openkg/MHaluBench
收藏Hugging Face2024-06-12 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/openkg/MHaluBench
下载链接
链接失效反馈官方服务:
资源简介:
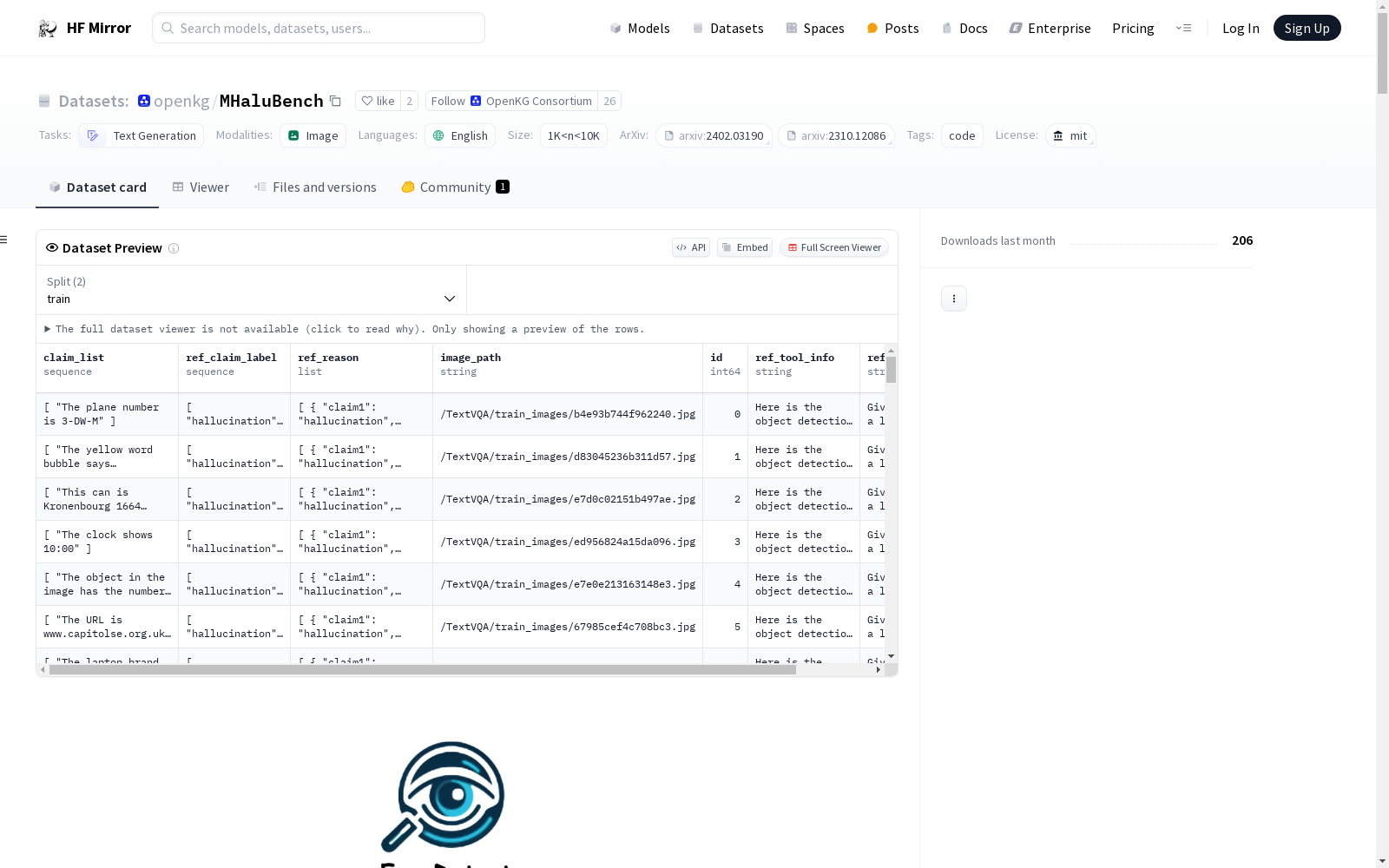
MHaluBench是一个用于评估多模态幻觉检测器的基准数据集,涵盖了图像到文本和文本到图像生成的内容。该数据集旨在严格评估多模态幻觉检测器的进展,并提供了详细的统计数据,包括幻觉类别分布和声明级别的数据统计。
MHaluBench是一个用于评估多模态幻觉检测器的基准数据集,涵盖了图像到文本和文本到图像生成的内容。该数据集旨在严格评估多模态幻觉检测器的进展,并提供了详细的统计数据,包括幻觉类别分布和声明级别的数据统计。
提供机构:
openkg
原始信息汇总
数据集概述
基本信息
- 许可证: MIT
- 任务类别: 文本生成
- 语言: 英语
- 标签: 代码
- 美观名称: MHaluBench
- 大小类别: 1K<n<10K
配置详情
- 配置名称: default
- 数据文件:
- 分割: train
- 路径: MHaluBench_train.json
- 分割: val
- 路径: MHaluBench_val-v0.1.json
- 分割: train
- 数据文件:
数据集统计
- 数据集: MHaluBench
- 内容: 包含图像到文本和文本到图像生成的内容,旨在严格评估多模态幻觉检测器的进展。
- 详细统计: 请参见下图。
框架说明
- 框架: UniHD
- 目标: 针对图像到文本和文本到图像任务,系统地处理多模态幻觉识别。
- 具体说明: 请参见下图。
版本信息
- 验证集版本:
- v0.1: 用于UniHD论文的数据。
- v0.2: 修改了图像6dfc3ab66883fd8c.jpg和图像COCO_val2014_000000009727.jpg中的第五个声明标签。
引用
- 请引用我们的仓库,如果您在工作中使用了EasyDetect。
搜集汇总
数据集介绍
构建方式
MHaluBench数据集的构建基于对多模态大语言模型(MLLMs)中幻觉现象的系统性研究。该数据集涵盖了图像到文本和文本到图像生成任务中的幻觉检测,旨在通过严格的评估来推动多模态幻觉检测技术的发展。数据集的构建过程中,研究人员对不同模态间的冲突幻觉和事实冲突幻觉进行了细致的分类和标注,确保了数据集的多样性和代表性。
特点
MHaluBench数据集的特点在于其对多模态幻觉的统一检测视角,涵盖了对象、属性、场景文本等多个层次的幻觉检测。此外,数据集还提供了详细的统计信息和分类分布,帮助研究者更好地理解和利用数据。数据集的多样性和细致的标注使其成为评估和改进多模态幻觉检测模型的理想选择。
使用方法
使用MHaluBench数据集时,用户可以通过提供的配置文件快速设置参数,并利用示例代码进行快速上手。数据集支持多种任务类型,包括图像到文本和文本到图像生成任务的幻觉检测。用户可以根据需要调整配置文件中的参数,以适应不同的实验需求。数据集的详细文档和示例代码为用户提供了便捷的使用指南。
背景与挑战
背景概述
MHaluBench数据集由OpenKG团队于2023年10月启动开发,旨在为多模态大语言模型(MLLMs)中的幻觉检测提供一个系统化的评估框架。该数据集的核心研究问题集中在多模态幻觉的统一检测上,特别是针对图像到文本和文本到图像生成任务中的幻觉现象。MHaluBench的推出标志着多模态幻觉检测领域的一个重要里程碑,其研究成果发表于2024年2月的《Unified Hallucination Detection for Multimodal Large Language Models》论文中。该数据集的创建不仅为研究人员提供了一个标准化的评估工具,还为多模态大语言模型的进一步优化提供了宝贵的资源。
当前挑战
MHaluBench数据集面临的挑战主要集中在两个方面:首先,多模态幻觉的检测任务本身具有复杂性,涉及图像与文本之间的细粒度对齐问题,尤其是在对象、属性和场景文本级别的冲突检测上。其次,数据集的构建过程中,研究人员需要处理大量的多模态数据,确保每个图像-文本对的标注准确性和一致性,这对数据处理和标注工作提出了较高的要求。此外,随着多模态大语言模型的不断发展,如何持续更新和扩展MHaluBench以适应新的模型和技术也是一个重要的挑战。
常用场景
经典使用场景
MHaluBench数据集的经典使用场景主要集中在多模态大语言模型(MLLMs)的幻觉检测任务中。该数据集通过提供图像与文本对的形式,帮助研究者评估模型在图像描述生成(Image Captioning)和文本到图像生成(Text-to-Image)任务中的幻觉现象。具体而言,研究者可以利用MHaluBench对模型的输出进行细粒度的幻觉检测,识别出模型生成的文本或图像是否与输入数据或事实知识存在冲突。
实际应用
MHaluBench数据集在实际应用中具有广泛的应用场景。例如,在新闻媒体领域,该数据集可用于检测自动生成的新闻图片与文本描述是否一致,确保信息的真实性。在教育领域,它可以用于评估智能教学系统生成的视觉内容与文本解释的匹配度,提升教学效果。此外,在医疗领域,MHaluBench可用于检测医学图像与报告描述之间的幻觉现象,确保诊断的准确性。
衍生相关工作
基于MHaluBench数据集,研究者开发了多种幻觉检测模型,如HalDet-LLaVA,这些模型在HuggingFace、ModelScope和WiseModel等平台上广泛应用。此外,该数据集还启发了许多关于多模态幻觉检测的进一步研究,包括如何利用多模态证据进行更精确的幻觉识别,以及如何通过统一的框架解决不同类型的幻觉问题。这些工作不仅丰富了多模态大语言模型的研究领域,还为实际应用提供了技术支持。
以上内容由遇见数据集搜集并总结生成


