umie_datasets
收藏Hugging Face2024-08-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/lion-ai/umie_datasets
下载链接
链接失效反馈官方服务:
资源简介:
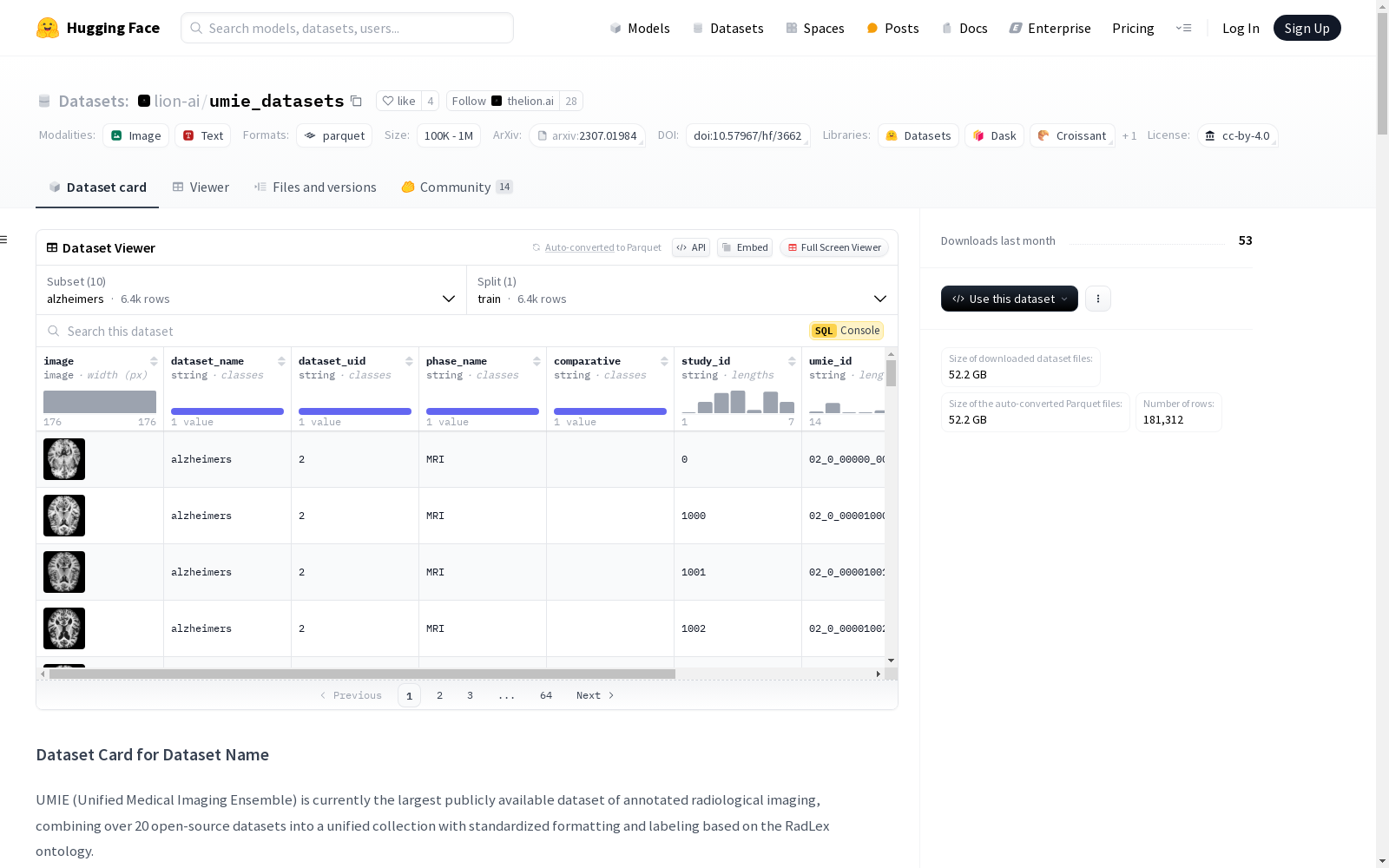
该数据集包含多个医学图像数据集配置,涵盖阿尔茨海默病、脑肿瘤分类、脑肿瘤检测等多种疾病。每个配置详细列出了图像、数据集名称、数据集UID等特征,以及训练集的数据大小和下载大小。数据集主要用于医学图像分析和疾病检测。
创建时间:
2024-08-29
原始信息汇总
数据集概述
数据集信息
阿尔茨海默病(Alzheimers)
- 特征:
image: 图像dataset_name: 字符串dataset_uid: 字符串phase_name: 字符串comparative: 字符串study_id: 字符串umie_id: 字符串mask: nulllabels: 字符串
- 分割:
train: 99043326.6 字节, 6400 样本
- 下载大小: 96727581 字节
- 数据集大小: 99043326.6 字节
脑肿瘤分类(Brain Tumor Classification)
- 特征:
image: 图像dataset_name: 字符串dataset_uid: 字符串phase_name: 字符串comparative: 字符串study_id: 字符串umie_id: 字符串mask: nulllabels: 字符串
- 分割:
train: 401417456.808 字节, 3264 样本
- 下载大小: 409873384 字节
- 数据集大小: 401417456.808 字节
脑肿瘤检测(Brain Tumor Detection)
- 特征:
image: 图像dataset_name: 字符串dataset_uid: 字符串phase_name: 字符串comparative: 字符串study_id: 字符串umie_id: 字符串mask: nulllabels: 字符串
- 分割:
train: 54944533.0 字节, 502 样本
- 下载大小: 26330695 字节
- 数据集大小: 54944533.0 字节
颅内出血(Brain with Intracranial Hemorrhage)
- 特征:
image: 图像dataset_name: 字符串dataset_uid: 字符串phase_name: 字符串comparative: 字符串study_id: 字符串umie_id: 字符串mask: 图像labels: 字符串
- 分割:
train: 257983789.214 字节, 5001 样本
- 下载大小: 344778754 字节
- 数据集大小: 257983789.214 字节
胸部X光14(Chest Xray14)
- 特征:
image: 图像dataset_name: 字符串dataset_uid: 字符串phase_name: 字符串comparative: 字符串study_id: 字符串umie_id: 字符串mask: nulllabels: 字符串
- 分割:
train: 45415592858.28 字节, 112120 样本
- 下载大小: 45065386546 字节
- 数据集大小: 45415592858.28 字节
Coronahack
- 特征:
image: 图像dataset_name: 字符串dataset_uid: 字符串phase_name: 字符串comparative: 字符串study_id: 字符串umie_id: 字符串mask: nulllabels: 字符串
- 分割:
train: 1880047016.73 字节, 5910 样本
- 下载大小: 1272987706 字节
- 数据集大小: 1880047016.73 字节
COVID-19检测(COVID-19 Detection)
- 特征:
image: 图像dataset_name: 字符串dataset_uid: 字符串phase_name: 字符串comparative: 字符串study_id: 字符串umie_id: 字符串mask: nulllabels: 字符串
- 分割:
train: 1596155812.031 字节, 5073 样本
- 下载大小: 1181673460 字节
- 数据集大小: 1596155812.031 字节
肺部检测与测量(Finding and Measuring Lungs)
- 特征:
image: 图像dataset_name: 字符串dataset_uid: 字符串phase_name: 字符串comparative: 字符串study_id: 字符串umie_id: 字符串mask: 图像labels: 字符串
- 分割:
train: 17951746.0 字节, 267 样本
- 下载大小: 17843713 字节
- 数据集大小: 17951746.0 字节
Kits23
- 特征:
image: 图像dataset_name: 字符串dataset_uid: 字符串phase_name: 字符串comparative: 字符串study_id: 字符串umie_id: 字符串mask: 图像labels: 字符串
- 分割:
train: 3497667100.483 字节, 32989 样本
- 下载大小: 3597493874 字节
- 数据集大小: 3497667100.483 字节
膝关节骨关节炎(Knee Osteoarthritis)
- 特征:
image: 图像dataset_name: 字符串dataset_uid: 字符串phase_name: 字符串comparative: 字符串study_id: 字符串umie_id: 字符串mask: nulllabels: 字符串
- 分割:
train: 212468967.388 字节, 9786 样本
- 下载大小: 202960658 字节
- 数据集大小: 212468967.388 字节
搜集汇总
数据集介绍
构建方式
UMIE数据集通过整合20多个开源医学影像数据集构建而成,涵盖了CT、MRI和X射线等多种模态的影像数据。数据集的构建过程包括标准化的预处理流程、图像格式的统一转换(如DICOM到PNG)、掩码提取以及基于RadLex本体论的标签标准化。每个图像都被赋予唯一的标识符,确保数据的一致性和可追溯性。预处理脚本模块化设计,便于扩展和集成新的数据集。
特点
UMIE数据集的特点在于其规模庞大且标准化程度高,包含超过100万张放射影像,涵盖了多种医学影像任务,如分类和分割。数据集采用RadLex本体论进行标签统一,确保了跨数据集的一致性。此外,数据集提供了丰富的注释信息,包括图像、掩码和标签,适用于训练和评估医学影像AI模型。数据集的结构清晰,文件组织标准化,便于研究人员快速上手。
使用方法
UMIE数据集适用于医学影像AI模型的训练和评估,特别是用于开发医学影像的基础模型。研究人员可以通过Hugging Face平台下载数据集,或通过GitHub仓库获取完整的预处理脚本,以便将新的数据集整合到UMIE格式中。数据集的使用方法包括加载图像和对应的标签,进行模型训练和验证。对于需要更高定制化的用户,可以通过GitHub仓库中的预处理脚本进一步处理数据,以满足特定研究需求。
背景与挑战
背景概述
UMIE(Unified Medical Imaging Ensemble)数据集是目前最大的公开医学影像数据集之一,由TheLion.AI团队于2024年创建。该数据集整合了超过20个开源医学影像数据集,涵盖了CT、MRI和X射线等多种模态,总计包含超过100万张标注影像。UMIE的独特之处在于其标准化的数据组织方式,采用了统一的预处理流程和RadLex本体进行标注,确保了跨数据集的一致性。该数据集旨在推动医学影像领域的基础模型开发,类似于通用计算机视觉领域的ImageNet。UMIE的创建解决了医学影像数据格式不统一、标注标准不一致等问题,为医学影像AI模型的训练和评估提供了重要资源。
当前挑战
UMIE数据集在构建和应用过程中面临多重挑战。首先,医学影像数据的多样性和复杂性使得数据格式的统一化成为一大难题,不同数据源的影像格式、标注风格和本体差异显著。其次,尽管UMIE采用了RadLex本体进行标注,但部分标签的映射仍存在局限性,可能导致信息丢失或泛化。此外,数据集的构建依赖于多个开源数据集,这些数据集的质量和标注精度参差不齐,可能引入潜在的偏差。最后,由于部分数据集的许可限制,UMIE无法直接重新分发所有数据,用户需要通过预处理脚本自行处理原始数据,增加了使用门槛。这些挑战要求研究者在应用UMIE时需谨慎验证模型性能,并充分考虑数据来源的潜在偏差。
常用场景
经典使用场景
UMIE数据集在医学影像分析领域具有广泛的应用,尤其是在训练和评估深度学习模型方面。该数据集整合了多种医学影像模态,如CT、MRI和X射线,涵盖了从阿尔茨海默病到脑肿瘤分类等多种疾病的影像数据。研究人员可以利用该数据集进行图像分类、分割任务,以及开发医学影像的基础模型。其标准化的预处理流程和统一的RadLex标签体系,使得跨数据集的研究变得更加高效和一致。
解决学术问题
UMIE数据集解决了医学影像研究中数据标准化不足的问题。通过整合20多个开源数据集,并采用统一的RadLex标签体系,该数据集为研究人员提供了一个大规模、标准化的医学影像资源。这不仅减少了数据预处理的工作量,还解决了不同数据集之间标签不一致的问题,为开发更鲁棒和可推广的医学影像模型提供了坚实的基础。
衍生相关工作
UMIE数据集的发布催生了一系列相关研究工作,尤其是在医学影像基础模型的开发方面。例如,基于该数据集的研究人员开发了多种深度学习模型,用于医学影像的分类和分割任务。此外,UMIE数据集还为医学影像领域的基准测试提供了标准化的平台,推动了该领域的算法比较和性能评估。其开源预处理流程也为其他研究者提供了便利,促进了更多医学影像数据集的整合与标准化。
以上内容由遇见数据集搜集并总结生成


