suno-audio
收藏Hugging Face2026-01-19 更新2026-01-20 收录
下载链接:
https://huggingface.co/datasets/humair025/suno-audio
下载链接
链接失效反馈官方服务:
资源简介:
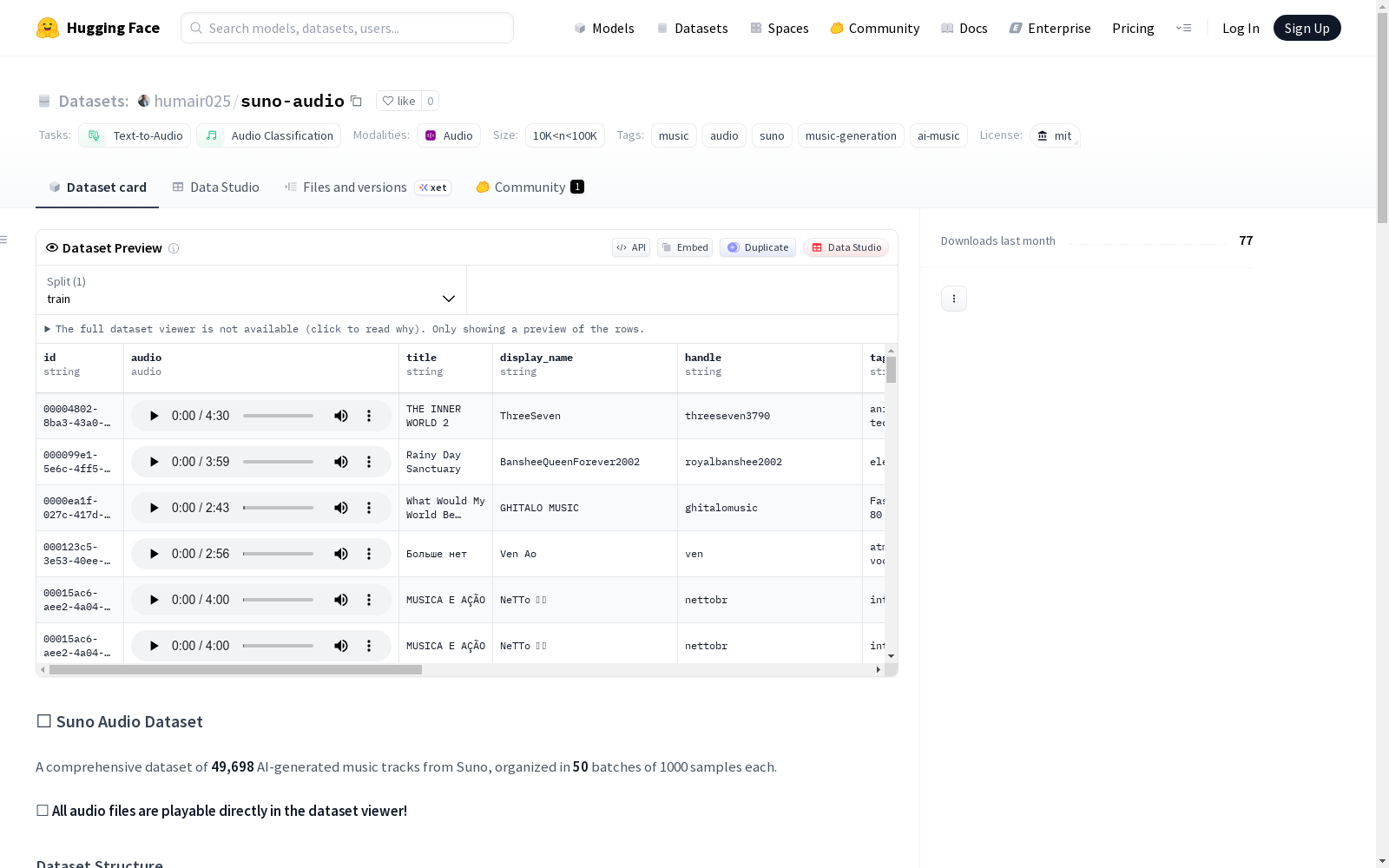
Suno音频数据集是一个包含49,698首AI生成音乐曲目的综合数据集,来自Suno平台。数据集按50个批次组织,每个批次包含最多1000个音频样本及其元数据。音频文件为MP3格式,可直接在数据集查看器中播放。元数据包括歌曲标题、创作者信息、标签、生成提示、播放次数、点赞数等。
The Suno Audio Dataset is a comprehensive dataset containing 49,698 AI-generated music tracks sourced from the Suno platform. The dataset is organized into 50 batches, with each batch holding up to 1,000 audio samples and their corresponding metadata. The audio files are in MP3 format and can be played directly in the dataset viewer. The metadata includes song titles, creator information, tags, generation prompts, play counts, like counts, and other relevant details.
创建时间:
2026-01-17
原始信息汇总
Suno Audio Dataset 数据集概述
数据集基本信息
- 数据集名称:Suno Audio Dataset
- 数据集标识:humair025/suno-audio
- 许可协议:MIT License
- 主要任务类别:文本到音频、音频分类
- 标签:音乐、音频、suno、音乐生成、AI音乐
- 数据规模:10K < n < 100K
数据集内容与规模
- 总音轨数:49,698
- 批次数量:50
- 批次大小:每批次最多1000个音频样本
- 数据格式:Apache Arrow,内嵌MP3音频
- 音频格式:MP3
数据结构与字段
数据集按批次(batch_0、batch_1等)组织,每个批次包含音频样本及其元数据。
字段说明:
audio:可播放的MP3音频文件id:唯一音轨标识符title:歌曲标题display_name:创作者/艺术家姓名handle:创作者句柄tags:音乐标签、流派和风格prompt:用于生成的文本提示duration:音轨时长(秒)play_count:在Suno上的播放次数upvote_count:社区点赞数model_name:使用的Suno模型版本created_at:创建时间戳status:音轨状态is_public:公开可见性标志
使用方式
加载数据集
python from datasets import load_dataset dataset = load_dataset("Humair332/suno-audio")
加载特定批次
python dataset = load_dataset("Humair332/suno-audio", data_dir="batch_0")
播放音频
python audio_data = dataset[train][0][audio] from IPython.display import Audio Audio(audio_data[array], rate=audio_data[sampling_rate])
按标签过滤
python rock_songs = dataset[train].filter(lambda x: rock in x[tags].lower())
最受欢迎音轨
python from datasets import Dataset df = dataset[train].to_pandas() top_tracks = df.nlargest(10, play_count)[[title, display_name, play_count]]
数据来源
- 原始数据集:https://huggingface.co/datasets/nyuuzyou/suno
引用信息
bibtex @dataset{suno_audio_dataset, title={Suno Audio Dataset}, author={Humair332}, year={2026}, publisher={Hugging Face}, url={https://huggingface.co/datasets/Humair332/suno-audio} }
搜集汇总
数据集介绍
构建方式
在人工智能音乐生成领域,Suno Audio Dataset的构建体现了系统化数据采集与组织的方法。该数据集通过整合Suno平台生成的音乐作品,将49,698首曲目划分为50个批次,每个批次包含约1000个样本。构建过程中,每首曲目均以MP3音频格式存储,并附有丰富的元数据,包括曲目标题、创作者信息、生成提示文本、标签分类以及用户互动指标等。这种批处理结构不仅便于数据管理,还支持按需加载,为大规模音乐分析提供了灵活的数据访问方式。
特点
该数据集的核心特点在于其全面覆盖了AI生成音乐的多样性,并提供了可直接播放的音频文件与详尽的元数据。音频文件以MP3格式嵌入,用户可在数据集查看器中直接点击播放,实现了无缝的听觉体验。元数据字段涵盖从基础标识符到社区互动指标的多个维度,如播放次数、点赞数量及生成模型版本,为研究音乐生成质量、用户偏好及算法演进提供了多维度的分析基础。此外,数据集采用Apache Arrow格式组织,确保了高效的数据处理与查询性能。
使用方法
使用该数据集时,研究人员可通过Hugging Face的datasets库灵活加载全部或特定批次的数据。加载后,音频数据可直接转换为数组格式,结合IPython.display.Audio在Jupyter或Colab环境中实时播放。数据集支持基于标签的过滤操作,例如筛选特定流派或风格的曲目,便于针对性分析。同时,利用pandas转换功能,可对元数据如播放次数进行排序与统计,以识别流行曲目或探索用户行为模式,为音乐信息检索、生成模型评估及推荐系统研究提供实用工具。
背景与挑战
背景概述
Suno Audio Dataset 是一个专注于人工智能生成音乐的综合性数据集,收录了来自 Suno 平台的 49,698 条音乐轨道。该数据集由 Humair332 于 2026 年发布,旨在为文本到音频生成及音频分类研究提供丰富资源。其核心研究问题聚焦于探索 AI 音乐生成模型的能力边界,推动音乐创作自动化与个性化发展。通过整合详细的元数据,如生成提示、标签及用户互动指标,该数据集为评估生成音乐的质量、多样性与社会接受度奠定了实证基础,对计算创意与音乐信息检索领域产生了显著影响。
当前挑战
该数据集致力于应对 AI 音乐生成领域的核心挑战,即如何生成兼具艺术性、情感表达与结构连贯性的音乐作品。具体而言,挑战包括确保生成音乐在风格多样性、旋律创新性及音频保真度方面达到专业水准,同时避免模式崩溃与内容重复。在构建过程中,数据收集面临规模与质量平衡的难题,需从海量生成结果中筛选代表性样本,并处理元数据标注的一致性。此外,嵌入音频文件与结构化存储的技术实现,以及维护数据版权合规性,亦是构建过程中的关键挑战。
常用场景
经典使用场景
在人工智能音乐生成领域,Suno Audio Dataset以其近五万条AI生成的音乐曲目,为文本到音频的转换任务提供了丰富的实验素材。研究者常利用该数据集训练和评估生成模型,探索如何将自然语言描述转化为具有特定风格、情感和结构的音乐作品。通过分析其包含的提示词、标签及音频文件,模型能够学习音乐语义与声学特征之间的复杂映射关系,进而推动可控音乐生成技术的发展。
解决学术问题
该数据集有效应对了音乐信息检索与生成研究中数据稀缺与多样性不足的挑战。它为解决文本引导的音乐合成、音乐风格迁移、自动音乐标注等经典问题提供了基准数据。其丰富的元数据,如播放量、点赞数等互动指标,为研究音乐流行度预测、用户偏好建模提供了量化依据,从而深化了对AI生成内容接受度与艺术价值评估的理解。
衍生相关工作
围绕该数据集,已衍生出一系列关于AI音乐生成与评估的经典研究工作。例如,研究者利用其进行提示工程优化、多模态音乐表示学习,以及开发基于人类反馈的强化学习训练策略。这些工作不仅提升了生成音乐的质量与可控性,也催生了新的音乐生成模型架构和客观评估指标,共同构成了当前AI音乐研究领域的重要基石。
以上内容由遇见数据集搜集并总结生成


