Seeing Culture Benchmark (SCB)
收藏arXiv2025-09-20 更新2025-09-24 收录
下载链接:
https://seeingculture-benchmark.github.io
下载链接
链接失效反馈官方服务:
资源简介:
Seeing Culture Benchmark (SCB) 是一个旨在评估视觉语言模型 (VLM) 在文化推理方面的基准数据集。该数据集由来自七个东南亚国家的 1,065 张图像组成,这些图像涵盖了 138 种文化元素,分为五个类别:音乐、游戏、舞蹈、庆祝和婚礼。数据集还包含 3,178 个问题,其中 1,093 个是独特且经过人类标注者精心策划的。SCB 的创建过程涉及使用大型语言模型 ChatGPT 生成文化概念,并通过调查收集来自当地个体的反馈以验证这些概念。该数据集旨在解决 VLM 在处理跨文化场景时视觉推理和空间定位之间的差异问题。
Seeing Culture Benchmark (SCB) is a benchmark dataset designed to evaluate Vision-Language Models (VLMs) for cultural reasoning. This dataset comprises 1,065 images sourced from seven Southeast Asian countries, covering 138 distinct cultural elements and categorized into five categories: music, games, dance, celebrations, and weddings. The dataset also includes 3,178 questions, of which 1,093 are unique and carefully curated by human annotators. The development of SCB involved generating cultural concepts using ChatGPT, a Large Language Model (LLM), and collecting feedback from local participants via surveys to validate these concepts. This dataset aims to address the discrepancy between the visual reasoning and spatial localization capabilities of VLMs when handling cross-cultural scenarios.
提供机构:
新加坡管理大学,万隆理工学院
创建时间:
2025-09-20
搜集汇总
数据集介绍
构建方式
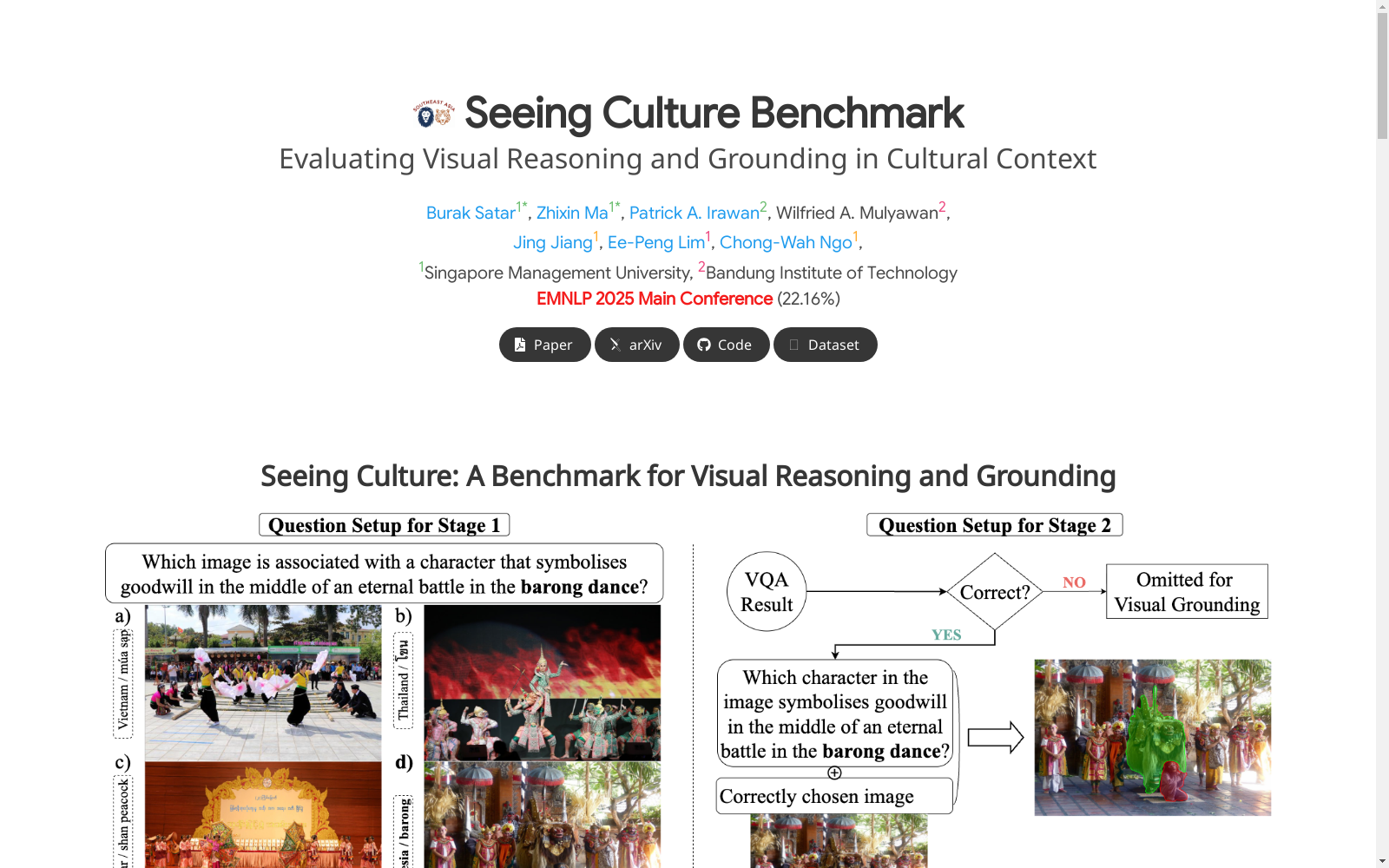
Seeing Culture Benchmark (SCB) 采用分层框架构建文化元素分类体系,涵盖东南亚七国的音乐、游戏、舞蹈、庆典和婚礼五大类别。通过大型语言模型初步生成文化概念建议后,由当地文化背景的标注者进行概念验证与图像筛选。图像采集过程中严格遵循六项过滤标准,包括文化相关性、真实场景呈现、无重复性、避免文化器物完全遮挡、包含干扰性文化元素以及图像清晰度要求。最终从约20,000张初始图像中精选出1,065张符合复杂场景要求的图像,并采用多边形标注工具对文化器物进行精细分割。
使用方法
使用SCB进行评估时,首先向模型提供包含文本问题和四个视觉选项的多选VQA任务,模型需输出对应选项编号。正确答案进入第二阶段的空间定位任务,模型需根据问题生成与文化术语相关的分割掩码。评估采用交并比衡量预测区域与真实标注的重合度。问题类型按视觉选项来源分为三类:同国文化选项侧重细粒度文化区分,跨国文化选项考察跨文化辨识能力,混合类型则平衡两者挑战。该基准特别适用于检验多模态模型在文化敏感场景中的跨模态推理与空间定位协同能力。
背景与挑战
背景概述
Seeing Culture Benchmark(SCB)作为2025年由新加坡管理大学和万隆理工学院联合推出的跨模态文化推理基准,标志着视觉语言模型在文化理解领域的重要进展。该数据集聚焦于东南亚七国被长期忽视的文化多样性,通过1,065张涵盖音乐、舞蹈、游戏等五大类别的文化场景图像,构建了3,178道需进行两阶段推理的问题。其创新性在于将多选视觉问答与文化器物分割相结合,要求模型先识别文化关联图像,再通过分割提供推理证据,从而推动视觉语言模型从表层识别向深度文化语义理解的跨越。
当前挑战
SCB直面文化推理任务中模型跨模态对齐的深层挑战:其一,在相同文化语境下(如单一国家同类器物),模型因缺乏显性地域线索而表现显著下降,揭示其依赖表面语境而非深层文化语义的局限;其二,构建过程中需克服文化表征的复杂性,包括人工筛选含干扰项的真实场景图像、避免AI生成问题导致的文化失真,以及通过本土专家验证确保问题文化准确性。这些挑战凸显了在保持文化真实性与可扩展性之间寻求平衡的难度。
常用场景
经典使用场景
Seeing Culture Benchmark(SCB)作为多模态视觉语言模型文化推理能力的评估基准,其经典应用场景体现在两阶段评估框架中。第一阶段要求模型通过多选视觉问答从文化背景相似的图像中识别特定文化器物,第二阶段则需对正确选项中的文化器物进行语义分割以提供推理证据。该数据集聚焦东南亚七国138种文化器物,涵盖音乐、舞蹈、游戏等五大类别,通过包含干扰物的复杂图像场景,有效检验模型在跨文化语境下的视觉推理与空间定位能力。
解决学术问题
SCB针对现有文化数据集存在的三大局限提出解决方案:其一,通过人工标注的独特问题设计,克服了AI生成问题在文化表达真实性上的不足;其二,引入包含干扰物的复杂图像,突破了传统数据集中文化器物孤立呈现的简化场景;其三,首创两阶段评估机制,将文化理解从简单的器物识别提升至符号意义推理层面。该数据集为衡量模型在文化敏感场景中的跨模态推理差距提供了量化依据,推动了文化认知计算范式的革新。
实际应用
该数据集的实际应用价值体现在全球化数字服务中的文化适配场景。例如,在跨国教育平台中,SCB可辅助评估AI系统对东南亚传统舞蹈服饰符号意义的理解精度;在文化遗产数字化领域,其分割标注体系能为文物自动标注系统提供训练样本;在跨文化人机交互场景中,数据集构建的复杂推理链条有助于提升智能助手对民俗仪式问题的应答准确性。这些应用显著增强了AI系统在多元文化环境下的服务包容性。
数据集最近研究
最新研究方向
在跨模态文化理解研究领域,Seeing Culture Benchmark (SCB) 的最新进展聚焦于提升视觉语言模型在文化推理与空间定位方面的能力。该数据集通过两阶段评估框架——多选视觉问答与文化器物分割,系统检验模型对东南亚七国文化场景的深层语义解析。前沿研究揭示,模型在跨文化选项(Type 2)中表现最佳,而同文化选项(Type 1)因缺乏地域线索暴露出推理盲区,凸显文化先验知识对模型决策的关键影响。此外,视觉推理与空间定位间的显著差距表明,模型虽能完成表面任务,却难以提供可解释的视觉证据。这一发现推动了针对文化敏感场景的细粒度评估范式革新,为构建更具包容性的多模态模型提供了重要基准。
相关研究论文
- 1Seeing Culture: A Benchmark for Visual Reasoning and Grounding新加坡管理大学,万隆理工学院 · 2025年
以上内容由遇见数据集搜集并总结生成


