CUA-SUITE
收藏arXiv2026-03-25 更新2026-03-27 收录
下载链接:
https://cua-suite.github.io
下载链接
链接失效反馈官方服务:
资源简介:
CUA-SUITE是由多个研究机构联合创建的大规模计算机使用代理数据集,旨在解决专业桌面应用程序自动化的工作流问题。核心数据集VIDEOCUA包含约55小时的30 fps连续屏幕录制视频,覆盖87种应用程序的10,000个任务,总计600万帧,并附带详细的运动轨迹和多层推理注释。数据集通过专家设计的任务和密集的人工标注过程创建,包括UI元素标注和动作日志记录,适用于训练视觉世界模型、连续空间控制策略等研究,推动通用计算机使用代理的发展。
CUA-SUITE is a large-scale computer usage agent dataset jointly created by multiple research institutions, aiming to address workflow challenges in professional desktop application automation. The core dataset VIDEOCUA contains approximately 55 hours of 30 frames per second (fps) continuous screen-recorded videos, covering 10,000 tasks across 87 applications with a total of 6 million frames, and is accompanied by detailed motion trajectories and multi-layer inference annotations. Constructed via expert-designed tasks and a dense manual annotation pipeline including UI element labeling and action log recording, the dataset is suitable for research such as training visual world models and continuous spatial control strategies, advancing the development of general-purpose computer usage agents.
提供机构:
ServiceNow; 滑铁卢大学; Mila; 蒙特利尔大学; 麦吉尔大学; 牛津大学; 新加坡国立大学
创建时间:
2026-03-25
搜集汇总
数据集介绍
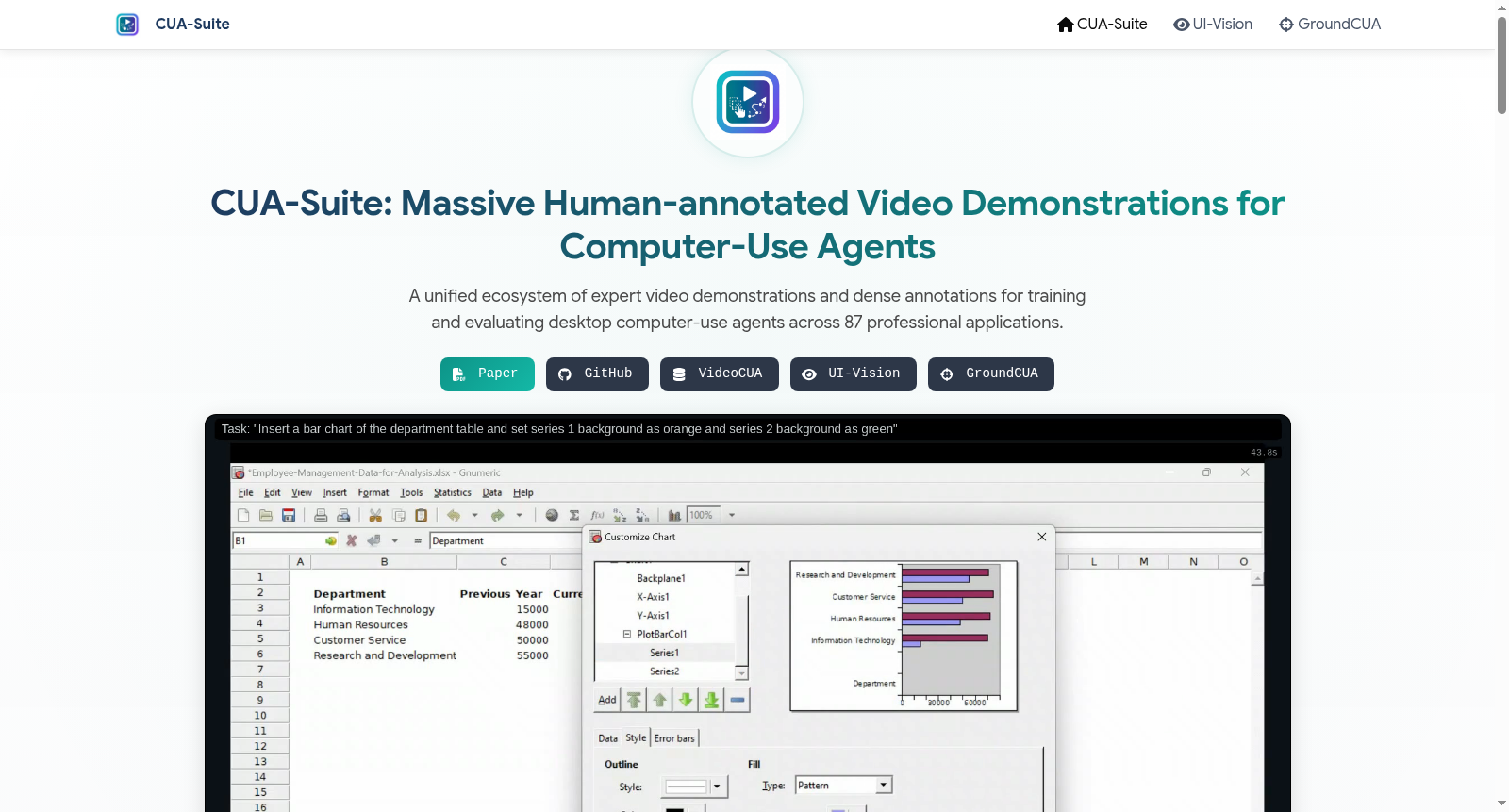
构建方式
在计算机使用代理(CUAs)研究领域,高质量、连续的人类演示视频是训练通用型智能体的关键瓶颈。CUA-SUITE数据集通过构建一个大规模、专家驱动的数据收集与标注生态系统来应对这一挑战。其核心构建流程始于从12个类别中精心挑选87款开源专业桌面应用,以确保数据覆盖的广泛性与代表性。随后,由人类专家设计并执行超过一万个真实工作场景中的任务,在此过程中,系统以30帧/秒的速率连续录制屏幕视频,同步记录毫秒级精度的光标运动轨迹与键盘操作。从连续视频流中提取关键帧后,标注人员对每一帧中所有可见的UI元素进行手动边界框标注,并辅以文本描述与功能分类,最终经过严格的多层级质量审核,形成了包含约55小时视频、600万帧画面及360万个UI元素标注的密集监督数据集。
特点
CUA-SUITE数据集的核心特点在于其前所未有的规模、密度与连续性。相较于以往仅提供稀疏截图的数据库,它提供了长达55小时的连续30帧/秒专家演示视频,完整保留了人机交互的完整时空动态,信息量超过现有最大公开数据集的2.5倍。数据集具有极高的标注密度,平均每个步骤包含近500词的多层推理注释,涵盖了观察、思考、行动描述与反思,为模型训练提供了丰富的因果监督信号。此外,其覆盖87款多样化的专业桌面应用,突破了以往数据集中于网页或移动端的局限,直接针对智能体在复杂专业软件中表现薄弱的领域。数据集以统一框架整合了视频演示、像素级UI接地与严谨评估三大资源,构成了支持全栈计算机使用智能研究的完整生态系统。
使用方法
CUA-SUITE数据集为计算机使用代理的研究与开发提供了多层次的实用方法。研究者可直接利用其连续的专家视频轨迹训练视觉-语言-动作模型,学习复杂的多步骤工作流执行。其密集的UI元素边界框与语义标注是训练通用屏幕解析模型和提升空间接地能力的宝贵资源。数据集的统一设计使其能够无损转换为现有主流智能体框架所需的格式,无论是基于截图的动作对、状态-动作-下一状态三元组,还是连续运动轨迹。此外,该数据集支持新兴研究方向,如利用其完整视频流与时间戳动作训练视觉世界模型进行前瞻规划,或基于其专家演示视频构建视频奖励模型。配套的UI-VISION基准测试则可用于系统评估模型在接地、布局理解与动作预测等方面的能力,精准定位性能瓶颈。
背景与挑战
背景概述
CUA-SUITE数据集由ServiceNow、滑铁卢大学、Mila、牛津大学及新加坡国立大学等机构的研究团队于2026年联合发布,旨在解决计算机使用智能体(CUAs)发展中的数据瓶颈问题。该数据集的核心研究问题在于如何为专业桌面应用提供大规模、高质量的人类演示视频,以支持智能体在复杂工作流中的规划、视觉感知与动作执行能力。通过整合约55小时、覆盖87种专业应用的连续30帧/秒视频记录,以及密集的多层推理标注与像素级UI元素标注,CUA-SUITE显著提升了桌面智能体训练数据的规模与质量,为通用计算机使用智能体的研究奠定了关键基础。
当前挑战
CUA-SUITE所应对的核心领域挑战在于计算机使用智能体在专业桌面环境中执行复杂任务时面临的视觉感知与动作规划瓶颈,尤其是现有模型在非标准化界面、多面板布局及连续时空控制中的高失败率。数据构建过程中的主要挑战包括:一是采集大规模、高帧率的连续人类演示视频,需克服专业软件多样性带来的录制与同步难题;二是实现像素级密集标注,需在87种应用的海量界面元素中确保标注的一致性与准确性;三是生成高质量的多层推理轨迹,需将原始交互日志转化为富含语义的指令跟随数据,以弥合原始视频与智能体训练需求之间的语义鸿沟。
常用场景
经典使用场景
在计算机使用代理(CUA)的研究领域,CUA-SUITE数据集以其大规模、高质量的连续视频演示和密集标注,成为训练和评估桌面智能代理的基石资源。该数据集最经典的使用场景是作为视觉-语言-动作模型的训练数据,支持从原始视频轨迹中学习复杂的桌面工作流执行。研究者利用其约55小时、涵盖87款专业桌面应用的连续30帧每秒视频,配合光标运动轨迹和多层推理标注,构建能够理解界面、规划任务并执行精确操作的通用型计算机使用代理。这些连续视频流完整保留了人类交互的时序动态,为模型提供了远超静态截图的丰富监督信号,使其在专业软件自动化、界面导航和多步骤工作流执行等任务上展现出卓越潜力。
解决学术问题
CUA-SUITE直接应对了计算机使用代理研究中的核心瓶颈——高质量、连续人类演示数据的稀缺性。此前研究多依赖稀疏截图或合成数据,缺乏时序连续性与精确的空间标注,导致模型在专业桌面应用中表现脆弱。该数据集通过提供密集的因果监督——屏幕上每个元素均有标注,每个动作均有记录——系统性地解决了视觉接地、动作预测和时序推理三大关键学术问题。其丰富的多模态语料支撑了视觉世界模型、连续空间控制、基于视频的奖励建模等新兴研究方向,为构建能够在复杂数字环境中可靠协作的通用智能体奠定了数据基础。
衍生相关工作
CUA-SUITE的发布催生了一系列重要的衍生研究。以其为核心的GROUNDCUA数据集训练了GROUNDNEXT系列视觉语言模型,在UI接地任务上达到先进水平。基于其连续视频数据,研究者探索了如ScreenParse的通用屏幕解析模型、GUI-Cursor的连续空间控制策略,以及ViMO等视觉世界模型,这些工作深化了对界面动态与动作序列的理解。同时,数据集支撑了对OpenCUA、ScaleCUA等现有行动模型在专业桌面域的性能评估与瓶颈分析,推动了MAI-UI、UI-TARS等后续架构的改进。这些衍生工作共同扩展了计算机使用智能的研究边界,验证了CUA-SUITE作为基础生态系统的催化作用。
以上内容由遇见数据集搜集并总结生成


