nagri-sound-dataset
收藏Hugging Face2025-12-20 更新2025-12-21 收录
下载链接:
https://huggingface.co/datasets/shivdi1999/nagri-sound-dataset
下载链接
链接失效反馈官方服务:
资源简介:
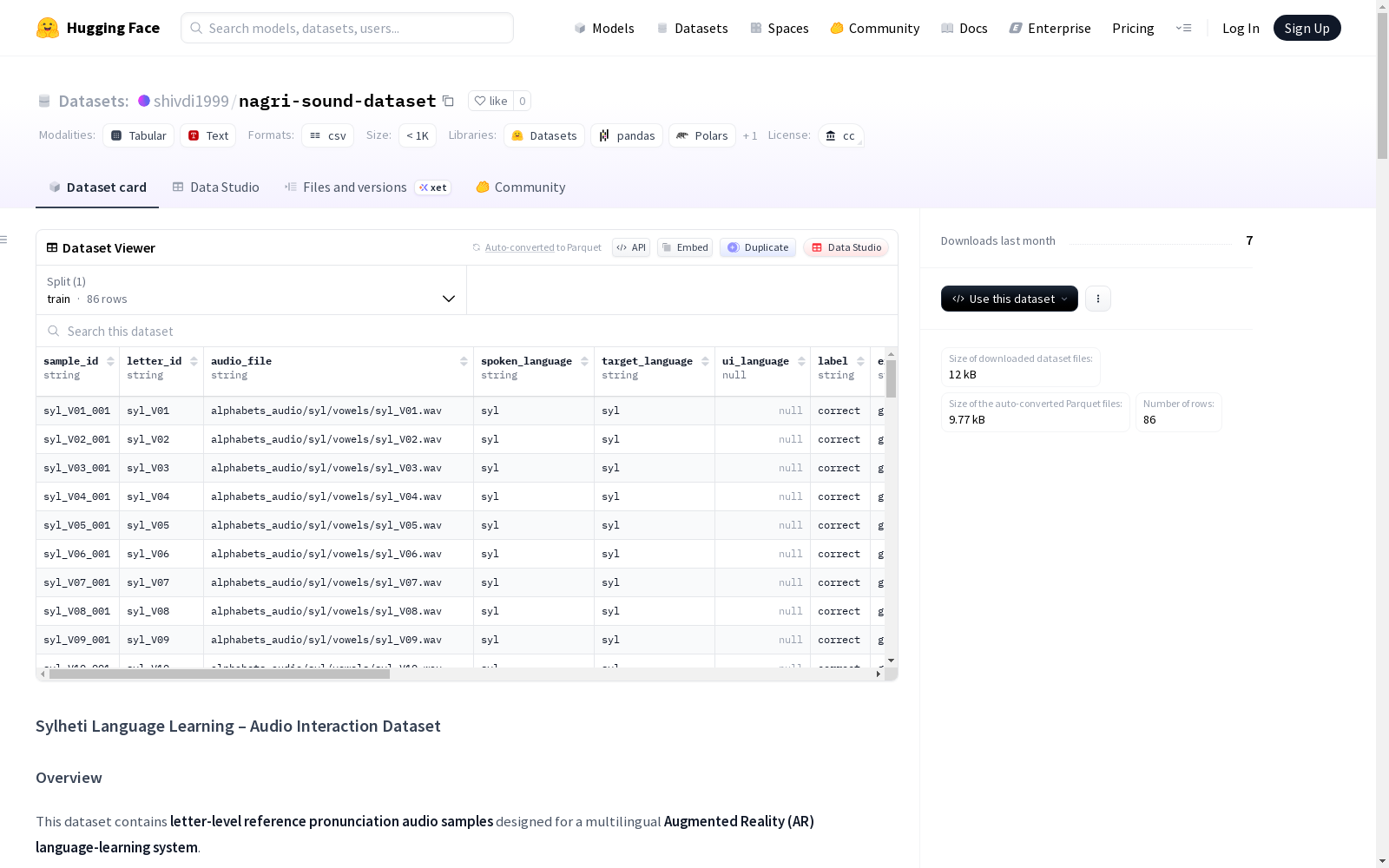
该数据集包含字母级别的参考发音音频样本,专为多语言增强现实(AR)语言学习系统设计。系统根据用户偏好动态调整界面语言,主要目标是教授和评估Sylheti语的发音。数据集的结构支持实时发音反馈、确定性AR触发以及使用Unity和Python的多语言扩展。当前版本主要关注Sylheti语(syl)字母发音,未来计划支持孟加拉语(bn)和其他语言。数据集通过分离语言角色(spoken_language、target_language、ui_language)来避免歧义,确保评估和反馈的清晰性。数据集还包含详细的列定义、字母识别逻辑和样本识别逻辑,适用于字母级发音评估、AR语言学习体验、Unity XR交互逻辑等应用。
创建时间:
2025-12-18
原始信息汇总
Sylheti Language Learning – Audio Interaction Dataset 概述
数据集简介
该数据集包含为多语言增强现实(AR)语言学习系统设计的字母级参考发音音频样本。系统根据用户偏好动态调整其界面语言,主要目标是教授和评估锡尔赫特语的发音。数据集的结构旨在支持使用Unity和Python的实时发音反馈、确定性AR触发和多语言可扩展性。数据集当前专注于**锡尔赫特语(syl)字母发音,其结构旨在支持未来版本纳入孟加拉语(bn)**及其他语言。
语言设计
为避免口语输入、学习目标和界面语言之间的歧义,数据集将语言角色分离如下:
- spoken_language:录音样本中使用的语言(例如
syl、bn)。 - target_language:系统正在教授或评估的目标语言(当前所有参考样本均为锡尔赫特语)。
- ui_language:AR界面和反馈系统使用的语言(在Unity运行时动态处理,数据集中有意留空)。
数据集结构
数据集中的每一行代表一个字母的单个参考发音样本。 音频文件存储在外部,并通过相对路径引用。
文件夹结构
alphabets_audio/ ├── syl/ │ ├── vowels/ │ │ ├── syl_V01.wav │ │ └── ... │ └── consonants/ │ ├── syl_C01.wav │ └── ... ├── bn/ (未来扩展) │ ├── vowels/ │ └── consonants/
列定义
| 列名 | 描述 |
|---|---|
sample_id |
特定音频样本的唯一标识符 |
letter_id |
字母的规范标识符(语言 + 元音/辅音 + 索引) |
audio_file |
.wav音频文件的相对路径 |
spoken_language |
音频样本中使用的语言 |
target_language |
系统正在教授或评估的语言 |
ui_language |
AR界面使用的语言(运行时控制) |
label |
参考音频的真实标签(correct) |
expected_response |
预期的AR反馈(例如 green_tick) |
environment |
录音环境(例如 indoor, outdoor) |
duration_ms |
音频样本的长度(毫秒) |
noise_level |
近似背景噪音水平 |
user_age_group |
说话者的年龄组 |
mic_type |
用于录音的麦克风或设备类型 |
confidence_score |
标注者置信度分数(0–1范围) |
annotator_id |
标注者的匿名标识符 |
spectrogram_path |
频谱图图像的可选路径(v0.x版本中未使用) |
unity_action_id |
此样本触发的Unity AR动作 |
gesture_expected |
AR体验中预期的用户手势 |
字母标识逻辑
letter_id 编码了语言、语音类别和索引:
- 锡尔赫特语元音:
syl_V01、syl_V02、… - 锡尔赫特语辅音:
syl_C01、syl_C02、… - 孟加拉语元音:
bn_V01、bn_V02、… - 孟加拉语辅音:
bn_C01、bn_C02、…
样本标识逻辑
sample_id
格式:<letter_id>_<sample_index>,例如 syl_V01_001。
- 每个字母以
_001开始。 - 同一字母的额外录音可能使用
_002、_003等。 sample_id代表一个录音实例,而letter_id代表语言学概念。
预期用途
该数据集预期用于:
- 字母级发音评估
- 基于AR的语言学习体验
- Unity XR交互逻辑
- 基于Python的音频相似性和评分流程
- 多语言教育研究
该数据集不适用于:
- 句子级自动语音识别
- 对话语音建模
- 大词汇量语音识别
局限性
- 当前版本中每个字母仅有一位参考说话者
- 受控的录音条件
- 无句子级或单词级数据
- 未详尽代表锡尔赫特语内部的方言变体
伦理考量
- 不包含个人身份信息
- 说话者元数据仅以粗略类别存储
- 音频数据是在知情同意下为研究和教育用途收集的
- 数据集旨在支持包容性、非提取性的语言学习应用
许可证
该数据集根据知识共享署名 4.0 国际 (CC BY 4.0) 许可证发布。
搜集汇总
数据集介绍
构建方式
在增强现实语言学习系统的背景下,nagri-sound-dataset的构建聚焦于字母级发音参考样本的采集。数据集通过结构化设计,明确区分了口语语言、目标语言和界面语言的角色,以支持多语言扩展。音频样本以.wav格式存储,并采用相对路径引用,每个样本对应一个字母的唯一发音实例,辅以详细的元数据标注,如环境噪声、说话者年龄组和录音设备类型,确保了数据在实时发音反馈和确定性AR触发中的适用性。
使用方法
数据集主要应用于字母级发音评估和增强现实语言学习体验的开发。在Unity XR环境中,样本可用于触发确定的AR动作和反馈;在Python评估流程中,则支持基于音频相似性的发音评分。使用时需依据样本的letter_id和spoken_language字段匹配目标语言教学逻辑,并参考expected_response和gesture_expected字段设计交互反馈。该数据集不适用于句子级语音识别或会话建模,其价值体现在为多语言教育研究提供精细化的发音基准。
背景与挑战
背景概述
在增强现实与语言教育技术融合的背景下,nagri-sound-dataset应运而生,旨在为多语言AR语言学习系统提供字母级参考发音音频样本。该数据集由相关研究团队构建,核心研究问题聚焦于通过动态界面语言适配,实现针对锡尔赫特语发音的实时反馈与确定性AR触发,以支持发音评估与交互式学习。其设计体现了对低资源语言技术支持的关注,为多模态教育应用及语音处理研究提供了结构化数据基础,推动了AR在教育语言学领域的创新应用。
当前挑战
该数据集致力于解决AR驱动语言学习中字母级发音评估的挑战,包括在多变环境噪声下确保音频质量一致性、实现多语言扩展的框架兼容性,以及为低资源语言构建标准化发音库的困难。在构建过程中,挑战主要集中于采集锡尔赫特语等语言在可控条件下的纯净发音样本,设计分离语音、目标与界面语言的清晰逻辑结构以消除歧义,并确保数据标注与Unity XR交互逻辑的无缝集成,同时需在伦理规范下处理语音数据的匿名化与多年龄组覆盖问题。
常用场景
经典使用场景
在增强现实语言学习领域,nagri-sound-dataset为字母级发音评估提供了核心音频资源。该数据集专为多语言AR系统设计,通过动态适配界面语言,聚焦于锡尔赫特语字母的标准发音教学。其结构化音频样本支持实时发音反馈与确定性AR触发,典型应用场景包括构建交互式语言学习环境,其中系统依据用户发音与参考音频的相似度,即时提供视觉或听觉反馈,从而强化学习效果。
解决学术问题
该数据集有效应对了低资源语言发音教学中的标准化与可扩展性挑战。在学术研究中,它为解决多语言环境下发音评估的基准缺失问题提供了数据基础,尤其支持锡尔赫特语这类资源有限语言的语音学研究。通过明确区分口语语言、目标语言与界面语言,数据集为跨语言语音比较、发音错误检测算法开发以及自适应学习系统的构建提供了清晰框架,推动了教育技术与计算语言学在少数语言保护方面的交叉进展。
实际应用
在实际应用中,nagri-sound-dataset可直接集成于增强现实语言学习平台,用于开发沉浸式发音训练应用。例如,在移动AR应用中,学习者通过模仿数据集中的标准发音,系统利用音频比对技术生成即时反馈,如绿色勾选动画,以纠正发音偏差。此外,数据集的结构支持未来扩展至孟加拉语等其他语言,为多语言教育工具的开发提供了可复用的数据管道,适用于学校、社区中心或家庭自学等多样化教育场景。
数据集最近研究
最新研究方向
在增强现实与语言教育技术融合的背景下,nagri-sound-dataset为低资源语言学习提供了关键支持。该数据集聚焦于锡尔赫特语字母级发音样本,其设计支持动态多语言界面与实时发音反馈,正推动AR语言学习系统向个性化与自适应方向发展。前沿研究探索如何结合深度学习模型,利用该数据集的音频样本进行发音质量评估,并整合手势交互与多模态反馈,以提升沉浸式学习体验。同时,数据集中语言角色的清晰分离为跨语言迁移学习与语音合成技术的应用奠定了基础,助力保护语言多样性并促进教育公平。
以上内容由遇见数据集搜集并总结生成


