MusicSet
收藏Hugging Face2024-11-05 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/ManzhenWei/MusicSet
下载链接
链接失效反馈官方服务:
资源简介:
MusicSet数据集基于MTG-Jamendo数据集构建,专注于带有丰富描述文本的音乐音频。该数据集通过选择至少有5个标签的音乐音频,提取音频中间的80%并分割成10秒的片段,去除非旋律部分。这些片段被保存为单独的WAV文件,其描述信息存储在JSON文件中。文本描述通过deepseek API生成,该API学习了musiccaps数据集的文本描述风格,并将多个标签整合成完整的描述。最终的MusicSet数据集包含约150,000个10秒的音乐-文本对,结合了musicbench和musiccaps数据集的元素。
The MusicSet dataset is constructed based on the MTG-Jamendo dataset, focusing on musical audio with rich descriptive texts. It selects audio tracks with at least 5 tags, extracts the middle 80% portion of each selected track, splits the portion into 10-second segments, and removes non-melodic parts. These segments are saved as separate WAV files, and their descriptive information is stored in a JSON file. The text descriptions are generated via the DeepSeek API, which learns the descriptive text style of the MusicCaps dataset and integrates multiple tags into complete, coherent descriptions. The final MusicSet dataset contains approximately 150,000 10-second music-text pairs, incorporating elements from both the MusicBench and MusicCaps datasets.
创建时间:
2024-10-31
原始信息汇总
MusicSet 数据集
概述
MusicSet 数据集基于 MTG-Jamendo 数据集构建,通过筛选和扩展音乐音频并添加描述性文本。数据集包含约 150,000 个 10 秒的音乐-文本对。
数据处理
- 音频筛选:选择至少有 5 个标签的音乐音频。
- 音频分割:加载音频文件,提取中间 80% 的内容进行分割,生成 10 秒的片段,去除开头和结尾的非旋律部分。
- 标签扩展:通过调用 deepseek API,将多个标签扩展为完整的描述文本。
- 数据整合:将生成的音乐-文本对与 musicbench 和 musiccaps 数据集整合,形成最终的 MusicSet 数据集。
数据格式
- 音频文件:保存为单独的 WAV 文件。
- 描述信息:保存为 JSON 文件。
引用
bibtex @article{wei2024melodyneedmusicgeneration, title={Melody Is All You Need For Music Generation}, author={Shaopeng Wei and Manzhen Wei and Haoyu Wang and Yu Zhao and Gang Kou}, year={2024}, eprint={2409.20196}, archivePrefix={arXiv}, primaryClass={cs.SD}, url={https://arxiv.org/abs/2409.20196}, }
搜集汇总
数据集介绍
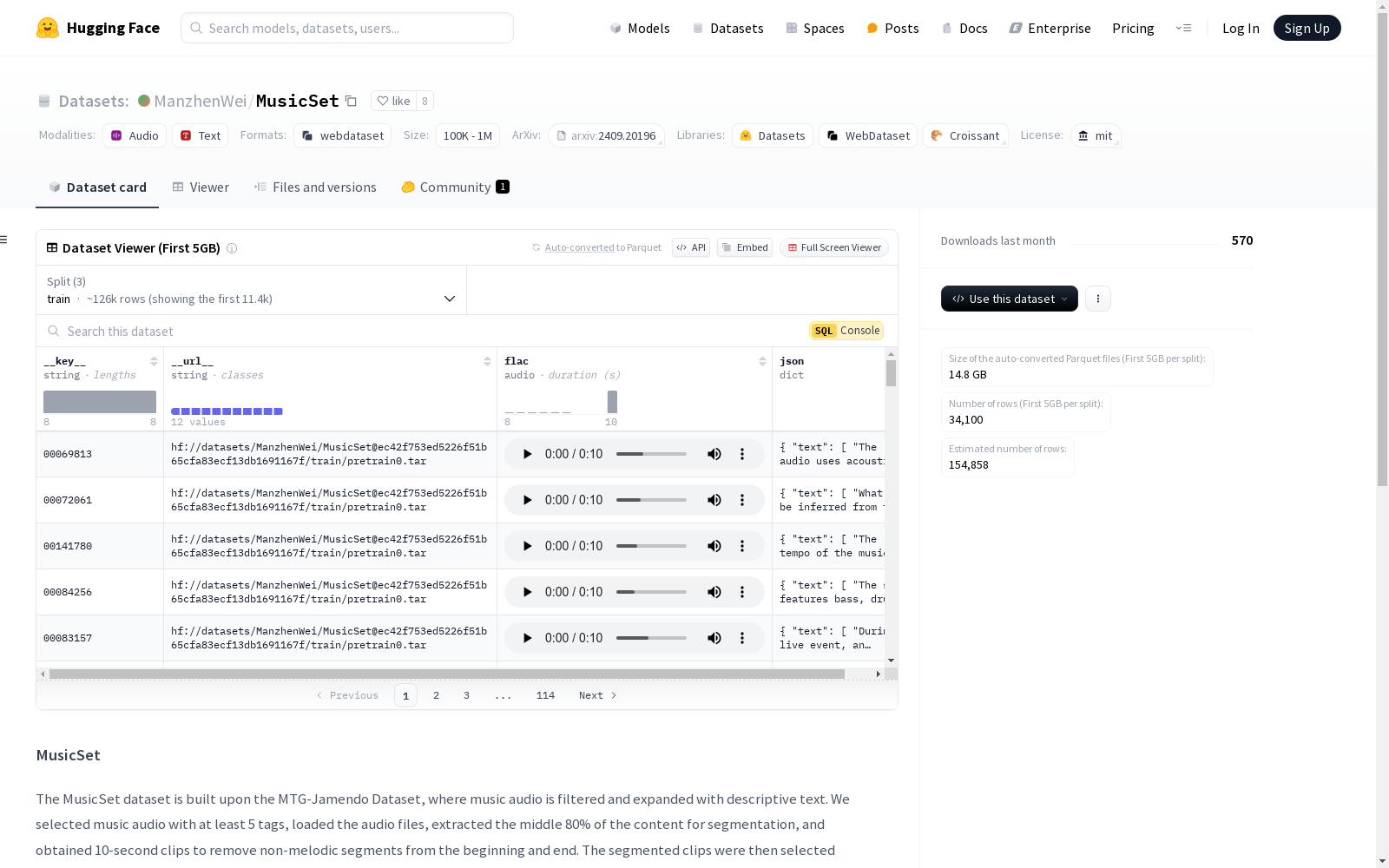
构建方式
MusicSet数据集的构建基于MTG-Jamendo数据集,通过筛选带有至少5个标签的音乐音频,加载音频文件并提取中间80%的内容进行分段,最终获得10秒的音频片段,以去除开头和结尾的非旋律部分。这些片段根据标签数量进行选择,保存为独立的WAV文件,其描述信息则保存为JSON文件。在扩展多个标签为完整描述的过程中,调用了deepseek API,模型首先学习了musiccaps数据集的文本描述风格,随后整合并重写了标签,最终生成了11万对高质量的音乐-文本对。这些对与musicbench和musiccaps数据集整合,形成了包含约15万对10秒音乐-文本对的MusicSet数据集。
特点
MusicSet数据集的特点在于其高质量的音乐-文本对,每对数据均经过精心筛选和描述扩展,确保了数据的丰富性和准确性。数据集中的音乐片段均为10秒,去除了非旋律部分,使得每段音频都具有较高的音乐代表性。此外,数据集的描述信息通过深度学习模型生成,融合了多个标签的语义,提供了更为全面和细致的音乐描述。这些特点使得MusicSet在音乐生成、音乐信息检索等领域具有广泛的应用潜力。
使用方法
MusicSet数据集的使用方法相对简便,用户可以通过加载WAV文件和对应的JSON文件,获取音乐片段及其描述信息。数据集适用于音乐生成、音乐信息检索、音乐分类等任务。用户可以利用这些数据训练深度学习模型,生成新的音乐作品或进行音乐内容的自动标注。此外,数据集还提供了与musicbench和musiccaps数据集的整合,用户可以根据需要选择使用单一数据集或整合后的数据集,以增强模型的训练效果。
背景与挑战
背景概述
MusicSet数据集是基于MTG-Jamendo数据集构建的,旨在通过音乐音频与描述性文本的结合,推动音乐生成与理解领域的研究。该数据集由Shaopeng Wei等研究人员于2024年创建,其核心研究问题在于如何通过高质量的音乐-文本对,提升音乐生成模型的性能与多样性。MusicSet通过筛选至少包含5个标签的音乐音频,提取其中间80%的内容并分割为10秒片段,最终生成了约15万对音乐-文本数据。这一数据集不仅整合了musicbench和musiccaps数据集,还通过深度学习方法扩展了文本描述,为音乐生成与文本理解提供了丰富的资源。
当前挑战
MusicSet数据集在构建过程中面临多重挑战。首先,音乐音频的筛选与分割需要确保片段具有代表性,同时避免非旋律性内容的干扰,这对音频处理技术提出了较高要求。其次,将多个标签扩展为完整的文本描述依赖于深度学习模型,模型需在理解音乐风格与情感的基础上生成高质量的文本,这对自然语言处理技术提出了挑战。此外,数据集的大规模整合与质量控制也增加了构建的复杂性,确保数据的一致性与多样性成为关键问题。这些挑战不仅反映了音乐生成领域的复杂性,也为未来研究提供了重要的改进方向。
常用场景
经典使用场景
MusicSet数据集在音乐信息检索和音乐生成领域具有广泛的应用。研究者可以利用该数据集中的音乐-文本对,训练和评估音乐描述生成模型,从而提升音乐检索系统的智能化水平。此外,该数据集还可用于音乐风格分类、情感分析等任务,为音乐理解提供丰富的数据支持。
解决学术问题
MusicSet数据集解决了音乐与文本关联性研究中的数据稀缺问题。通过提供大量高质量的音乐-文本对,该数据集为音乐描述生成、音乐语义理解等研究提供了坚实的基础。其多样化的音乐标签和详细的文本描述,有助于推动音乐信息检索和生成技术的创新,提升模型在复杂音乐场景中的表现。
衍生相关工作
MusicSet数据集的发布催生了一系列相关研究工作。例如,基于该数据集的音乐生成模型在生成音乐的多样性和质量上取得了显著进展。此外,研究者还利用该数据集开发了新的音乐描述生成算法,进一步提升了音乐与文本之间的关联性。这些工作不仅推动了音乐生成技术的发展,也为音乐信息检索领域提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


