bigIR/AuFIN
收藏Hugging Face2024-03-08 更新2024-06-22 收录
下载链接:
https://hf-mirror.com/datasets/bigIR/AuFIN
下载链接
链接失效反馈官方服务:
资源简介:
这是一个用于在Twitter上进行权威用户查找的阿拉伯语数据集。数据集分享了使用BM25词汇检索模型检索到的前5位用户,其中查询是谣言文本,文档集合是用户文档。每个用户文档是通过连接其翻译后的个人资料名称和描述,以及所有其翻译后的Twitter列表名称和描述来构建的。
这是一个用于在Twitter上进行权威用户查找的阿拉伯语数据集。数据集分享了使用BM25词汇检索模型检索到的前5位用户,其中查询是谣言文本,文档集合是用户文档。每个用户文档是通过连接其翻译后的个人资料名称和描述,以及所有其翻译后的Twitter列表名称和描述来构建的。
提供机构:
bigIR
原始信息汇总
数据集概述
数据集名称
AuFIN
语言
阿拉伯语
数据集描述
AuFIN是一个用于Twitter中权威用户发现的阿拉伯语数据集。该数据集包含了使用BM25词汇检索模型检索到的前5个用户,其中查询是谣言文本,文档集合是用户文档。每个用户文档由其翻译后的个人资料名称和描述,以及所有翻译后的Twitter列表名称和描述拼接而成。
数据集链接
相关论文
该数据集的相关工作已发表在《Information Processing & Management》期刊上,题为“Who can verify this? Finding authorities for rumor verification in Twitter”。
搜集汇总
数据集介绍
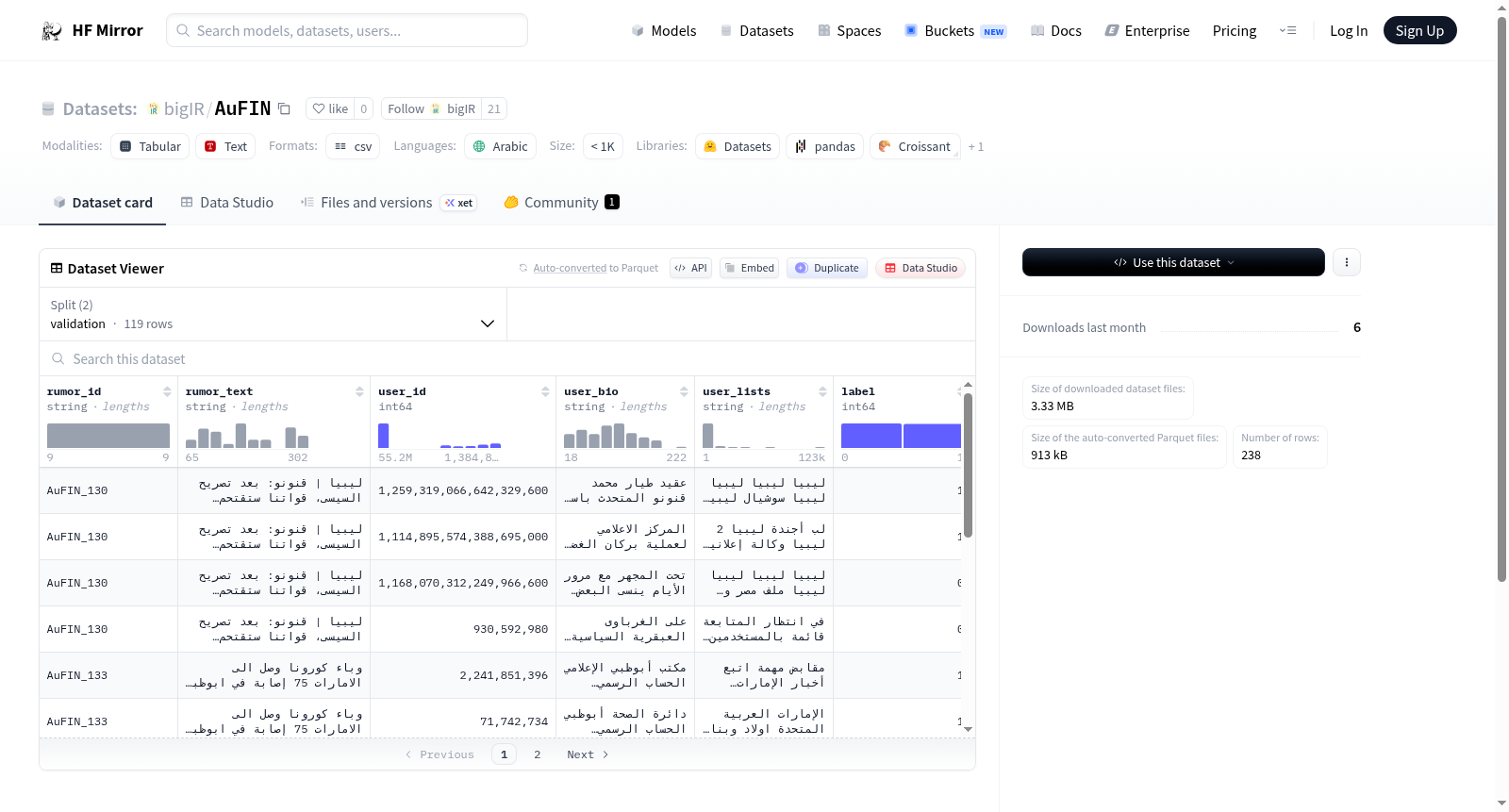
构建方式
在社交媒体信息验证领域,权威用户识别对于遏制谣言传播至关重要。AuFIN数据集的构建基于Twitter平台,采用BM25词汇检索模型,以谣言文本作为查询,用户文档集合作为检索对象。用户文档通过整合翻译后的个人资料名称、描述以及其所有Twitter列表的名称与描述来构建,最终筛选出前5位最相关的用户作为权威候选,为后续的谣言验证研究提供了结构化数据支持。
特点
该数据集专注于阿拉伯语环境下的权威发现任务,填补了非英语社交媒体分析中的空白。其核心特点在于结合了用户的多维度文本信息,包括个人资料和列表内容,并通过翻译处理增强了跨语言适用性。数据以简洁的检索结果形式呈现,直接服务于谣言验证场景,为研究者提供了针对性的实验基础,促进了计算语言学与社会计算领域的交叉探索。
使用方法
研究者可利用AuFIN数据集进行权威用户识别模型的训练与评估,特别是在跨语言信息检索任务中。数据集适用于测试检索算法在真实社交媒体环境下的性能,用户可通过提供的GitHub链接访问完整数据与测试集。在实际应用中,该数据可作为基准,用于比较不同模型在阿拉伯语谣言验证中的效果,推动自动化事实核查技术的发展。
背景与挑战
背景概述
在社交媒体信息验证领域,阿拉伯语权威用户识别研究长期面临数据资源匮乏的困境。2023年由Fatima Haouari等学者构建的AuFIN数据集应运而生,该数据集聚焦于推特平台阿拉伯语谣言验证中的权威发现任务,通过BM25词法检索模型提取与谣言文本相关的Top5用户数据,为用户文档构建提供跨语言特征融合框架。这项发表于《Information Processing & Management》期刊的研究,为阿拉伯语自然语言处理领域建立了首个权威用户定位评估基准,推动了跨语言社交信息可信度分析范式的发展。
当前挑战
该数据集核心挑战体现在双重维度:在领域问题层面,阿拉伯语形态复杂性导致用户特征提取困难,方言与标准语混合现象影响权威性评估,推特动态语境中用户可信度标签存在时空漂移风险;在构建过程中,面临用户文档多源信息整合的技术壁垒,跨语言翻译带来的语义损耗问题,以及社交媒体数据采集面临的伦理合规性约束,这些因素共同制约着权威用户识别模型的泛化能力与可解释性提升。
常用场景
经典使用场景
在社交媒体信息验证领域,AuFIN数据集为阿拉伯语推特平台上的权威用户发现提供了关键支持。该数据集通过BM25词汇检索模型,基于谣言文本作为查询,从用户文档集合中检索出前5位潜在权威用户,其中用户文档整合了翻译后的个人资料、描述以及推特列表信息。这一经典使用场景主要应用于计算语言学和社会计算研究,帮助研究者构建自动化系统,以识别在特定话题中具有影响力的用户,从而为后续的谣言验证工作奠定数据基础。
实际应用
在实际应用层面,AuFIN数据集可被整合到社交媒体监控和事实核查平台中,辅助自动化系统快速定位可能澄清谣言的权威用户。例如,新闻机构或公共健康部门可以利用此类工具,在阿拉伯语推特上追踪疫情或政治事件的相关讨论,及时识别并联系领域专家进行信息核实。这不仅增强了谣言应对的时效性,也为多语言环境下的数字治理提供了技术支撑,促进了在线社区的信息生态健康。
衍生相关工作
围绕AuFIN数据集,已衍生出一系列经典研究工作,包括基于深度学习的权威用户排序模型和跨语言检索框架的优化。相关成果发表在信息处理与管理等期刊,并扩展至CLEF等国际评测任务中,推动了社交媒体权威发现任务的标准化。这些工作不仅深化了对阿拉伯语用户行为模式的理解,还为多语言谣言验证系统的构建提供了可复现的基准,促进了计算社会科学与自然语言处理领域的交叉创新。
以上内容由遇见数据集搜集并总结生成


