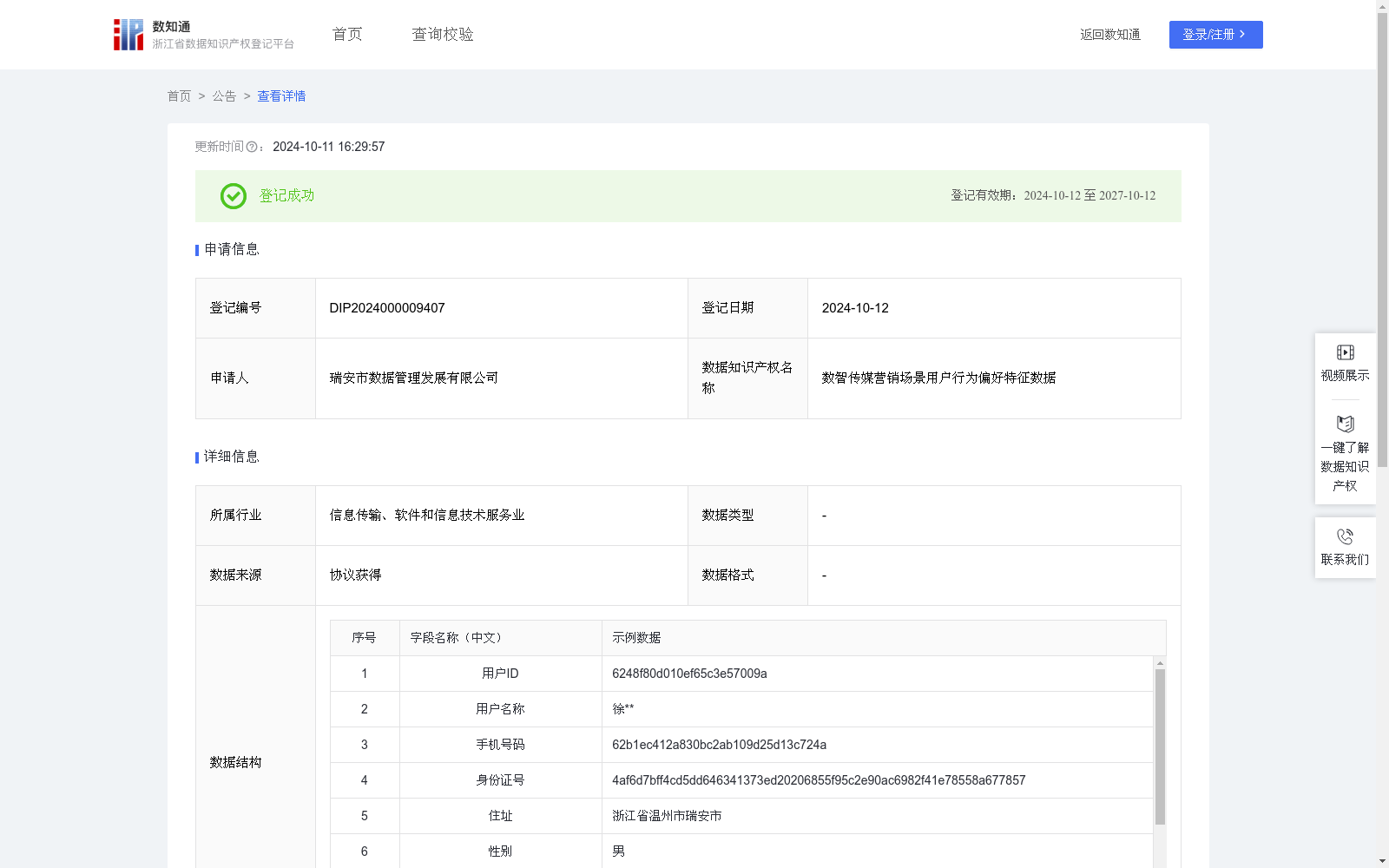
数智传媒营销场景用户行为偏好特征数据
收藏浙江省数据知识产权登记平台2024-10-11 更新2024-10-12 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/69815
下载链接
链接失效反馈官方服务:
资源简介:
(1)数据适用范围:浙江省温州市瑞安市
(2)数据内容:对浙江省温州市瑞安市,所有使用“天地瑞安”的用户阅读习惯、活动参与、音视频浏览、搜索查询等形成人群行为标签,形成用户行为画像,并结合用户行为标签和稿件标签进行精准推送,提升瑞安市各类传媒推广触达效率,提升用户黏性和稿件阅读量。
(3)数据应用场景:通过传媒稿件结合AI大数据分析,形成稿件属性标签,进行数据清洗去重,形成标签库。结合“天地瑞安”软件用户点击各类稿件的频率,浏览习惯,形成用户行为标签。提高内容个性化匹配度:通过为稿件和用户分别贴上标签,“天地瑞安”软件能够更精确地识别和匹配用户的兴趣点和内容特征;提升采编工作效率:利用标签分析报告,采编人员可以快速识别和筛选出与特定用户群体兴趣相匹配的稿件,从而提高选稿和编辑的效率;增加板块流量和互动:通过精准推送,各个板块能够吸引更多目标用户群体,增加页面的PV和UV;优化广告投放效果:精准的标签匹配推送策略使得广告投放更加针对性,提高了广告的点击率和转化率;通过对用户标签和行为数据的分析,“天地瑞安”软件可以洞察用户需求和市场趋势,指导内容创作和创新。在自研的融媒综合管理平台上,通过机器学习分析稿件、音视频和用户行为数据,进行标签建模,同时允许撰稿人手动添加查看标签的PV、UV数据。
1.数据清洗和标签库建立:每周更新标签库,融合撰稿人、机器学习模型的标签,与现有库对比,添加新标签。在主数据表中为用户ID增加新标签和初始标签权重,构建标签层级结构。同时清理标签权重低于1,归档至不活跃库。
2.用户标签匹配:通过分析用户行为并结合用户ID,按时间排序阅读行为,结合埋点数据,为用户分配并更新标签权重。
3.标签数据使用:撰稿人上传稿件后,机器学习模型自动生成标签名称,撰稿人可调整。发布时,系统根据用户行为和标签权重精准推送,优先末级标签权重,否则上级标签权重排序。
模型选择:依据文章内容和用户行为特征,利用NLP技术处理文本,形成基础标签名称,选择合适的机器学习模型进行训练。如分类模型(逻辑回归、决策树、随机森林等)或聚类模型(K-means、层次聚类等)。
模型训练与评估:利用历史数据训练模型,提高模型生成标签名称和分配标签权重的精确度。
生成兴趣偏好标签:根据用户阅读时间、埋点和阅读习惯,生成并调整用户行为的标签名称和标签权重
1. Data Application Scope: Ruian City, Wenzhou City, Zhejiang Province
2. Data Content: For all users of "Tiandi Ruian" in Ruian City, Wenzhou City, Zhejiang Province, collect their reading habits, event participation, audio-visual browsing, search queries and other behavioral data to establish crowd behavior tags and user behavior profiles. Combine user behavior tags and manuscript tags for precise targeted delivery, so as to improve the reach efficiency of various media promotions in Ruian, enhance user stickiness and manuscript reading volume.
3. Data Application Scenarios:
a. Combine media manuscripts with AI big data analysis to generate manuscript attribute tags, conduct data cleaning and deduplication to build a tag library. Combine the click frequency and browsing habits of "Tiandi Ruian" software users to form user behavior tags.
b. Improve content personalization matching: By tagging both manuscripts and users, "Tiandi Ruian" can more accurately identify and match user interests and content characteristics.
c. Improve editorial work efficiency: Using tag analysis reports, editorial staff can quickly identify and screen manuscripts matching the interests of specific user groups, thereby improving the efficiency of manuscript selection and editing.
d. Increase section traffic and interaction: Through precise targeted delivery, each section can attract more target user groups, increasing the page's PV and UV.
e. Optimize advertising delivery effectiveness: Precise tag matching and push strategies make advertising delivery more targeted, improving advertising click-through rate (CTR) and conversion rate (CVR).
f. Through analysis of user tags and behavioral data, "Tiandi Ruian" can gain insights into user needs and market trends, guiding content creation and innovation.
On the self-developed integrated media management platform, machine learning is used to analyze manuscripts, audio-visual and user behavior data for tag modeling, and contributors are allowed to manually add and view the PV and UV data of tags.
1. Data Cleaning and Tag Library Establishment: Update the tag library on a weekly basis, integrate tags from contributors and machine learning models, compare with the existing library, and add new tags. Add new tags and initial tag weights to the user ID in the main data table, and construct a tag hierarchy. Meanwhile, clean up tags with a weight lower than 1 and archive them to the inactive tag library.
2. User Tag Matching: Analyze user behaviors and combine with user IDs, sort reading behaviors chronologically, and combine with buried-point data to assign and update tag weights for users.
3. Tag Data Usage: After contributors upload manuscripts, the machine learning model automatically generates tag names, which can be adjusted by contributors. During publishing, the system conducts precise targeted delivery based on user behaviors and tag weights, prioritizing the weights of lower-level tags; if no lower-level tags are available, sort by the weights of higher-level tags.
Model Selection: Based on article content and user behavior characteristics, use NLP technology to process text and generate basic tag names, and select appropriate machine learning models for training, such as classification models (logistic regression, decision tree, random forest, etc.) or clustering models (K-means, hierarchical clustering, etc.).
Model Training and Evaluation: Use historical data to train the model, so as to improve the accuracy of the model in generating tag names and assigning tag weights.
Generate Interest Preference Tags: Generate and adjust the tag names and tag weights of user behaviors based on users' reading time, buried-point data and reading habits.
提供机构:
瑞安市数据管理发展有限公司
创建时间:
2024-09-19
搜集汇总
数据集介绍
特点
该数据集包含613条用户行为偏好特征数据,每周更新,主要用于分析用户行为和稿件标签,实现精准推送,提升传媒推广效果。数据字段包括用户ID、名称、手机号码、身份证号、住址、性别、出生年份、标签ID、标签名称和标签权重等。
以上内容由遇见数据集搜集并总结生成


