WallResearch/recurrent-staged-loras-dataset
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/WallResearch/recurrent-staged-loras-dataset
下载链接
链接失效反馈官方服务:
资源简介:
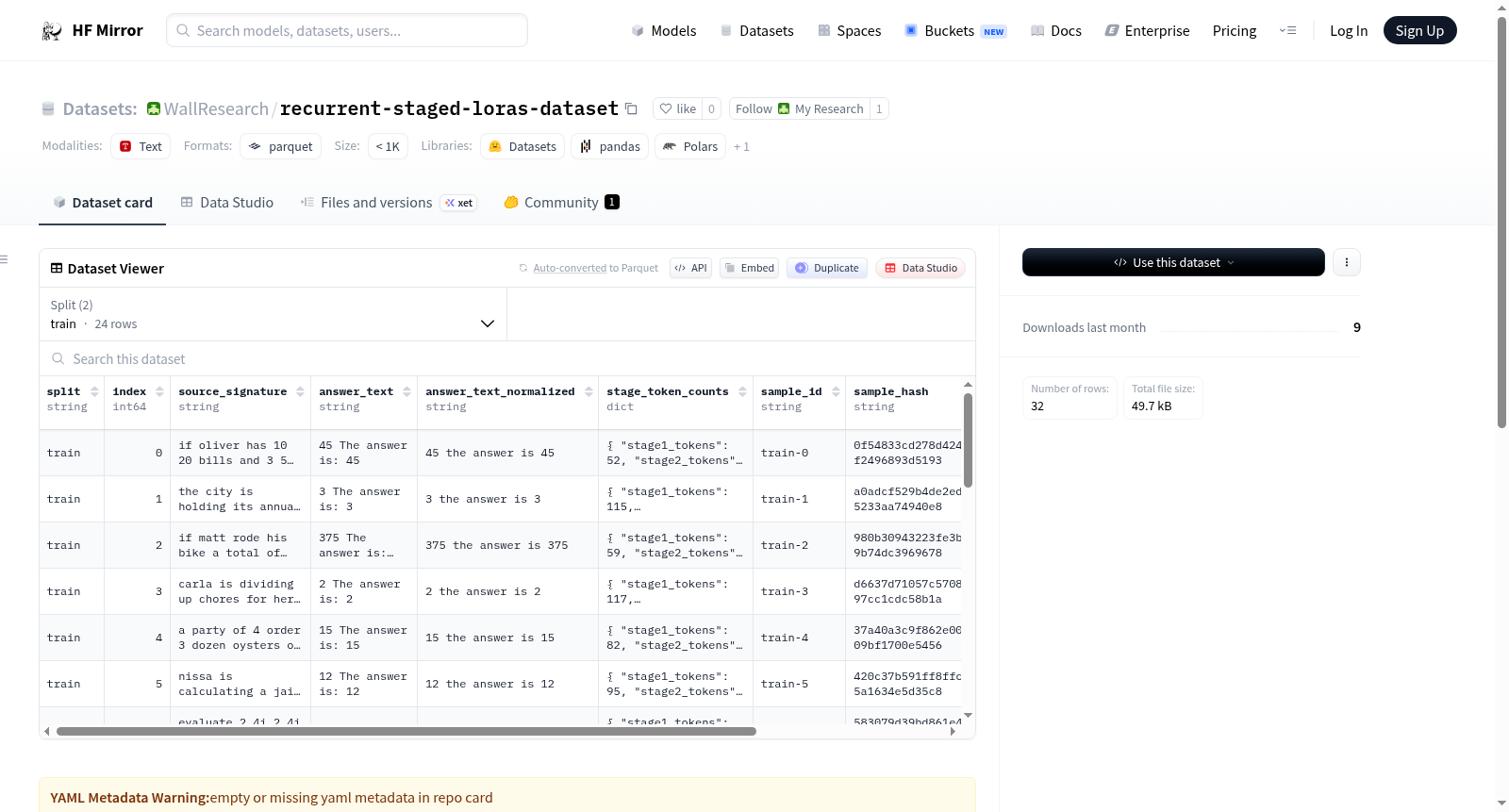
该数据集是metamath_qa数据集的train分割的导出分区,经过特定的转换和筛选规则处理,包含确定性样本ID和指纹以确保可重复性。主要用于实验的可重复性,使用时需注意数据分享的权限限制。
These partitions are exported from the train split of the metamath_qa dataset, processed with specific transformation and filtering rules, and include deterministic sample IDs and fingerprints for reproducibility. Primarily used for experiment reproducibility, with usage restrictions on data sharing permissions.
提供机构:
WallResearch
搜集汇总
数据集介绍
构建方式
该数据集源于对`metamath_qa`数据集的训练集进行再加工,遵循特定仓库中定义的阶段性令牌掩码构建协议。通过应用`dataset_preprocessing_summary.json`中记录的过滤规则,对原始样本进行筛选与变换,最终生成具有确定性样本标识符与逐样本指纹的可复现分区。这一流程确保了数据构建的透明性与实验的可追溯性。
使用方法
此数据集专为探究阶段性令牌掩码构建方法对模型训练影响而设计。研究者可将其直接用于微调实验,或作为基准分区对比其他预处理策略。使用时务必确认底层`metamath_qa`数据的使用许可,并仅在授权范围内发布或共享本衍生分区,以确保学术伦理与法律合规。
背景与挑战
背景概述
在大型语言模型微调领域,数据集的构建质量直接影响模型性能与训练效率。由特定团队创造的recurrent-staged-loras-dataset,源自知名数学推理数据集metamath_qa的训练分割,其创建旨在支持递归阶段式低秩适配(LoRA)方法的可复现性研究。该数据集通过确切的样本标识符与指纹信息确保实验一致性,着重解决模型在多阶段微调中知识遗忘与参数共享的权衡问题。作为微调流水线中的派生工件,该数据集为探索低秩适配的递进式训练策略提供了标准化基准,推动了参数高效微调方法的实证研究。
当前挑战
该数据集面临的核心挑战涵盖两方面。其一,领域问题层面,递归阶段式LoRA需应对多轮微调中灾难性遗忘与旧知识保留的平衡难题,同时要避免因参数更新过度导致模型在基础任务上性能衰退。其二,构建过程中需严格遵循隐私与版权限制,仅允许在原始数据授权范围内发布派生分区;此外,精确的样本指纹生成与复现流程需依赖于完整的预处理配置,任何步骤的细微偏差均可能破坏实验的可复现性。
常用场景
经典使用场景
该数据集的核心应用场景在于为大语言模型的递归式分阶段微调提供标准化划分。通过将原始数据集metamath_qa中的训练集按照预设的递进式token掩码构造协议进行划分,研究者能够系统性地评估模型在不同复杂度任务上的多阶段学习能力。这种划分方式特别适用于探索模型从简单到复杂知识结构的渐进式习得过程,为解释模型内部表征的层次化构建提供了实验基础。
解决学术问题
该数据集解决了递归式多阶段训练中数据划分不统一、实验难以复现的学术难题。传统训练方式中,不同研究使用各自的数据筛选标准导致结果缺乏可比性。此数据集通过固定指纹、确定性样本ID和严格的过滤规则,确保了每一次实验划分的精确复现,从而为研究模型在多个训练阶段的知识积累机制、灾难性遗忘现象以及迁移学习效果的量化分析提供了统一的基准平台。
实际应用
在实际应用中,该数据集主要用于支持需要分阶段训练的大规模语言模型开发流程。工程师可以利用该数据集的分区特性,模拟从粗粒度理解到细粒度推理的渐进式训练过程,从而优化模型在数学推理、逻辑问答等垂直领域的表现。此外,该数据集还可用于验证递归式微调策略在实际产品部署中的稳定性,通过复现实验快速定位模型性能瓶颈。
数据集最近研究
最新研究方向
基于元数学问答数据集(metamath_qa)的递归式阶段性低秩适应(LoRA)导出分区研究,聚焦于通过确定性样本标识与指纹技术确保实验可复现性。当前前沿方向在于探索分阶段令牌掩码构建机制对模型微调效率的影响,以及从原始数据集到衍生分区的可追溯性框架构建。该数据集在可复现机器学习领域具有标志性意义,其分阶段导出协议为多阶段训练策略的标准化提供了实证基础,尤其适用于需要严格版本控制的分布式微调实验。研究强调分区衍生品的法律合规性,推动了数据集二次利用的伦理规范与知识产权边界讨论,对开放科学实践中数据集血缘追踪与责任归属的范式演进具有催化作用。
以上内容由遇见数据集搜集并总结生成


