christinacdl/hate_speech_dataset
收藏Hugging Face2024-02-08 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/christinacdl/hate_speech_dataset
下载链接
链接失效反馈官方服务:
资源简介:
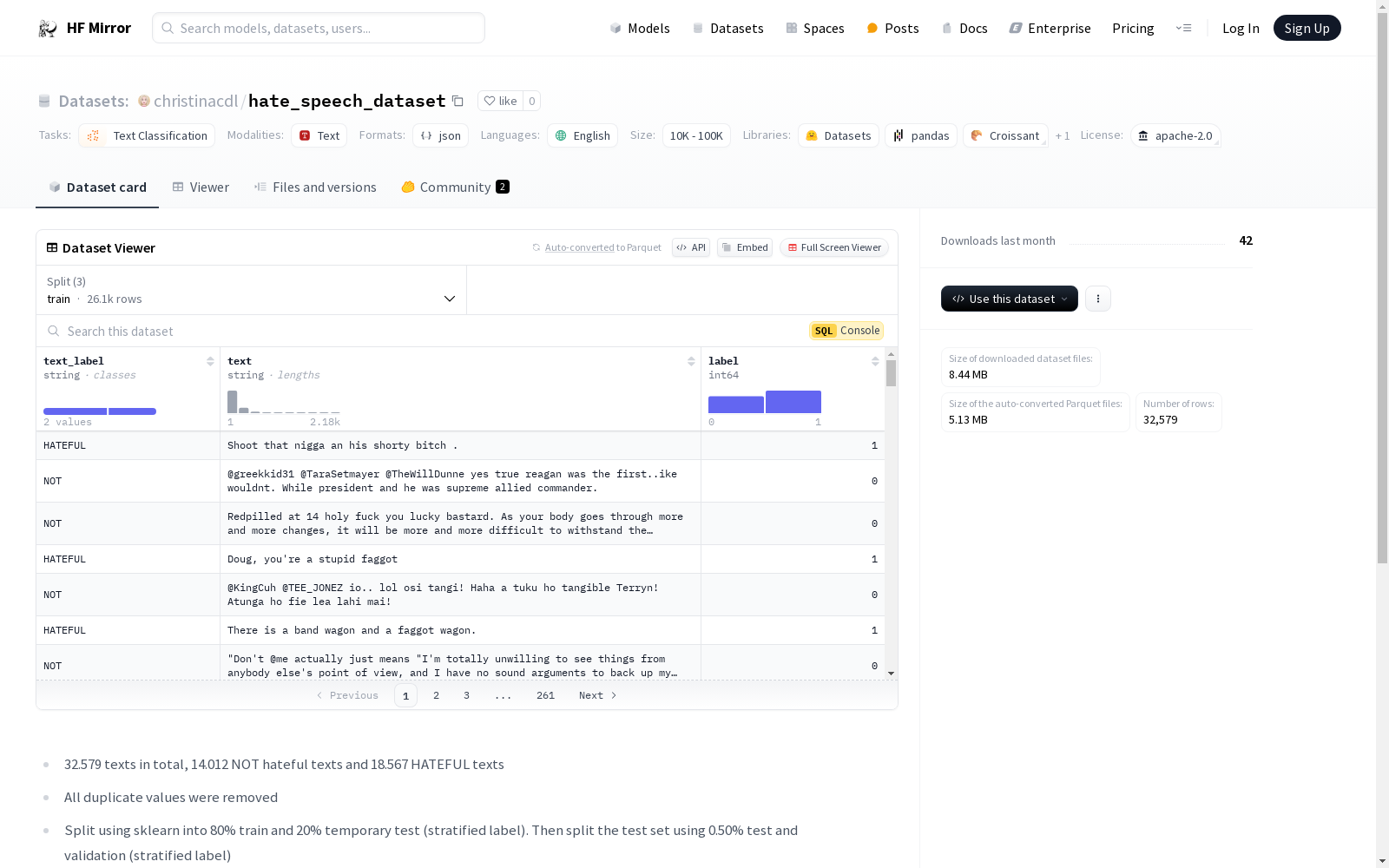
该数据集包含32,579条文本,其中14,012条为非仇恨文本,18,567条为仇恨文本。所有重复值已被移除。数据集使用sklearn进行分割,80%用于训练,20%作为临时测试集(分层标签)。然后测试集进一步分割为50%的测试集和验证集(分层标签)。最终的数据集分割比例为80/10/10。训练集标签分布为:0(非仇恨)11,210条,1(仇恨)14,853条,总计26,063条。验证集标签分布为:0(非仇恨)1,401条,1(仇恨)1,857条,总计3,258条。测试集标签分布为:0(非仇恨)1,401条,1(仇恨)1,857条,总计3,258条。数据集结合了四个公开可用的数据集:1. Ethos数据集(Mollas等,2022),2. HateCheck:仇恨言论检测模型的功能测试(Rottger等,2021),3. 在线仇恨言论干预学习的基准数据集(Qian等,2019),4. 自动仇恨言论检测与冒犯性语言问题(Davidson等,2017)。
This dataset contains 32,579 text instances, among which 14,012 are non-hateful texts and 18,567 are hateful texts. All duplicate entries have been removed. The dataset was split using scikit-learn (sklearn), with 80% allocated for training, and the remaining 20% as a temporary test set with stratified labels. The temporary test set was then further split into 50% test set and 50% validation set, both with stratified labels. The final split ratio of the dataset is 80/10/10. The label distribution of the training set is: 11,210 instances of class 0 (non-hateful) and 14,853 instances of class 1 (hateful), totaling 26,063 instances. The label distribution of the validation set is: 1,401 instances of class 0 (non-hateful) and 1,857 instances of class 1 (hateful), totaling 3,258 instances. The label distribution of the test set is: 1,401 instances of class 0 (non-hateful) and 1,857 instances of class 1 (hateful), totaling 3,258 instances. This dataset is compiled from four publicly available datasets: 1. Ethos dataset (Mollas et al., 2022), 2. HateCheck: Functional Tests for Hate Speech Detection Models (Rottger et al., 2021), 3. Benchmark Dataset for Learning to Intervene in Online Hate Speech (Qian et al., 2019), 4. Automated Hate Speech Detection and the Problem of Offensive Language (Davidson et al., 2017).
提供机构:
christinacdl
原始信息汇总
数据集概述
基本信息
- 许可协议: Apache-2.0
- 任务类别: 文本分类
- 语言: 英语
数据规模
- 总文本数: 32,579条
- 非仇恨文本数: 14,012条
- 仇恨文本数: 18,567条
数据处理
- 去重处理: 所有重复值已被移除
- 数据分割: 使用sklearn进行分割,80%用于训练,20%用于临时测试(按标签分层)。然后将测试集按0.50%分割为测试集和验证集(按标签分层)
- 分割比例: 80/10/10
标签分布
- 训练集:
- 标签0: 11,210条
- 标签1: 14,853条
- 总计: 26,063条
- 验证集:
- 标签0: 1,401条
- 标签1: 1,857条
- 总计: 3,258条
- 测试集:
- 标签0: 1,401条
- 标签1: 1,857条
- 总计: 3,258条
数据来源
- 数据集组合:
- "Ethos"数据集 (Mollas et al., 2022)
- HateCheck: Functional Tests for Hate Speech Detection Models (Rottger et al., 2021)
- A Benchmark Dataset for Learning to Intervene in Online Hate Speech (Qian et al., 2019)
- Automated Hate Speech Detection and the Problem of Offensive Language (Davidson, et al., 2017)
搜集汇总
数据集介绍
构建方式
该数据集通过整合四个公开可用的数据集构建而成,包括'Ethos'数据集、HateCheck数据集、在线仇恨言论干预基准数据集以及自动化仇恨言论检测数据集。所有重复值已被移除,并使用sklearn库进行数据分割,确保标签分布的均衡性。具体而言,数据集被划分为80%的训练集、10%的验证集和10%的测试集,各子集的标签分布保持一致,以支持模型训练和评估的准确性。
使用方法
该数据集适用于文本分类任务,特别是仇恨言论检测模型的训练与评估。用户可以利用80%的训练集进行模型训练,使用10%的验证集进行模型调优,最后通过10%的测试集评估模型性能。数据集的均衡标签分布和多样性确保了模型在实际应用中的鲁棒性和泛化能力。
背景与挑战
背景概述
在当今数字化的社会中,网络仇恨言论的泛滥已成为一个严峻的社会问题,亟需有效的技术手段进行识别与干预。christinacdl/hate_speech_dataset数据集应运而生,由知名研究机构与学者共同构建,旨在为仇恨言论检测提供高质量的训练与评估资源。该数据集汇聚了四个公开可用的数据集,包括'Ethos'、HateCheck、在线仇恨言论干预基准数据集以及自动化仇恨言论检测数据集,总计包含32,579条文本,其中18,567条为仇恨言论,14,012条为非仇恨言论。通过精心设计的分层抽样方法,数据集被划分为80%的训练集、10%的验证集和10%的测试集,确保了各类别数据的均衡分布。这一数据集的发布,不仅为学术界提供了研究仇恨言论检测的新工具,也为工业界开发相关应用提供了坚实的基础。
当前挑战
尽管christinacdl/hate_speech_dataset数据集在仇恨言论检测领域具有重要意义,但其构建与应用过程中仍面临诸多挑战。首先,仇恨言论的定义与边界模糊,不同文化背景和社会环境下的理解差异较大,导致数据标注的一致性和准确性难以保证。其次,数据集的多样性问题也不容忽视,现有数据主要来源于公开数据集,可能存在样本偏差,难以全面反映全球范围内的仇恨言论特征。此外,随着网络语言的快速演变,数据集的时效性也成为一大挑战,需要定期更新以适应新的语言表达形式。最后,如何在保护用户隐私的前提下,有效利用大规模数据进行模型训练,也是当前研究中亟待解决的问题。
常用场景
经典使用场景
在自然语言处理领域,christinacdl/hate_speech_dataset 数据集的经典使用场景主要集中在仇恨言论的自动检测与分类任务上。该数据集通过整合多个公开的仇恨言论数据集,提供了丰富的文本样本,涵盖了不同类型的仇恨言论,为研究者提供了一个标准化的基准,用于训练和评估仇恨言论检测模型。
解决学术问题
该数据集解决了在仇恨言论检测领域中,数据稀缺和标注不一致的常见学术问题。通过整合多个高质量的数据集,christinacdl/hate_speech_dataset 提供了大规模且标注一致的文本数据,有助于提升模型的泛化能力和检测精度,推动了仇恨言论检测技术的发展。
实际应用
在实际应用中,christinacdl/hate_speech_dataset 数据集被广泛应用于社交媒体平台的仇恨言论监控系统中。通过训练高效的仇恨言论检测模型,平台可以实时识别和过滤有害内容,保护用户免受仇恨言论的侵害,提升用户体验和社会责任感。
数据集最近研究
最新研究方向
在文本分类领域,尤其是针对仇恨言论检测的研究中,christinacdl/hate_speech_dataset数据集的引入为该领域的前沿研究提供了丰富的资源。该数据集通过整合多个公开数据集,如'Ethos'、HateCheck等,显著提升了仇恨言论检测模型的鲁棒性和泛化能力。当前的研究方向主要集中在利用该数据集优化深度学习模型,以提高对复杂文本中仇恨言论的识别精度,同时探索模型在不同语言和文化背景下的适应性。此外,该数据集的发布也推动了跨学科合作,特别是在社会学和计算机科学领域,共同探讨仇恨言论的自动检测与干预策略,对构建和谐的网络环境具有重要意义。
以上内容由遇见数据集搜集并总结生成


