UNIGEN
收藏arXiv2024-06-28 更新2024-07-22 收录
下载链接:
https://unigen-framework.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
UNIGEN是由华中科技大学等机构开发的统一文本数据集生成框架,利用大型语言模型如GPT-4和Llama3生成多样化、准确且高度可控的数据集。该框架支持多种文本数据集,通过属性引导生成和组检查增强数据多样性,采用基于代码的数学评估和检索增强生成技术确保数据准确性。UNIGEN的应用领域包括大型语言模型的基准测试和数据增强,旨在解决数据生成中的泛化、可控性、多样性和真实性问题。
UNIGEN is a unified text dataset generation framework developed by Huazhong University of Science and Technology and other institutions. Leveraging large language models (LLMs) such as GPT-4 and Llama3, it generates diverse, accurate, and highly controllable datasets. The framework supports a wide range of text datasets, enhancing data diversity via attribute-guided generation and group-level checking, while adopting code-based mathematical evaluation and retrieval-augmented generation techniques to ensure data accuracy. Its application scenarios include benchmark testing and data augmentation for large language models, aiming to address the core challenges of generalization, controllability, diversity, and authenticity in data generation.
提供机构:
华中科技大学, 圣母大学, 马里兰大学学院市分校, 微软研究院, 威斯康星大学麦迪逊分校, 理海大学
创建时间:
2024-06-27
原始信息汇总
数据集概述
数据集标题
UniGen: A Unified Framework for Textual Dataset Generation Using Large Language Models
数据集描述
评估基础模型在视觉上下文中的数学推理能力。
关键词
MathVista, Math Vista
作者信息
-
主要作者:
- Siyuan Wu (Huazhong University of Science and Technology)
- Yue Huang (University of Notre Dame)
- Chujie Gao (Huazhong University of Science and Technology)
- Dongping Chen (Huazhong University of Science and Technology)
- Qihui Zhang (Huazhong University of Science and Technology)
- Yao Wan (Huazhong University of Science and Technology)
- Tianyi Zhou (University of Maryland, College Park)
- Xiangliang Zhang (University of Notre Dame)
- Jianfeng Gao (Microsoft Research)
- Chaowei Xiao (University of Wisconsin-Madison)
- Lichao Sun (Lehigh University)
-
贡献声明:
-
- Equal Contribution
- † Corresponding Author
-
相关链接
搜集汇总
数据集介绍
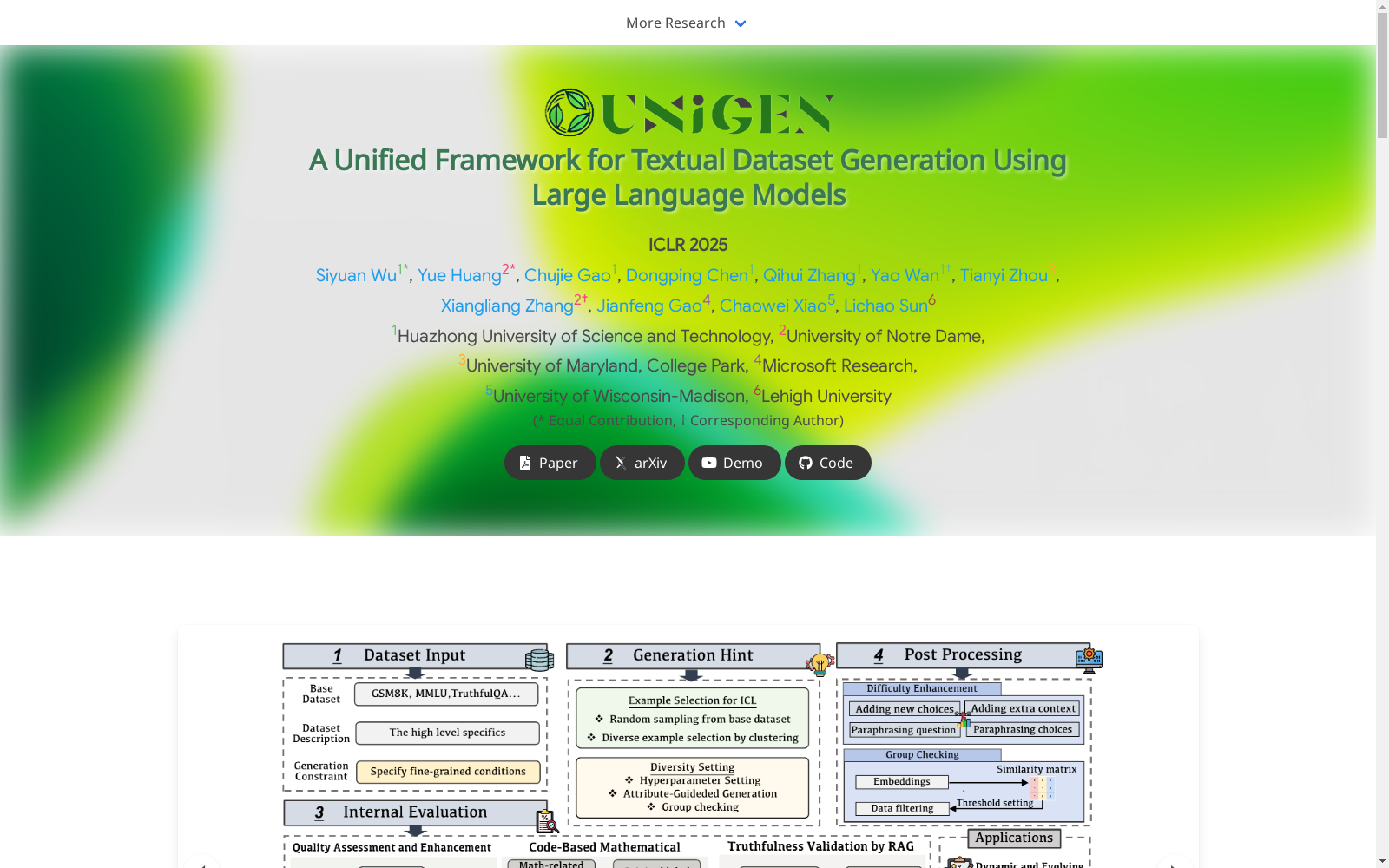
构建方式
UNIGEN 数据集的构建方法是通过一个统一的框架,利用大型语言模型(LLM)来生成文本数据集。该框架包括四个模块:框架输入、生成提示、内部评估和后处理。首先,框架输入模块捕获目标数据集的基本信息(如数据示例、数据集描述)以及用户指定的生成约束。生成提示模块旨在引导 LLM 的生成过程,确保生成的数据集与原始数据集相似并符合用户规范。内部评估模块评估和改进生成的数据集,包括对生成数据项的真实性进行评估。后处理模块对生成的数据集进行额外操作,以适应不同的应用需求。UNIGEN 通过迭代采样和转换原始数据集的子集来生成数据,并在每次迭代中应用基于数据集描述和用户约束的转换。
特点
UNIGEN 数据集的特点包括:1)通用性和可控性:UNIGEN 可以接受各种类型的文本数据集,并通过创新机制增强生成过程。2)多样性:UNIGEN 通过属性引导生成模块和组检查功能来增强数据多样性。3)真实性:UNIGEN 使用基于代码的数学评估对标签进行验证,并采用检索增强生成技术对事实性进行验证。4)用户自定义约束:UNIGEN 允许用户指定约束,从而可以根据特定需求定制数据生成过程。5)高效率:UNIGEN 通过使用 LLM 的生成能力,可以快速生成高质量的数据集,从而降低对昂贵的人工数据集的依赖。
使用方法
使用 UNIGEN 数据集的方法包括:1)数据集生成:将原始数据集、数据集描述和用户约束输入 UNIGEN 框架,通过迭代采样和转换生成新的数据集。2)基准测试 LLM:使用 UNIGEN 生成的新数据集对 LLM 进行基准测试,以评估其性能和鲁棒性。3)数据增强:使用 UNIGEN 生成的新数据集对 LLM 进行数据增强,以提高其能力和泛化能力。4)动态评估:利用 UNIGEN 的动态生成能力,可以定期更新数据集,以适应不断变化的评估需求。5)模型自校准:使用 UNIGEN 生成的新数据集对 LLM 进行自校准,以提高其准确性和可靠性。
背景与挑战
背景概述
UNIGEN 数据集是在大型语言模型 (LLM) 如 GPT-4 和 Llama3 等模型的基础上提出的。这些模型通过生成高质量的人工合成数据,极大地影响了各个领域,并减少了对外部昂贵数据集的依赖。为了解决现有生成框架中普遍存在的泛化、可控性、多样性和真实性等方面的挑战,UNIGEN 数据集应运而生。该数据集由华中科技大学、圣母大学、马里兰大学、微软研究院、威斯康星大学麦迪逊分校和莱斯特大学的研究人员共同创建。UNIGEN 数据集的核心研究问题是构建一个能够生成多样化、准确且高度可控的数据集的统一框架。UNIGEN 数据集对相关领域的影响力在于,它通过创新的机制提高了生成过程的质量,并为文本数据集的生成提供了一个全面的解决方案。
当前挑战
UNIGEN 数据集在解决领域问题的挑战方面,主要面临以下挑战:1) 泛化和可控性:现有的生成框架大多基于固定的原则直接修改原始数据集中的数据项,这可能会限制生成数据的泛化能力,因为它们没有修改数据项本身的性质,如项目内的场景。此外,许多框架也局限于特定的数据集格式或类型,例如多选题或数学导向的数据集。2) 多样性和真实性:LLM 生成数据时可能会产生幻觉,导致数据不准确,从而降低模型的性能。此外,LLM 生成数据时也可能会出现重复和低多样性,因为当面对语义相似的输入时,LLM 可能会输出相同的答案。构建过程中所遇到的挑战包括:如何有效地利用 LLM 的生成能力来创建高质量的数据集,同时确保数据的真实性和多样性。此外,如何将用户指定的约束条件整合到数据生成过程中,以实现定制化的数据生成,也是一个重要的挑战。
常用场景
经典使用场景
UNIGEN数据集是一个基于大型语言模型(LLMs)的文本数据集生成框架,其最经典的使用场景包括数据增强和动态基准测试。在数据增强方面,UNIGEN能够通过生成高质量的合成数据来扩充现有数据集,从而提高模型的泛化能力和鲁棒性。在动态基准测试方面,UNIGEN可以根据不同的评估需求生成多样化的测试数据,帮助研究人员更全面地评估LLMs的性能。
衍生相关工作
UNIGEN数据集的提出对文本数据集生成领域产生了重要的影响,并衍生了许多相关的工作。例如,一些研究尝试将UNIGEN的框架应用于其他模态数据的生成,如图像和视频。此外,一些研究还尝试将UNIGEN的框架与其他机器学习技术相结合,以进一步提高数据生成的质量和效率。
数据集最近研究
最新研究方向
UNIGEN框架作为文本数据集生成领域的最新研究方向,通过利用大型语言模型(LLMs)的能力,旨在解决现有生成框架中泛化、可控性、多样性和真实性等方面的挑战。UNIGEN框架接受各种类型的文本数据集,并通过创新的机制增强生成过程。为了增强数据多样性,UNIGEN集成了属性引导生成模块和组检查功能。为了确保准确性,它采用了基于代码的数学评估来验证标签,并采用检索增强生成技术来验证事实的真实性。框架还允许用户指定约束,从而能够根据特定需求定制数据生成过程。广泛的研究表明,UNIGEN生成的数据质量优于现有框架,并且UNIGEN框架中的每个模块都在这一提升中发挥着重要作用。此外,UNIGEN在两个实际场景中得到应用:LLMs的基准测试和数据增强。结果表明,UNIGEN有效地支持动态和不断发展的基准测试,并且数据增强提高了LLMs在各种领域的能力,包括面向代理的能力和推理技能。
相关研究论文
- 1UniGen: A Unified Framework for Textual Dataset Generation Using Large Language Models华中科技大学, 圣母大学, 马里兰大学学院市分校, 微软研究院, 威斯康星大学麦迪逊分校, 理海大学 · 2024年
以上内容由遇见数据集搜集并总结生成


