flair
收藏魔搭社区2025-11-27 更新2025-07-05 收录
下载链接:
https://modelscope.cn/datasets/apple/flair
下载链接
链接失效反馈官方服务:
资源简介:
# Federated Learning Annotated Image Repository (FLAIR): A large labelled image dataset for benchmarking in federated learning
**FLAIR was published at NeurIPS 2022 ([paper](https://arxiv.org/abs/2207.08869))**
**(Preferred) Benchmarking FLAIR is available in pfl-research ([repo](https://github.com/apple/pfl-research/tree/develop/benchmarks/flair), [paper](https://arxiv.org/abs/2404.06430)).**
**The [ml-flair](https://github.com/apple/ml-flair) repo contains a setup for benchmarking with TensorFlow Federated and notebooks for exploring data.**
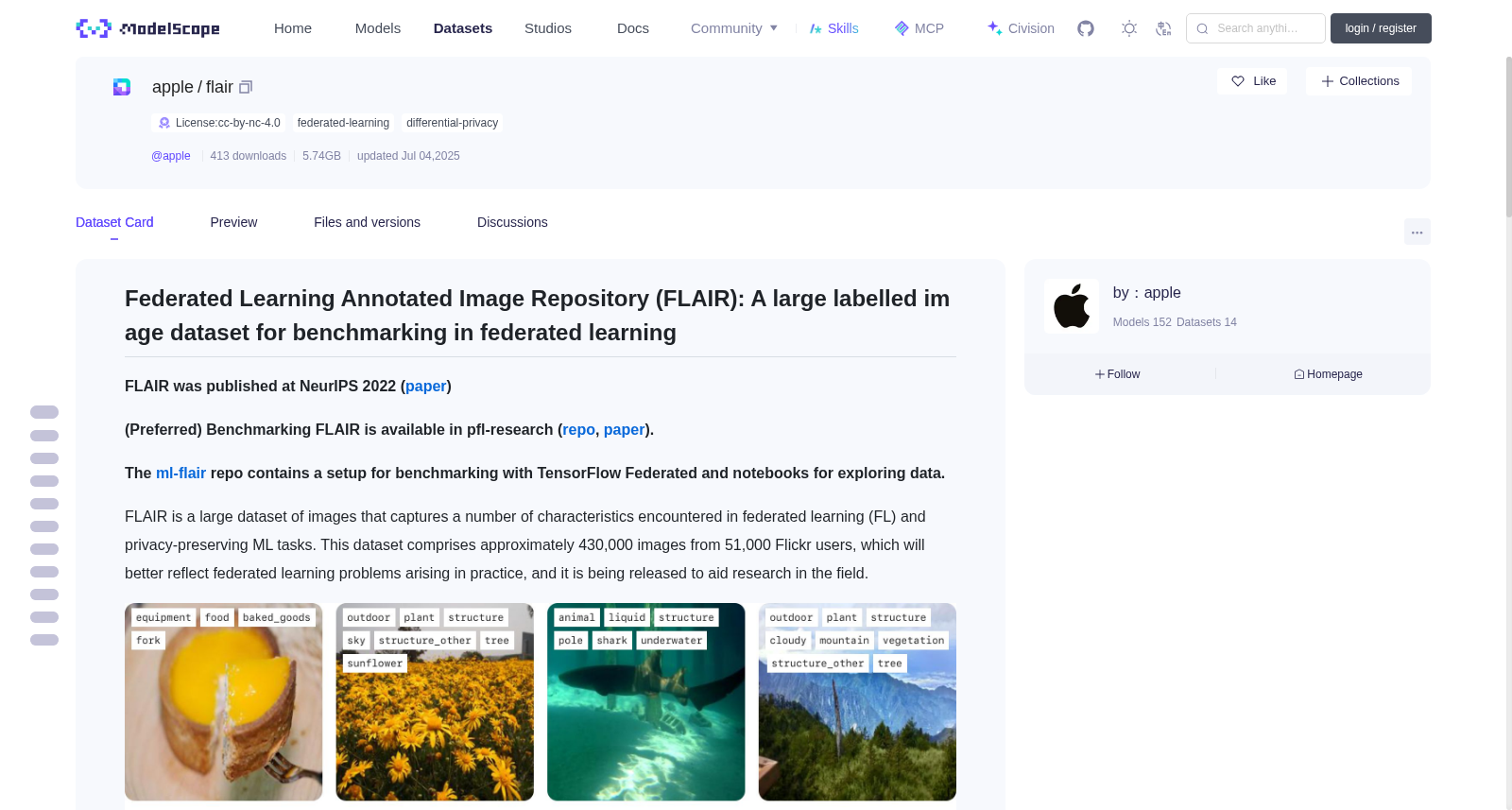
FLAIR is a large dataset of images that captures a number of characteristics encountered in federated learning (FL) and privacy-preserving ML tasks.
This dataset comprises approximately 430,000 images from 51,000 Flickr users, which will better reflect federated learning problems arising in practice, and it is being released to aid research in the field.

## Image Labels
These images have been annotated by humans and assigned labels from a taxonomy of more than 1,600 fine-grained labels.
All main subjects present in the images have been labeled, so images may have multiple labels.
The taxonomy is hierarchical where the fine-grained labels can be mapped to 17 coarse-grained categories.
The dataset includes both fine-grained and coarse-grained labels so researchers can vary the complexity of a machine learning task.
## User Labels and their use for Federated Learning
We have used image metadata to extract artist names/IDs for the purposes of creating user datasets for federated learning.
While optimization algorithms for machine learning are often designed under the assumption that each example is an independent sample from the distribution, federated learning applications deviate from this assumption in a few different ways that are reflected in our user-annotated examples.
Different users differ in the number of images they have, as well as the number of classes represented in their image collection.
Further, images of the same class but taken by different users are likely to have some distribution shift.
These properties of the dataset better reflect federated learning applications, and we expect that benchmark tasks on this dataset will benefit from algorithms designed to handle such data heterogeneity.
## Dataset split
We include a standard train/val/test.
The partition is based on user ids with ratio 8:1:1, i.e. train, val and test sets have disjoint users.
Below are the numbers for each partition:
| Partition | Train | Val | Test |
| ---------------- | ------- | ------ | ------ |
| Number of users | 41,131 | 5,141 | 5,142 |
| Number of images | 345,879 | 39,239 | 43,960 |
We recommend using the provided split for reproducible benchmarks.
## Dataset structure
```
{'user_id': '59769174@N00',
'image_id': 14913474848,
'labels': ['equipment', 'material', 'structure'],
'partition': 'train',
'fine_grained_labels': ['bag', 'document', 'furniture', 'material', 'printed_page'],
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=256x256>}
```
Field `image_id` is the Flickr PhotoID and `user_id` is the Flickr NSID that owns the image.
Group by `user_id` to construct a realistic heterogeneous federated dataset.
Field `partition` denotes which `train/dev/test` partition the image belongs to.
Field `fine_grained_labels` is a list of annotated labels presenting the subjects in the image and `labels` is the list of coarse-grained labels obtained by mapping fine-grained labels to higher-order categories.
The file `label_relationship.txt` includes the mapping from ~1,600 fine-grained labels to 17 higher-order categories.
## (Recommended) Benchmark FLAIR with pfl-research
Available at https://github.com/apple/pfl-research/tree/develop/benchmarks/flair.
## Benchmark FLAIR with TensorFlow Federated
Available at https://github.com/apple/ml-flair.
This repo also provide scripts to explore the images and labels in more detail.
## Prepare the dataset in HDF5
We found a single HDF5 file to be efficient for FL.
If you want to process the dataset for general usage in FL, we recommend using [this preprocessing script](https://github.com/apple/pfl-research/blob/develop/benchmarks/dataset/flair/download_preprocess.py) to construct a HDF5 file.
By default the script will group the images and labels by train/val/test split and then by user ids, making it suitable for federated learning experiments.
With the flag `--not_group_data_by_user`, the script will simply group the images and labels by train/val/test split and ignore the user ids, which is the typical setup for centralized training. \
⚠️ Warning: the hdf5 file take up to ~80GB disk space to store after processing.
## Use dataset directly with HuggingFace
The dataset can also be used with the `datasets` package.
To group datapoints by user, simply construct a mapping and then query the dataset by index:
```
from datasets import load_dataset
from collections import defaultdict
ds = load_dataset('apple/flair', split='val')
user_to_ix = defaultdict(list)
for i, record in enumerate(ds):
user_to_ix[record['user_id']].append(i)
def load_user_data(user_id):
return [ds[i] for i in user_to_ix[user_id]]
load_user_data('81594342@N00')
```
## Disclaimer
The annotations and Apple’s other rights in the dataset are licensed under CC-BY-NC 4.0 license.
The images are copyright of the respective owners, the license terms of which can be found using the links provided in ATTRIBUTIONS.TXT (by matching the Image ID).
Apple makes no representations or warranties regarding the license status of each image and you should verify the license for each image yourself.
## Citing FLAIR
```
@article{song2022flair,
title={FLAIR: Federated Learning Annotated Image Repository},
author={Song, Congzheng and Granqvist, Filip and Talwar, Kunal},
journal={Advances in Neural Information Processing Systems},
volume={35},
pages={37792--37805},
year={2022}
}
```
# 联邦学习标注图像库(FLAIR):用于联邦学习基准测试的大规模标注图像数据集
**FLAIR 已于 NeurIPS 2022 发表 ([论文链接](https://arxiv.org/abs/2207.08869))**
**推荐的FLAIR基准测试实现可在pfl-research中获取 ([代码仓库](https://github.com/apple/pfl-research/tree/develop/benchmarks/flair),[论文链接](https://arxiv.org/abs/2404.06430))**。
**[ml-flair](https://github.com/apple/ml-flair) 仓库包含了基于TensorFlow Federated的基准测试搭建脚本与数据探索笔记。**
FLAIR是一个大规模图像数据集,涵盖了联邦学习(Federated Learning, FL)与隐私保护机器学习任务中常见的多种特性。该数据集包含来自51000名Flickr用户的约430000张图像,能够更真实地反映实际场景中的联邦学习问题,其发布旨在助力该领域的研究工作。

## 图像标签
所有图像均经过人工标注,并采用包含1600余个细粒度标签的分类体系进行标记。图像中出现的所有主要主体均被标注,因此单张图像可能包含多个标签。该分类体系具有层级结构,细粒度标签可映射至17个粗粒度类别。数据集同时提供细粒度与粗粒度标签,研究人员可据此调整机器学习任务的复杂度。
## 用户标签及其在联邦学习中的应用
我们利用图像元数据提取了作者姓名/ID,以构建用于联邦学习的用户级数据集。尽管机器学习优化算法通常假设每个样本独立同分布,但联邦学习应用在多个维度上违背了这一假设,而我们的用户标注样本正是对这一特性的体现。不同用户拥有的图像数量各不相同,其图像集合所覆盖的类别数量也存在差异。此外,同一类别下由不同用户拍摄的图像往往存在一定的分布偏移。该数据集的这些特性更贴合实际联邦学习应用场景,我们期望基于此数据集的基准测试任务能够助力针对此类数据异质性设计的算法研究。
## 数据集划分
我们采用标准的训练集/验证集/测试集划分方式。划分基于用户ID进行,比例为8:1:1,即训练集、验证集与测试集的用户完全互斥。各划分的统计数据如下:
| 划分方式 | 训练集 | 验证集 | 测试集 |
| ---------------- | ------- | ------ | ------ |
| 用户数量 | 41131 | 5141 | 5142 |
| 图像数量 | 345879 | 39239 | 43960 |
我们推荐使用官方提供的划分方式以保证基准测试的可复现性。
## 数据集结构
{'user_id': '59769174@N00',
'image_id': 14913474848,
'labels': ['equipment', 'material', 'structure'],
'partition': 'train',
'fine_grained_labels': ['bag', 'document', 'furniture', 'material', 'printed_page'],
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=256x256>}
其中`image_id`为Flickr照片ID,`user_id`为图像所属Flickr用户的NSID。按`user_id`进行分组即可构建符合实际场景的异构联邦学习数据集。`partition`字段表示该图像所属的`train/dev/test`划分。`fine_grained_labels`为标注的图像主体标签列表,`labels`为将细粒度标签映射至高阶类别后得到的粗粒度标签列表。文件`label_relationship.txt`包含了从约1600个细粒度标签到17个高阶类别的映射关系。
## (推荐)基于pfl-research的FLAIR基准测试
实现地址:https://github.com/apple/pfl-research/tree/develop/benchmarks/flair。
## 基于TensorFlow Federated的FLAIR基准测试
实现地址:https://github.com/apple/ml-flair。该仓库同时提供了用于深入探索图像与标签的脚本。
## 转换为HDF5格式的数据集
我们发现单个HDF5文件能够高效支持联邦学习任务。若您需要将该数据集用于通用联邦学习场景,我们推荐使用[该预处理脚本](https://github.com/apple/pfl-research/blob/develop/benchmarks/dataset/flair/download_preprocess.py)来构建HDF5文件。
默认情况下,该脚本会先按照训练/验证/测试划分分组,再按用户ID进行分组,以适配联邦学习实验场景。若添加`--not_group_data_by_user`标志,脚本将仅按训练/验证/测试划分分组,忽略用户ID,这适用于中心化训练的常规场景。
⚠️ 注意:处理后的HDF5文件将占用最多约80GB的磁盘存储空间。
## 直接通过HuggingFace使用数据集
该数据集也可通过`datasets`包直接使用。若需按用户对数据点进行分组,可构建映射表后通过索引查询数据集:
from datasets import load_dataset
from collections import defaultdict
ds = load_dataset('apple/flair', split='val')
user_to_ix = defaultdict(list)
for i, record in enumerate(ds):
user_to_ix[record['user_id']].append(i)
def load_user_data(user_id):
return [ds[i] for i in user_to_ix[user_id]]
load_user_data('81594342@N00')
## 免责声明
本数据集的标注内容与Apple享有的其他相关权利均采用CC-BY-NC 4.0许可协议进行授权。图像版权归各自所有者所有,其许可条款可通过ATTRIBUTIONS.TXT文件中的链接(匹配图像ID)查询。Apple不对每张图像的许可状态作出任何陈述或保证,您需自行验证每张图像的许可情况。
## 引用FLAIR
@article{song2022flair,
title={FLAIR: Federated Learning Annotated Image Repository},
author={Song, Congzheng and Granqvist, Filip and Talwar, Kunal},
journal={Advances in Neural Information Processing Systems},
volume={35},
pages={37792--37805},
year={2022}
}
提供机构:
maas创建时间:
2025-07-04
搜集汇总
数据集介绍
背景与挑战
背景概述
FLAIR是一个专为联邦学习(FL)和隐私保护机器学习任务设计的大规模图像数据集,包含约43万张来自5.1万名Flickr用户的图片,每张图片均有人工标注的细粒度标签(超1600个)并可映射到17个粗粒度类别。数据集按用户ID划分训练/验证/测试集,强调用户间的数据异质性和分布偏移,以更好地模拟真实联邦学习场景中的挑战。
以上内容由遇见数据集搜集并总结生成


