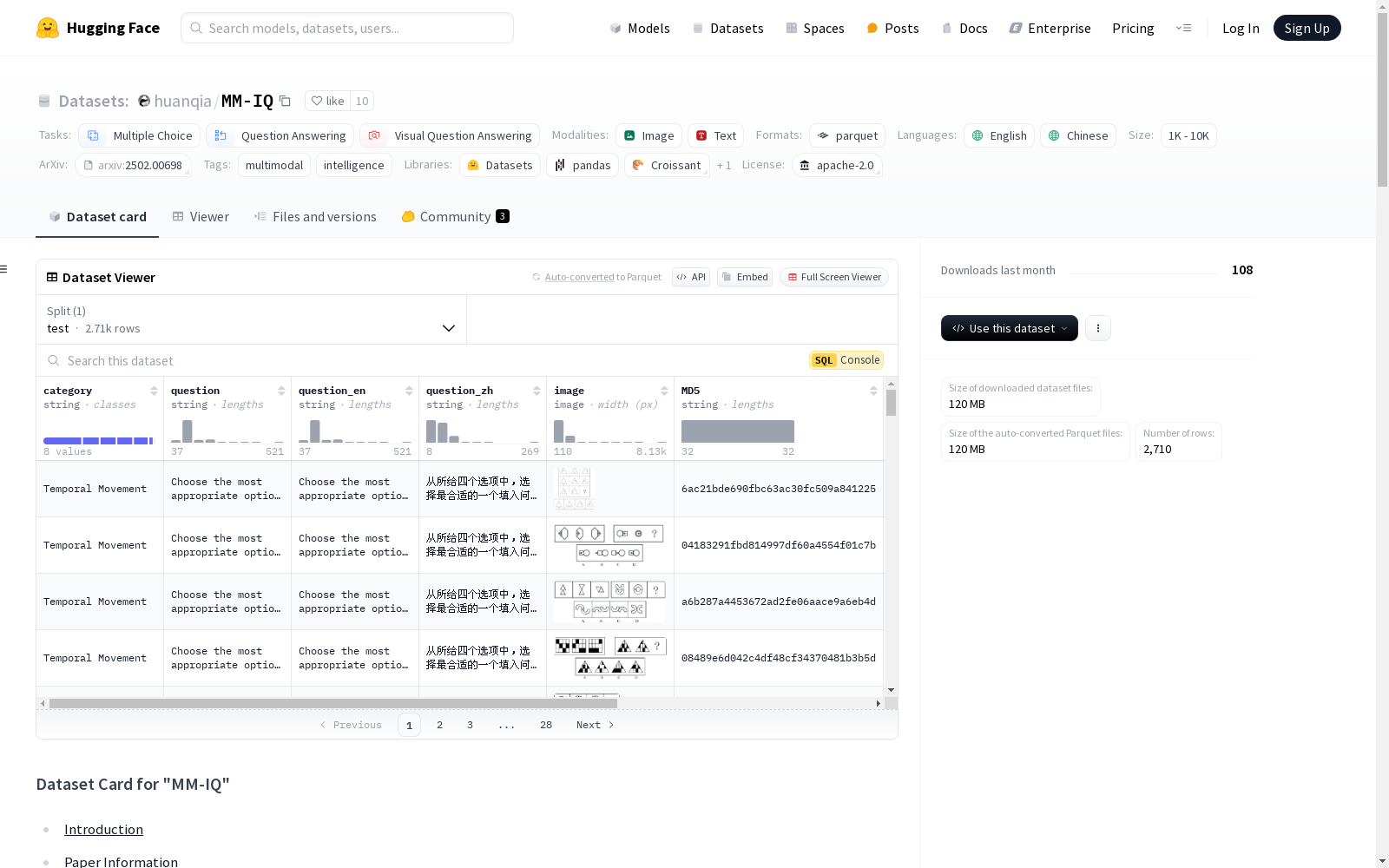
MM-IQ是一个新的基准测试,旨在通过需要抽象推理能力的多种推理模式来评估多模态语言模型(MLLMs)的智能。它包含三种输入格式、六种问题配置和八种推理模式。MM-IQ拥有2710个样本,是评估MLLMs智能的最全面和最大的AVR基准测试,分别比最近的两个基准测试MARVEL和MathVista-IQTest大3倍和10倍。通过专注于AVR问题,MM-IQ提供了对MLLMs认知能力和智能的有针对性的评估,有助于更全面地理解它们在追求通用人工智能(AGI)过程中的优势和局限性。
创建时间:
2025-01-28
原始信息汇总
MM-IQ 数据集概述
任务类别
- 多项选择题
- 问题回答
- 视觉问题回答
语言
- 英语 (en)
- 中文 (zh)
标签
- 多模态 (multimodal)
- 智力测试 (intelligence)
数据规模
- 1K < n < 10K
许可
Apache-2.0
数据集名称
MM-IQ
配置信息
- 配置名称:默认 (default)
- 特征列表:
- 类别 (category):字符串 (string)
- 问题 (question):字符串 (string)
- 问题(英文)(question_en):字符串 (string)
- 问题(中文)(question_zh):字符串 (string)
- 图片 (image):图片 (image)
- MD5 (MD5):字符串 (string)
- 数据ID (data_id):整型 (int64)
- 答案 (answer):字符串 (string)
- 切分 (split):字符串 (string)
- 特征列表:
数据集简介
MM-IQ是一个包含2710个精心策划的测试项目的全面评估框架,涵盖8种不同的推理范式。
论文信息
- 论文:MM-IQ: Benchmarking Human-Like Abstraction and Reasoning in Multimodal Models
- 代码:MMIQ GitHub
- 项目:MMIQ Benchmark
- 排行榜:MMIQ Leaderboard
数据集使用
数据下载
使用以下命令下载数据集(确保已安装Huggingface Datasets): python from datasets import load_dataset dataset = load_dataset("huanqia/MM-IQ")
数据格式
数据集以Parquet格式提供,包含以下属性: json { "question": [string] 问题文本, "answer": [string] 问题的正确答案, "data_id": [int] 问题的ID, "category": [string] 推理范式的类别, "image": [image] 与数据.zip中的图片对应的图片(原始字节和图片路径) }
自动评估
有关在数据集上自动评估模型的详细信息,请参考我们的GitHub仓库。
引用
如果您在研究中使用MM-IQ数据集,请使用以下BibTeX引用论文: bibtex @article{cai2025mm, title={MM-IQ: Benchmarking Human-Like Abstraction and Reasoning in Multimodal Models}, author={Cai, Huanqia and Yang, Yijun and Hu, Winston}, journal={arXiv preprint arXiv:2502.00698}, year={2025} }
联系方式
Huanqia Cai: caihuanqia19@mails.ucas.ac.cn
搜集汇总
数据集介绍
构建方式
MM-IQ数据集的构建,立足于评估人工智能在多模态情景下的抽象与推理能力。该数据集由2,710个精心挑选的测试项目组成,覆盖了8种不同的推理范式,通过图像与文字相结合的方式,模拟人类在多模态环境下的认知过程。
使用方法
使用MM-IQ数据集时,研究者可以通过Huggingface Datasets库方便地进行数据下载和加载。数据以Parquet格式提供,包含了问题文本、正确答案、问题ID、推理范式类别以及相关图像等信息。自动评估模型性能时,可参考GitHub仓库中提供的指南和工具。
背景与挑战
背景概述
MM-IQ数据集的构建源于对人工智能领域评价标准的深入思考。在传统智力测试中,人类认知能力评估通常与语言背景、语言熟练度或特定领域知识解耦,以孤立抽象和推理的核心能力。然而,在人工智能研究中,缺乏系统性的基准来量化这些关键的认知维度。为此,MM-IQ数据集应运而生,该数据集包含了2710个经过精心挑选的测试项目,涵盖了8种不同的推理范式。该数据集的创建时间为2025年,主要研究人员包括Huanqia Cai、Yijun Yang和Winston Hu,其研究成果已在arXiv上发布。MM-IQ数据集的提出,为多模态系统在近似人类推理能力方面的评估提供了新的标准和视角,对相关领域产生了重要影响。
当前挑战
MM-IQ数据集在构建和研究中面临的挑战主要体现在两个方面:一是领域问题的挑战,即如何构建一个能够全面评估多模态系统在抽象和推理能力上的基准;二是构建过程中的挑战,包括测试项目的精心挑选、数据集的多样性和平衡性、以及自动评估方法的开发。研究指出,即使是先进的架构,其性能也仅略优于随机机会(27.49%对25%的基线准确性),这凸显了当前多模态系统在近似基本人类推理能力方面的不足,指出了需要范式转变的进展来弥合这一认知差距。
常用场景
经典使用场景
MM-IQ数据集在多模态人工智能领域中被广泛用于评估模型在抽象和推理方面的能力。该数据集包含了精心设计的2710个测试项目,覆盖了8种不同的推理范式,如逻辑操作、数学推理、二维和三维几何推理等。其经典使用场景主要在于为研究者提供一个统一的标准,以量化多模态系统在模拟人类核心认知能力方面的表现,进而推动相关技术的进步。
解决学术问题
MM-IQ数据集解决了多模态人工智能领域中缺乏系统评估标准的问题,为研究人类认知能力在多模态系统中的表现提供了重要工具。通过该数据集,研究者能够发现即使是先进的模型,在执行人类-like抽象和推理任务时也表现出显著的局限性,这有助于揭示当前多模态系统的不足,并促进新算法和模型的发展。
实际应用
在实际应用中,MM-IQ数据集不仅能够帮助开发者在模型训练阶段识别和改善性能瓶颈,还可以为教育、心理学等领域提供一种新的评估工具,用于理解和提升人类认知能力。此外,该数据集在智能辅助决策、自动化评估等领域具有潜在的应用价值。
数据集最近研究
最新研究方向
MM-IQ数据集旨在评估人工智能在抽象和推理方面的认知能力,涵盖了多种推理范式。近期研究聚焦于利用MM-IQ数据集对多模态模型进行基准测试,揭示出即使是最先进的模型在性能上也仅略优于随机猜测。这一发现指出了当前多模态系统在模拟人类基本推理能力方面的不足,促使研究者探索新的方法和技术,以实现认知能力的质的飞跃。
以上内容由遇见数据集搜集并总结生成


