fransis3/NorNENARC
收藏Hugging Face2026-04-24 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/fransis3/NorNENARC
下载链接
链接失效反馈官方服务:
资源简介:
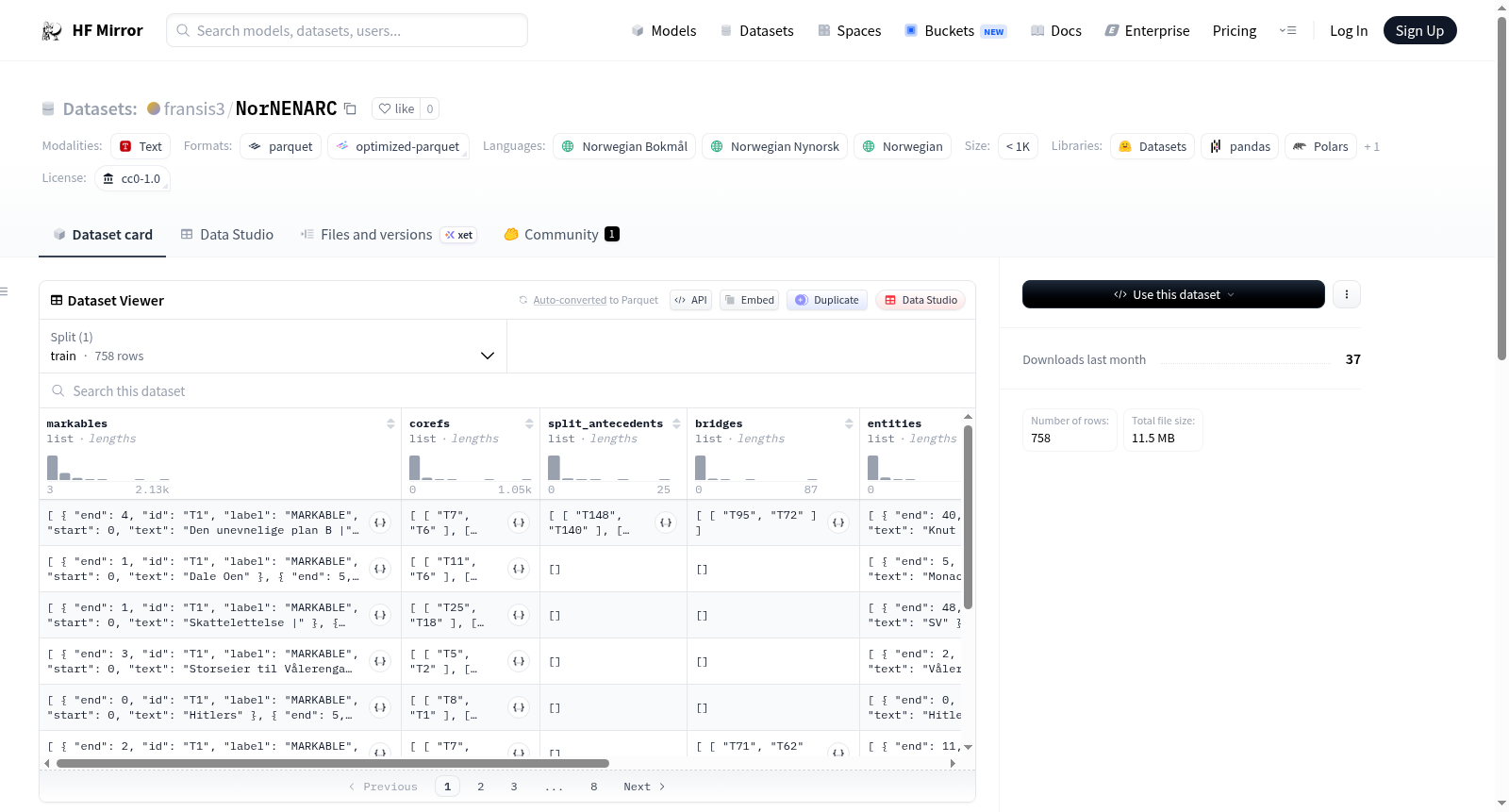
NorNENARC是一个挪威语指代消解数据集,结合了NARC的指代关系和NorNE的命名实体标注,两者都基于挪威依存树库(NDT)。数据集包含原始文本、语言标记(Bokmål或Nynorsk)、可标记项、指代关系、分裂先行词、桥接关系和实体等字段。
NorNENARC is a Norwegian coreference resolution dataset enriched with named entity annotations. It combines anaphoric relations from NARC with named entity labels from NorNE, both built on top of the Norwegian Dependency Treebank (NDT). The dataset includes raw text, language tags (Bokmål or Nynorsk), markables, corefs, split_antecedents, bridges, and entities.
提供机构:
fransis3
搜集汇总
数据集介绍
构建方式
NorNENARC数据集是挪威语指代消解领域的一项创新性资源,它巧妙地将挪威语指代消解语料库(NARC)中的回指关系与NorNE中的命名实体标注进行融合,构建于挪威语依存树库(NDT)之上。数据集的构建过程首先从NDT中提取原始文本,随后整合NARC提供的回指链和分词标注,再叠加NorNE的命名实体标签,最终形成包含文本、语言变体标识、可标记单元、核心指代链、拆分先行语、桥接关系及实体标注的多层次结构,所有数据均以统一的格式存储。
特点
该数据集的核心特色在于其双重标注体系,同时具备指代消解与命名实体识别的能力。它覆盖了挪威语的两种官方书面形式——书面挪威语(Bokmål)和新挪威语(Nynorsk),并通过'lan'字段明确区分。数据集的标注粒度极为精细,不仅记录了实体的起止位置和文本内容,还标注了实体类型,同时完整保留了核心指代、拆分先行语和桥接关系等复杂语言现象,为深入研究挪威语的语篇连贯性提供了丰富素材。
使用方法
使用NorNENARC数据集时,可直接从HuggingFace加载默认配置的训练集,其中包含758个经过精心标注的样本。每个样本以字典形式呈现,包含七个关键字段:'text'字段提供原始文本,'markables'存储可标记单元的起止位置和类型,'corefs'记录核心指代链,'split_antecedents'和'bridges'分别处理拆分先行语和桥接关系,'entities'则包含命名实体标注。研究者可根据任务需求提取相应字段,例如使用'corefs'进行指代消解模型训练,或利用'entities'开展命名实体识别任务。
背景与挑战
背景概述
NorNENARC是由挪威奥斯陆大学语言技术组(LTG)于2022年创建的一个挪威语指代消解语料库,其核心研究问题在于融合命名实体识别与指代消解两大自然语言处理任务,以提升对复杂跨句指代关系的理解能力。该数据集以挪威语依存树库(NDT)为基础,整合了NARC中的照应关系与NorNE的命名实体标签,为低资源语言——挪威语(包括书面语Bokmål和新挪威语Nynorsk)提供了首个同时精细标注实体类型与指代链的标准资源。其在斯堪的纳维亚自然语言处理领域具有里程碑意义,不仅推动了指代消解模型的训练与评估,也为跨语言迁移学习研究提供了独特的双语变体数据支撑。
当前挑战
NorNENARC所解决的领域根本挑战在于挪威语资源稀缺背景下,传统指代消解模型难以有效捕获实体与指代间语义关联的复杂性,尤其在处理嵌套名词短语、零代词以及跨语言变体(Bokmål与Nynorsk)的句法差异时表现脆弱。构建过程中面临的挑战则包括:如何精确对齐两个独立标注体系(NARC与NorNE)的标注粒度,消除标签冲突与边界分歧;第三方案例文本的版权限制迫使数据在CC-0协议下附带不可再发布条款,限制了公开使用场景;此外,仅包含758个训练样本的小规模容量,使得模型泛化能力与噪声鲁棒性成为后续研究的瓶颈。
常用场景
经典使用场景
在自然语言处理领域,指代消解与命名实体识别是两项至关重要的基础任务,尤其是在形态丰富且存在并列官方语言变体的挪威语中,其复杂性更为显著。NorNENARC数据集应运而生,它巧妙地将挪威语指代消解语料库NARC与命名实体标注资源NorNE融为一体,构建了一个涵盖书面挪威语(Bokmål)和新挪威语(Nynorsk)的综合性语料库。该数据集最经典的使用场景在于为多语言及低资源语言的共指解析模型提供高质量的监督训练数据,研究者可依赖其精细标注的指代链、实体边界及语义标签,系统性地提升模型在处理复杂句法关系与实体类型识别时的鲁棒性与准确性。
实际应用
在实际应用中,NorNENARC展现出了广泛的价值,尤其在人机交互与信息抽取系统中扮演关键角色。例如,在挪威语智能问答系统里,该数据集训练出的模型能够准确追踪用户连续对话中的实体指代,避免因代词歧义导致的回答偏差;在新闻摘要生成场景下,模型可借助其标注的共指链与实体信息,自动识别并聚合涉及同一人物或组织的零散表述,从而生成逻辑连贯的凝练文本。此外,在法律文档审核与医疗病历分析等垂直领域,NorNENARC也助力于构建具备语篇理解能力的自动化系统,显著提升信息检索与实体关系抽取的效率与可靠性。
衍生相关工作
基于NorNENARC数据集,学术界已衍生出一系列具有启发性的经典工作。一方面,研究者以此为基础,借鉴其融合双源标注的设计理念,尝试构建类似的多任务语料库用于其他斯堪的纳维亚语言,如瑞典语与丹麦语的指代消解研究。另一方面,该数据集直接催生了针对挪威语神经共指解析模型的专项优化,其中不乏对比不同编码器结构(如基于BERT的变体与序列标注模型)在其上的性能评估工作。更有学者利用NorNENARC探索指代消解与命名实体识别联合训练的协同学习框架,验证了多任务学习在语篇理解中的增益效果,这些衍生研究共同构成了挪威语自然语言处理领域的一个坚固支点。
以上内容由遇见数据集搜集并总结生成


