Dataset for Supervised Evaluation of Seed-Based Interactive Image Segmentation Algorithms
收藏github2023-09-05 更新2024-05-31 收录
下载链接:
https://github.com/flandrade/dataset-interactive-algorithms
下载链接
链接失效反馈官方服务:
资源简介:
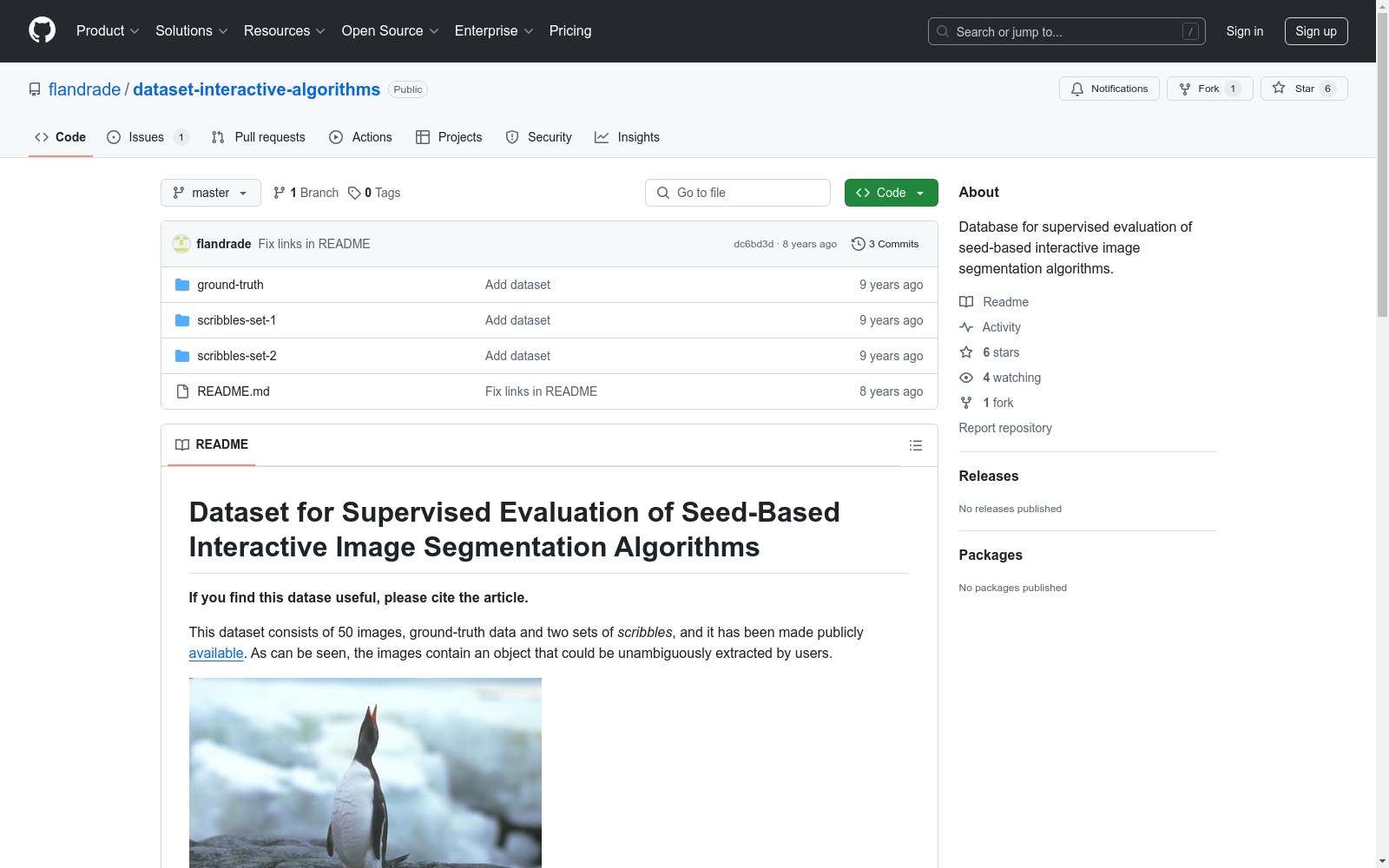
该数据集包含50张图像、地面实况数据和两组涂鸦,用于监督评估种子基交互式图像分割算法。图像中的对象可以明确地被用户提取。
This dataset comprises 50 images, ground truth data, and two sets of scribbles, designed for the supervised evaluation of seed-based interactive image segmentation algorithms. Objects within the images can be distinctly extracted by users.
创建时间:
2017-01-22
原始信息汇总
数据集概述
数据集名称
Dataset for Supervised Evaluation of Seed-Based Interactive Image Segmentation Algorithms
数据集内容
- 包含50张图像
- 包含地真数据
- 包含两套_scribbles_(用户输入标记)
数据集来源
- 原始图像和地真数据来自GrabCut数据库
- 用户输入的第一套_scribbles_来自Geodesic Star Convexit数据集
数据集特点
- 图像中的对象可被用户明确提取
- 两套_scribbles_反映了用户努力的两种程度:第二套比第一套更详细地标记了前景区域
数据集用途
用于监督评估基于种子的交互式图像分割算法
数据集可用性
已公开发布,可访问此链接获取
引用信息
若使用此数据集,请引用以下文章: Andrade F., Carrera E. V., "Supervised evaluation of seed-based interactive image segmentation algorithms", In Proceedings of the 20th Symposium on Image, Signal Processing, and Artificial Vision, ISBN 978-1-4673-9461-1, Bogota, Colombia, pp. 225-231, September 2015. (IEEE)
搜集汇总
数据集介绍
构建方式
该数据集的构建基于公开的GrabCut和Geodesic Star Convexity数据集,原始图像和真实标注数据来源于GrabCut数据库。为了丰富数据集,研究者新增了一组更为详细的涂鸦标注,用于指示前景区域。这些涂鸦标注反映了用户在不同努力程度下的交互输入,第一组涂鸦平均每张图像使用约4笔,而第二组则更为详细地标记了前景区域。
特点
该数据集包含50张图像、真实标注数据以及两组涂鸦标注,图像中的对象能够被用户明确提取。涂鸦标注分为两组,分别代表了用户在交互分割中的不同努力程度。第一组涂鸦标注较为简洁,第二组则更为详细,能够更精确地指示前景区域。这种设计使得数据集能够有效评估基于种子点的交互式图像分割算法的性能。
使用方法
该数据集主要用于评估基于种子点的交互式图像分割算法。用户可以通过两组涂鸦标注进行实验,分别模拟不同努力程度的用户输入。研究者可以利用该数据集对算法的分割精度、鲁棒性等进行定量分析。此外,数据集还提供了真实标注数据,便于算法结果的对比与验证。
背景与挑战
背景概述
该数据集名为“用于基于种子的交互式图像分割算法监督评估的数据集”,由Fernando Andrade和Enrique V. Carrera于2015年创建,旨在为交互式图像分割算法的评估提供标准化的基准。数据集包含50张图像、相应的真实标注数据以及两组用户输入的涂鸦标记,这些涂鸦标记用于指示前景和背景区域。数据集的构建基于公开的GrabCut和Geodesic Star Convexity数据集,并结合了新的涂鸦标记以扩展数据集的多样性。该数据集在图像分割领域具有重要影响力,特别是在交互式分割算法的评估和优化方面,为研究人员提供了可靠的实验平台。
当前挑战
该数据集面临的挑战主要体现在两个方面。首先,交互式图像分割算法的评估本身具有复杂性,如何准确衡量算法在不同用户输入下的表现是一个关键问题。数据集通过提供两组不同精细程度的涂鸦标记,试图模拟不同用户输入的努力程度,但仍需进一步研究如何量化用户输入与算法性能之间的关系。其次,数据集的构建过程中,如何确保涂鸦标记的多样性和代表性也是一个挑战。尽管数据集扩展了原有的涂鸦标记,但仍需考虑更多场景和复杂背景下的图像分割问题,以提升数据集的普适性和实用性。
常用场景
经典使用场景
在图像分割领域,交互式分割算法通过用户提供的种子点或涂鸦来引导分割过程。该数据集为评估基于种子的交互式图像分割算法提供了一个标准化的测试平台。研究人员可以利用该数据集中的50张图像及其对应的真实标注和两组涂鸦数据,来验证和比较不同算法的性能。通过模拟用户输入的不同涂鸦,数据集能够反映不同程度的用户努力,从而帮助研究者评估算法在不同用户输入条件下的鲁棒性和准确性。
解决学术问题
该数据集解决了交互式图像分割算法评估中的关键问题,即如何量化算法在不同用户输入条件下的表现。传统的分割算法评估往往依赖于固定的测试集,而忽略了用户交互的多样性。该数据集通过提供两组不同详细程度的涂鸦数据,使得研究者能够更全面地评估算法在不同用户输入条件下的表现。这不仅为算法优化提供了方向,还为交互式分割算法的标准化评估奠定了基础。
衍生相关工作
该数据集的发布推动了交互式图像分割领域的多项经典工作。基于该数据集,研究者提出了多种改进的交互式分割算法,如基于深度学习的涂鸦引导分割方法和多尺度特征融合技术。此外,该数据集还被用于开发新的评估指标,以更全面地衡量算法在不同用户输入条件下的表现。这些工作不仅丰富了交互式分割算法的研究内容,还为相关领域的实际应用提供了技术支持。
以上内容由遇见数据集搜集并总结生成


