cifar-10-100
收藏Hugging Face2024-12-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/wasifis/cifar-10-100
下载链接
链接失效反馈官方服务:
资源简介:
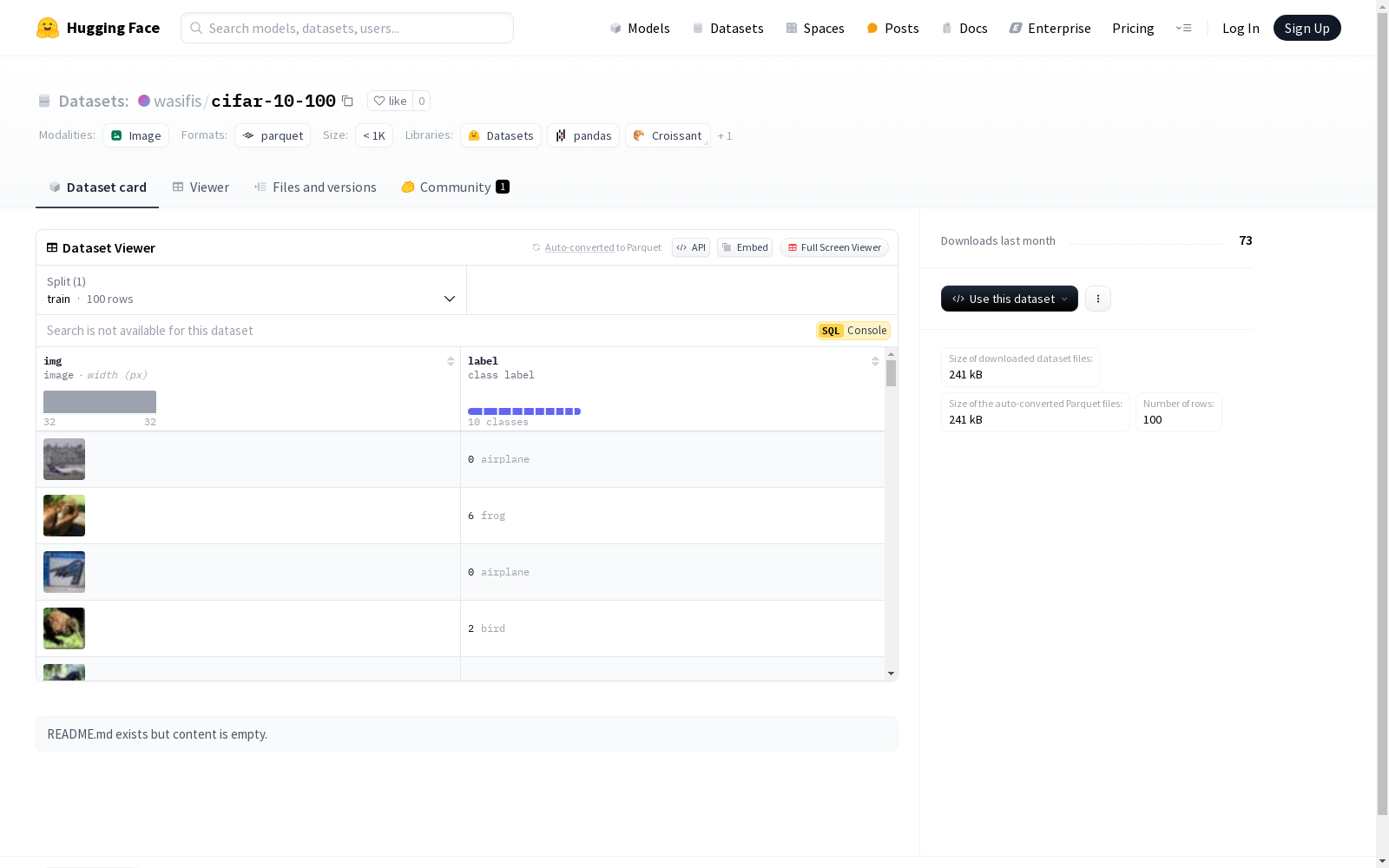
该数据集包含图像和对应的分类标签。图像特征为img,标签特征为label,标签包含10个类别(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车)。数据集仅包含一个训练集,包含100个样本。数据集的总下载大小为241468字节,数据集大小为228576.0字节。
创建时间:
2024-12-01
原始信息汇总
CIFAR-10-100 数据集概述
数据集信息
特征
- img: 图像数据,数据类型为
image。 - label: 标签数据,数据类型为
class_label,包含以下类别:0: airplane1: automobile2: bird3: cat4: deer5: dog6: frog7: horse8: ship9: truck
数据集划分
- train: 训练集,包含 100 个样本,占用 228576.0 字节。
数据集大小
- 下载大小: 241468 字节
- 数据集大小: 228576.0 字节
配置
- config_name: default
- data_files:
- split: train
- path: data/train-*
- data_files:
搜集汇总
数据集介绍
构建方式
CIFAR-10-100数据集的构建基于图像分类任务,精心挑选了100张图像,每张图像对应10个类别之一。这些图像被分为训练集,包含100个样本,每个样本由图像和对应的类别标签组成。图像数据以图像格式存储,而标签则以类别名称的形式标注,确保了数据集的结构清晰且易于处理。
使用方法
使用CIFAR-10-100数据集时,用户可以通过加载训练集进行模型训练。数据集的图像和标签分别存储,便于直接输入到图像分类模型中。用户可以根据需要调整数据预处理步骤,如图像增强或标准化,以优化模型性能。此外,数据集的结构支持快速迭代和实验,适合用于开发和测试新的图像分类算法。
背景与挑战
背景概述
CIFAR-10和CIFAR-100数据集是由加拿大滑铁卢大学的Alex Krizhevsky、Vinod Nair和Geoffrey Hinton于2009年创建的,旨在推动图像分类领域的发展。这两个数据集分别包含10个和100个类别,每个类别包含大量的小尺寸彩色图像,广泛用于评估和训练深度学习模型。CIFAR数据集的出现极大地促进了计算机视觉领域的研究,尤其是在卷积神经网络(CNN)的早期发展阶段,为研究人员提供了一个标准化的基准。
当前挑战
CIFAR-10和CIFAR-100数据集在图像分类领域面临多项挑战。首先,尽管图像尺寸较小,但类别间的视觉相似性增加了分类的难度,尤其是在CIFAR-100中,类别间的细微差异使得模型容易混淆。其次,构建过程中,数据集的平衡性和多样性也是一大挑战,确保每个类别都有足够的样本以避免模型偏差。此外,随着深度学习模型的复杂化,如何在保持高精度的同时减少计算资源的消耗,也是当前研究的重点。
常用场景
经典使用场景
CIFAR-10-100数据集在计算机视觉领域中被广泛用于图像分类任务的基准测试。其经典使用场景包括但不限于:通过训练卷积神经网络(CNN)模型,评估模型在识别飞机、汽车、鸟类、猫等十类常见物体上的性能。该数据集的小样本特性使其成为研究小样本学习、迁移学习等前沿技术的理想选择。
解决学术问题
CIFAR-10-100数据集解决了计算机视觉领域中图像分类模型的基准测试问题。通过提供标准化的图像数据和标签,研究者能够公平地比较不同算法的性能,推动了深度学习模型在图像识别任务中的发展。此外,该数据集还为研究小样本学习、数据增强技术等提供了重要的实验平台。
实际应用
在实际应用中,CIFAR-10-100数据集的训练模型可用于多种场景,如自动驾驶中的道路物体识别、智能监控系统中的目标检测等。通过在CIFAR-10-100上训练的模型,可以快速迁移到其他相似的图像分类任务中,显著提升了实际应用的效率和准确性。
数据集最近研究
最新研究方向
在计算机视觉领域,CIFAR-10和CIFAR-100数据集因其丰富的图像分类任务而备受关注。近年来,研究者们致力于通过深度学习技术提升模型在CIFAR数据集上的表现,尤其是在小样本学习和自监督学习方向上取得了显著进展。这些研究不仅推动了图像分类技术的边界,还为实际应用中的资源受限场景提供了新的解决方案。此外,随着生成对抗网络(GANs)和变分自编码器(VAEs)的发展,CIFAR数据集也被广泛用于图像生成和增强任务,进一步拓展了其在人工智能领域的应用范围。
以上内容由遇见数据集搜集并总结生成


