execcomp-ai-sample
收藏数据集概述
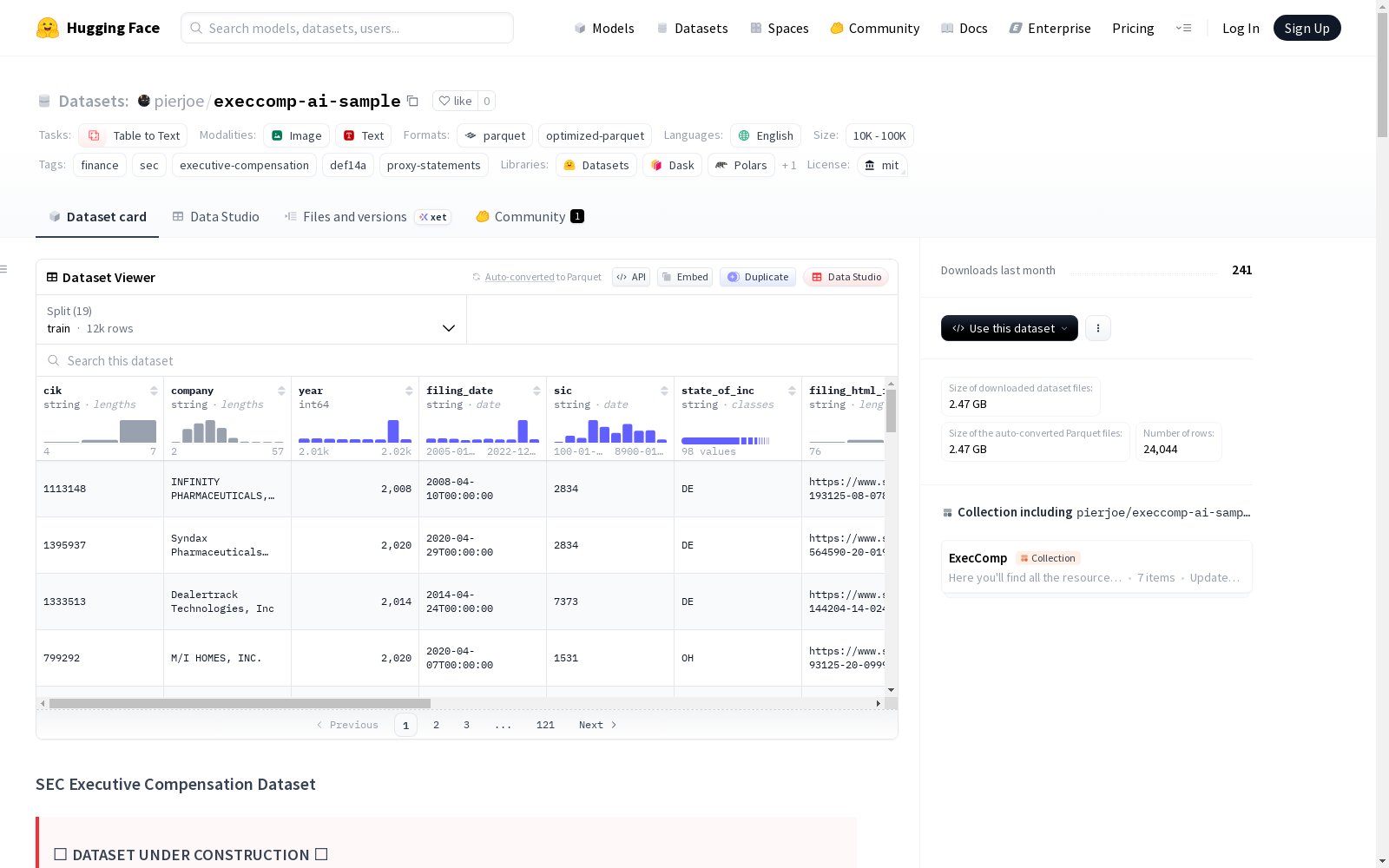
基本信息
- 数据集名称: SEC Executive Compensation Dataset
- 数据集地址: https://huggingface.co/datasets/pierjoe/execcomp-ai-sample
- 许可证: MIT License
- 主要语言: 英语 (en)
- 任务类别: 表格到文本 (table-to-text)
- 数据规模: 10K<n<100K
- 标签: 金融 (finance)、美国证券交易委员会 (sec)、高管薪酬 (executive-compensation)、DEF 14A、委托声明书 (proxy-statements)
数据集状态
- 当前状态: 正在积极开发和扩展中。
- 当前版本记录数: 约 12,000 条记录。
- 目标规模: 超过 100,000 份 SEC 文件 (2005-2022)。
- 使用警告: 数据可能包含错误或不一致之处;模式和字段可能会更改;记录将定期添加;统计信息将随处理过程更新;仅限研究用途,风险自负。
数据内容与来源
- 数据描述: 包含从美国证券交易委员会 (SEC) DEF 14A 委托声明书中提取的结构化高管薪酬数据。
- 具体内容: 摘要薪酬表 (Summary Compensation Tables),包含原始表格图像、HTML 表格结构、包含高管薪酬详细信息的结构化 JSON 以及来自微调二元分类器的 SCT 概率分数。
- 数据来源: 从 SEC EDGAR (https://www.sec.gov/edgar) 提取的 DEF 14A 文件。
数据集特征 (Features)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
cik |
string | SEC 中央索引密钥 |
company |
string | 公司名称 |
year |
int64 | 申报年份 |
filing_date |
string | SEC 申报日期 |
sic |
string | 标准行业分类代码 |
state_of_inc |
string | 注册所在州 |
filing_html_index |
string | SEC 申报文件链接 |
accession_number |
string | SEC 登记号 |
table_image |
image | 提取的表格图像 |
table_body |
string | HTML 表格内容 |
executives |
string | 高管薪酬的 JSON 数组 |
sct_probability |
float64 | 该表为真实 SCT 的概率 (0-1,来自微调分类器) |
高管数据模式 (Executive Schema)
json { "name": "John Smith", "title": "CEO", "fiscal_year": 2023, "salary": 500000, "bonus": 100000, "stock_awards": 2000000, "option_awards": 500000, "non_equity_incentive": 300000, "change_in_pension": 50000, "other_compensation": 25000, "total": 3475000 }
数据划分 (Splits)
| 划分名称 | 记录数量 | 描述 |
|---|---|---|
train |
12,022 | 所有记录的合并 |
year_2005 |
468 | 按申报年份筛选的记录 |
year_2006 |
492 | 按申报年份筛选的记录 |
year_2007 |
512 | 按申报年份筛选的记录 |
year_2008 |
486 | 按申报年份筛选的记录 |
year_2009 |
472 | 按申报年份筛选的记录 |
year_2010 |
429 | 按申报年份筛选的记录 |
year_2011 |
434 | 按申报年份筛选的记录 |
year_2012 |
391 | 按申报年份筛选的记录 |
year_2013 |
384 | 按申报年份筛选的记录 |
year_2014 |
430 | 按申报年份筛选的记录 |
year_2015 |
434 | 按申报年份筛选的记录 |
year_2016 |
357 | 按申报年份筛选的记录 |
year_2017 |
369 | 按申报年份筛选的记录 |
year_2018 |
374 | 按申报年份筛选的记录 |
year_2019 |
344 | 按申报年份筛选的记录 |
year_2020 |
4,867 | 按申报年份筛选的记录 |
year_2021 |
393 | 按申报年份筛选的记录 |
year_2022 |
386 | 按申报年份筛选的记录 |
使用建议
- SCT 概率过滤: 建议使用
sct_probability >= 0.7进行过滤,以获得高置信度的 SCT 记录,减少误报(如董事薪酬表)和重复项的影响。
方法论
数据使用以下工具从 SEC EDGAR DEF 14A 文件中提取:
- 表格提取: 使用 MinerU 进行基于 VLM 的 PDF 表格提取。
- 分类与提取: 使用 Qwen3-VL-32B 进行分类和数据提取。
处理流程
- 从 SEC EDGAR 下载 DEF 14A PDF 文件。
- 使用 MinerU 提取表格。
- 对表格进行分类以识别摘要薪酬表。
- 合并跨页分割的表格。
- 使用 VLM 提取结构化薪酬数据。
引用
如果研究中使用此数据集,请引用: bibtex @dataset{execcomp_ai_2026, author = {Di Pasquale, Pier Paolo}, title = {SEC Executive Compensation Dataset}, year = {2026}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/pierjoe/execcomp-ai-sample}, note = {AI-extracted executive compensation data from SEC DEF 14A filings (2005-2022)} }
或文本格式:
Di Pasquale, P. P. (2026). SEC Executive Compensation Dataset. Hugging Face. https://huggingface.co/datasets/pierjoe/execcomp-ai-sample
相关链接
- GitHub 项目: https://github.com/pierpierpy/Execcomp-AI
- SEC EDGAR: https://www.sec.gov/edgar