handeyilmaz/candidate-profiles-transliterated
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/handeyilmaz/candidate-profiles-transliterated
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: Position
dtype: string
- name: Moreinfo
dtype: string
- name: Looking For
dtype: string
- name: Highlights
dtype: string
- name: Primary Keyword
dtype: string
- name: English Level
dtype: string
- name: Experience Years
dtype: float64
- name: CV
dtype: string
- name: CV_lang
dtype: string
- name: id
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 321068918
num_examples: 155199
download_size: 177562224
dataset_size: 321068918
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
提供机构:
handeyilmaz
搜集汇总
数据集介绍
构建方式
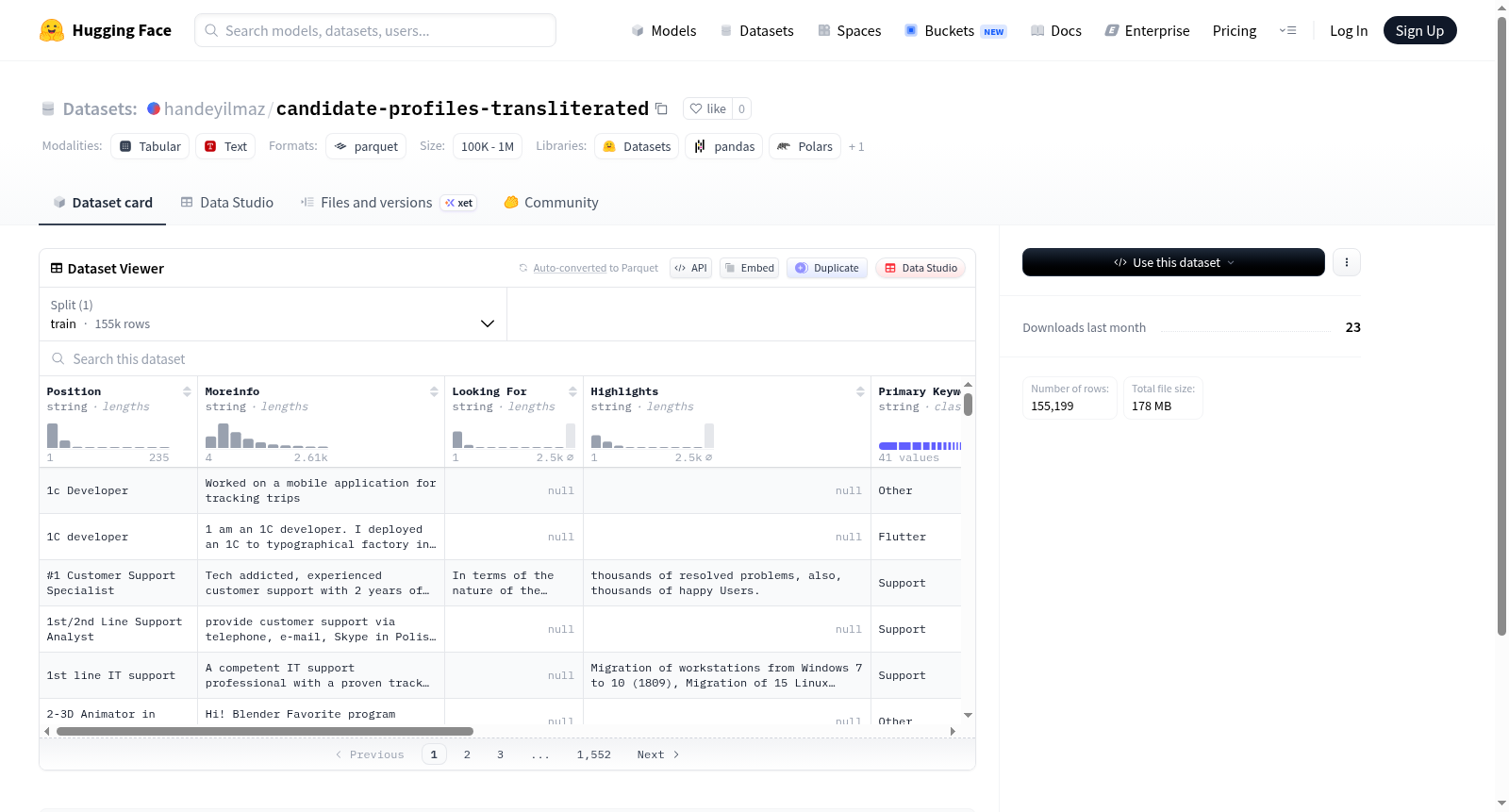
该数据集基于从招聘平台收集的候选人档案构建而成,原始数据经过脱敏处理,保留核心字段。内容涵盖职位名称、更多信息、求职意向、个人亮点、主要关键词、英语水平、工作经验年限、简历文本及其语言标识等结构化字段。每条记录均赋予唯一标识符(id)与索引,共计约15.5万条样本,以Parquet格式存储,便于高效加载与处理。
特点
数据集具有结构清晰、字段丰富的特点,覆盖简历关键维度,尤以英文水平、经验年限等量化指标为亮点。支持多语言简历识别(CV_lang字段),并包含详细的求职意向与个人特长描述,适用于多任务场景,如候选人画像分析、技能匹配建模及跨语言信息抽排。
使用方法
用户可通过HuggingFace的datasets库直接加载,指定配置为'default',读取train分片即可使用。适用于训练简历解析模型、招聘匹配系统或迁移学习任务。建议根据具体场景提取相关字段,如利用CV文本进行NLP预训练,或利用数值型字段进行回归预测分析。
背景与挑战
背景概述
该数据集名为candidate-profiles-transliterated,源自对求职者简历信息的收集与整理,创建时间不详,但推测为近年来人力资源与自然语言处理交叉领域的产物。其主要研究机构或发布者未明确说明,核心研究问题聚焦于如何通过多语言音译转换技术,将非英语母语者的职业信息统一为拉丁字母表示,以提升全球人才匹配效率。数据集包含逾15万条样本,涵盖职位、工作经验、英语水平等关键字段,为招聘推荐系统、职业画像分析等应用提供了基础语料。在跨文化求职与人才流动日益频繁的背景下,该数据集对推动多语言简历解析、改善职场多样性研究具有潜在影响力,尤其为处理非规范拼写与音译变体问题树立了范例。
当前挑战
该数据集面临的核心挑战首先在于解决跨语言信息检索的领域问题:不同语言体系的简历在专有名词、技能描述上存在音译差异,直接使用原始文本会导致特征稀疏与匹配失效,需通过音译标准化实现语义对齐。构建过程中的挑战包括:第一,音译规则的复杂性与语言歧义性,例如同一中文姓名可能有多种罗马化拼写;第二,数据标注一致性难以保障,如“English Level”等字段因主观评判标准不一而引入噪声;第三,简历中混杂的文化特有的缩写、头衔及格式,增加了特征提取难度。此外,数据集仅提供训练集分割,缺乏验证与测试集,可能限制模型泛化能力的可靠评估,且字段缺失值处理策略未公开,对下游任务的稳健性构成潜在风险。
常用场景
经典使用场景
在人力资源与人才管理领域,候选人档案数据的结构化与多语言处理一直是提升招聘效率的关键瓶颈。该数据集以音译后的候选人档案为核心,汇聚了职位信息、技能亮点、英语水平及工作年限等丰富字段,为构建智能化简历解析与人才匹配系统提供了坚实的数据基础。经典使用场景涵盖基于自然语言处理的候选人与职位画像构建,通过分析CV文本与结构化标签之间的关联,训练模型自动提取关键资质并实现精准推荐,从而大幅降低人工筛选成本。
解决学术问题
该数据集有效解决了跨语言简历信息抽取与标准化这一学术难题。在自然语言处理研究中,非英语CV的语义解析常面临语种混合与格式多样的挑战,而本数据集通过音译处理统一了文本表示,为命名实体识别、技能短语抽取及工作经验量化等任务提供了标注清晰的训练样本。其意义在于推动了多语言人才匹配理论的发展,使得模型能够跨越语言障碍理解候选人背景,为全球化人才流动与招聘公平性研究奠定了方法学基础。
衍生相关工作
围绕该数据集,学术界衍生出一系列创新工作。研究者利用其结构化特征开发了基于Transformer的简历编码器,并在候选人与职位相似度计算任务上取得了显著提升。此外,有工作引入对比学习框架,通过利用Highlights字段中的摘要信息增强长文本表示,进一步优化了人才搜索的精度。这些研究共同推动了招聘领域从关键词匹配向语义理解的技术演进,并为多模态人才分析提供了数据驱动的范式参考。
以上内容由遇见数据集搜集并总结生成


