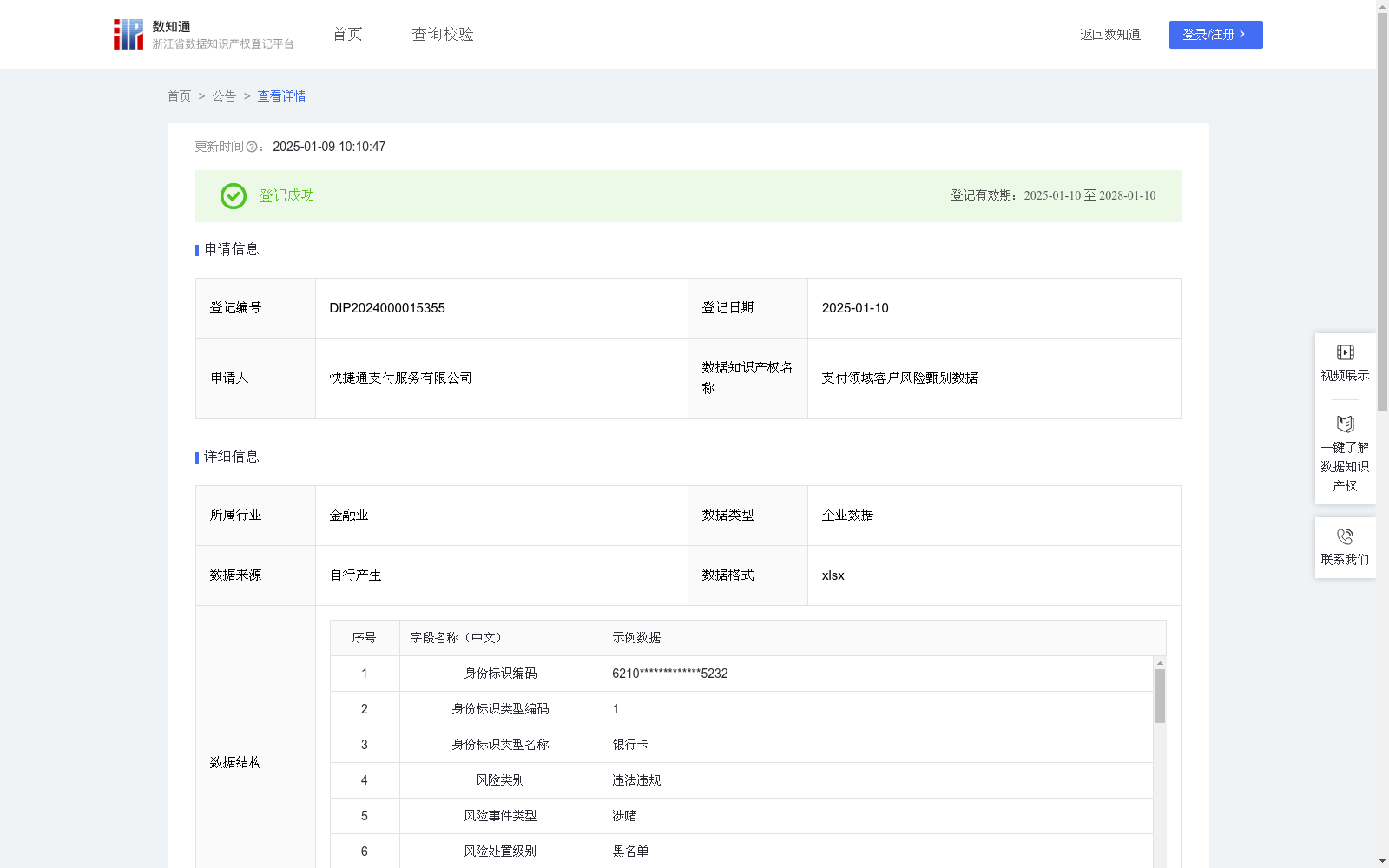
支付领域客户风险甄别数据
收藏浙江省数据知识产权登记平台2025-01-09 更新2025-01-10 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/110663
下载链接
链接失效反馈官方服务:
资源简介:
本数据集合包含特定的社会实体(自然人或企业法人)的风险评分。可应用在支付领域以及其他有合规要求、反洗钱要求、反欺诈要求的金融领域,如商户入网审核阶段、风险交易识别阶段等,可辅助评估和决策。以此减少可能涉及洗钱等非法跨境资金转移的高风险支付交易的发生,因为跨境支付易被不法分子利用,需确保每一笔支付都符合国际反洗钱法规和各国相关监管要求。同时,依据风险评分有助于准确判断支付请求是由真实用户发起还是欺诈行为,保障用户资金安全。1.数据采集:采集在第三方支付场景所接触入网客户关联实体相关信息以及对应身份标识发生的交易信息数据。
2.数据处理:对采集的交易信息数据进行统计性分析计算交易次数、夜间交易笔数、凌晨交易笔数、首次交易时间、末次交易时间、交易年数/月数/天数、交易时间跨度、凌晨交易占比、夜间交易占比等。
3.特征工程:将关联实体特征进行编码获取向量MRC_features=Encoder_en(Entity_features),其中Encoder_en为预先准备的实体特征编码器,Entity_features为关联实体特征包含关联实体类型、关联实体所在省份、生态类型、关联实体行业编码等;将交易特征分别进行分箱和编码,并组装成交易维度向量TC_features=Encoder_nbr(Trade_featuers),其中Encoder_nbr为预先准备的交易特征编码器,Trade_featuers为交易特征包含交易次数、首次/末次交易时间、夜间/凌晨交易笔数、交易年数/月数/天数、交易时间跨度、夜间/凌晨交易占比、风险金额笔数、风险金额百分比等;将MRC_features、Entity_features、TC_features等使用concat函数组合成features,结合对历史人工打标的风险类别(Label)加入,构成特征和标签矩阵data;
4.模型构建:模型为预先训练构建,由特征工程获取矩阵data,由矩阵中提取进行训练的向量集合X=data[features],提取特征矩阵中标签y=data[Label],这里的Label为风险类别的编码,并将特征向量和标签拆分为训练集合和测试集合X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=42),基于决策树模型训练model.fit(X_train,y_train),模型经过测试和生产部署,并持续调优。
5.模型输出:生产每条数据经前述处理与特征工程编码获取单条向量R_vector,通过模型获取风险处置级别R_Label=model.predict(R_vector),获取相应概率R_Rate=model.predict_proba(R_vector),计算风险评分R_Score=100*R_Rate,推送给风控专家进行最终确认。
This dataset contains risk scores for specific social entities (natural persons or corporate legal persons). It can be applied in the payment industry and other financial sectors with compliance, anti-money laundering (AML) and anti-fraud requirements, such as merchant onboarding audit and risky transaction identification stages, to assist with assessment and decision-making. This helps reduce the occurrence of high-risk payment transactions involving illegal cross-border fund transfers such as money laundering, as cross-border payments are easily exploited by criminals, and it is necessary to ensure that every payment complies with international AML regulations and relevant regulatory requirements of various countries. Meanwhile, the risk score can help accurately determine whether a payment request is initiated by a real user or a fraudulent act, thus protecting users' fund security.
1. Data Collection: Collect relevant information of associated entities of onboarding customers encountered in third-party payment scenarios, as well as transaction information data corresponding to their identity identifiers.
2. Data Processing: Perform statistical analysis on the collected transaction information data to calculate metrics including the number of transactions, number of nighttime transactions, number of early-morning transactions, first transaction time, last transaction time, transaction duration in years/months/days, transaction time span, proportion of early-morning transactions, proportion of nighttime transactions, etc.
3. Feature Engineering: Encode the associated entity features to obtain the vector MRC_features=Encoder_en(Entity_features), where Encoder_en is a pre-prepared entity feature encoder, and Entity_features are the associated entity features including associated entity type, province where the associated entity is located, ecological type, associated entity industry code, etc.; Perform binning and encoding on the transaction features separately, and assemble them into the transaction-dimensional vector TC_features=Encoder_nbr(Trade_featuers), where Encoder_nbr is a pre-prepared transaction feature encoder, and Trade_featuers are the transaction features including the number of transactions, first/last transaction time, number of nighttime/early-morning transactions, transaction duration in years/months/days, transaction time span, proportion of nighttime/early-morning transactions, number of high-risk amount transactions, percentage of high-risk amount transactions, etc.; Combine MRC_features, Entity_features, TC_features, etc., using the concat function to form features, and add the historically manually labeled risk categories (Label) to construct the feature and label matrix data;
4. Model Construction: The model is pre-trained and constructed. The matrix data is obtained from feature engineering, extract the training vector set X=data[features] from the matrix, and extract the label y=data[Label] from the feature matrix, where Label is the encoding of risk categories. Split the feature vectors and labels into training and test sets via X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=42), train the model based on the decision tree model with model.fit(X_train,y_train), and the model undergoes testing and production deployment with continuous optimization.
5. Model Output: For each piece of production data, it is processed and feature-encoded as described above to obtain the single-sample vector R_vector; obtain the risk disposal level R_Label=model.predict(R_vector) through the model, acquire the corresponding probability R_Rate=model.predict_proba(R_vector), calculate the risk score R_Score=100*R_Rate, and push the result to risk control experts for final confirmation.
提供机构:
快捷通支付服务有限公司
创建时间:
2024-11-12
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


