MedXpertQA
收藏Hugging Face2025-06-12 更新2025-06-13 收录
下载链接:
https://huggingface.co/datasets/ChuGyouk/MedXpertQA
下载链接
链接失效反馈官方服务:
资源简介:
MedXpertQA是一个包含4,460个问题的医学专业知识评估数据集,覆盖了多个医学专科、任务、身体系统和图像类型。数据集分为两个子集,MedXpertQA Text和MedXpertQA MM,分别针对文本和多媒体的医学评估。数据集中的问题来源于专家级别的资源,并经过了筛选、问题和选项的增强以及专家的审核。MedXpertQA MM引入了包含多种图像和丰富临床信息的问题,以丰富多媒体医学基准测试;而MedXpertQA Text则纳入了专科委员会的问题,以增强全面性。数据集特别设计了一个以推理为导向的子集,用于评估模型在数学和代码之外的推理能力。
MedXpertQA is a medical professional knowledge evaluation dataset containing 4,460 questions, covering multiple medical specialties, tasks, body systems, and image modalities. The dataset is divided into two subsets: MedXpertQA Text and MedXpertQA MM, which target text-based and multimedia medical evaluation respectively. The questions in the dataset are sourced from expert-level resources, and have undergone screening, enhancement of questions and options, and expert review. MedXpertQA MM introduces questions with diverse images and rich clinical information to enrich multimedia medical benchmark tests, while MedXpertQA Text incorporates specialty board examination questions to enhance its comprehensiveness. The dataset specially designs a reasoning-oriented subset to evaluate the reasoning capabilities of models beyond mathematical and code-based tasks.
创建时间:
2025-06-12
原始信息汇总
MedXpertQA 数据集概述
数据集基本信息
- 名称: MedXpertQA
- 类型: 医学问答评估基准
- 语言: 英语
- 许可证: MIT
- 任务类别: 问答系统
- 标签: 医学
- 规模: 1K<n<10K
数据集特点
- 挑战性: 评估专家级医学知识和高级推理能力
- 综合性: 包含4,460个问题,涵盖多种医学专业、任务、身体系统和图像类型
- 子集:
- MedXpertQA Text: 文本医学评估
- MedXpertQA MM: 多模态医学评估
数据集结构
- 特征:
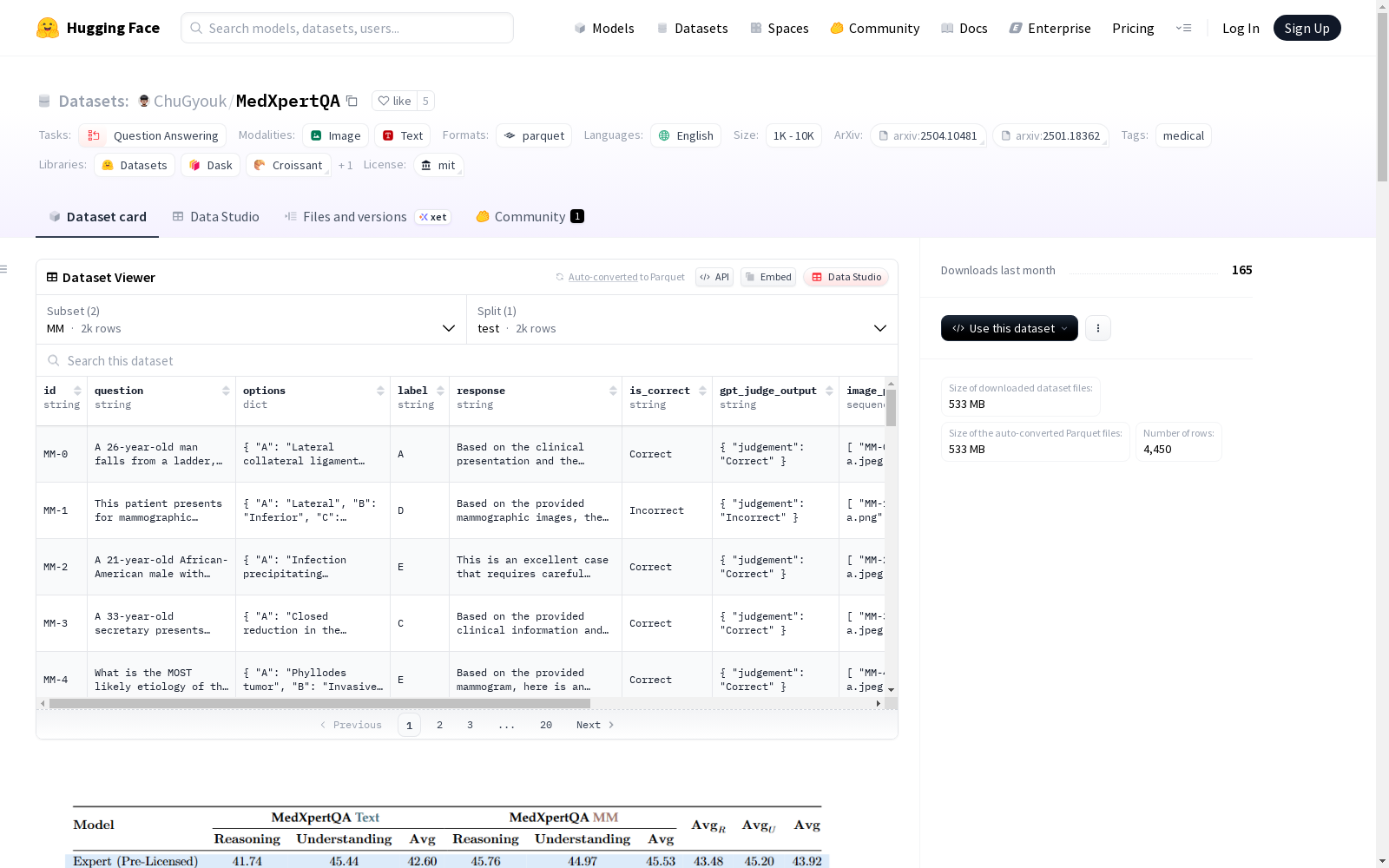
id: 问题IDquestion: 问题文本options: 答案选项(A-E)label: 正确答案标签response: gemini-2.5-pro-preview-06-05模型的响应is_correct: 响应正确性(由gpt-4.1-2025-04-14判断)gpt_judge_output: 判断输出image_paths: 图像文件路径列表images: 实际图像medical_task: 医学任务标签(诊断、治疗或基础医学)body_system: 相关人体系统标签question_type: 问题类型(推理或理解)
数据集分割
- 测试集:
- MedXpertQA Text: 2,450个问题
- MedXpertQA MM: 2,000个问题
相关资源
- 论文: MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
- GitHub仓库: TsinghuaC3I/MedXpertQA
引用
bibtex @article{zuo2025medxpertqa, title={MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding}, author={Zuo, Yuxin and Qu, Shang and Li, Yifei and Chen, Zhangren and Zhu, Xuekai and Hua, Ermo and Zhang, Kaiyan and Ding, Ning and Zhou, Bowen}, journal={arXiv preprint arXiv:2501.18362}, year={2025} }
搜集汇总
数据集介绍
构建方式
在医学知识评估领域,MedXpertQA数据集的构建采用了多阶段严谨流程。研究团队从专业医学资源中筛选具有临床代表性的问题,通过问题与选项的增强处理提升复杂性,并经由领域专家审核确保准确性。数据集划分为文本模态(Text)与多模态(MM)两个子集,分别包含2450和2000道测试题目,涵盖诊断、治疗与基础医学三大任务类别,并整合了人体系统分类与问题类型标注。
使用方法
该数据集专为评估医学人工智能模型的专家级知识掌握与推理能力而设计。使用者可通过加载标准化的parquet格式文件获取问题、选项、图像及标注信息,利用提供的模型响应结果与GPT-4.1评判输出进行性能比对。研究者可基于medical_task、body_system和question_type等维度进行细分评估,亦可通过分析judgement字段了解模型回答的准确性分布,为医学大语言模型的进阶优化提供基准参考。
背景与挑战
背景概述
医学人工智能领域近年来对专业级知识推理能力提出更高要求,MedXpertQA数据集应运而生。该数据集由清华大学临床医学院智能计算实验室主导开发,并于2025年正式发布,旨在构建专家级医学知识评估基准。其核心研究聚焦于突破传统医学问答数据集的局限性,通过整合多模态医学内容和专科委员会级难题,为评估大模型在复杂临床场景中的推理能力提供标准化测试环境。该数据集涵盖诊断、治疗、基础医学三大任务范畴,涉及全身各系统疾病,对推动医学人工智能向专业化方向发展具有里程碑意义。
当前挑战
医学领域问题的挑战主要体现在专家级知识要求的复杂性和动态性。诊断类问题需模型理解临床表现与病理机制的深层关联,治疗类问题要求掌握药物相互作用和个体化方案,而多模态数据融合更增加了跨模态推理的难度。构建过程中的挑战包括:专家级题源的筛选与标准化处理,需确保临床准确性和学术权威性;多模态数据的对齐与标注,特别是医学图像与文本信息的精确匹配;以及评估体系的设计,需要克服大模型输出不一致性带来的评判偏差,通过双重验证机制保证结果可靠性。
常用场景
经典使用场景
在医学人工智能领域,MedXpertQA数据集被广泛用于评估大型语言模型在专业医疗知识推理方面的能力。该数据集通过包含诊断、治疗和基础医学等多类医学任务的问题,要求模型进行多步骤临床推理并选择正确答案,从而模拟真实临床决策过程。其经典应用场景包括医学资格考试模拟、临床诊断辅助系统测试以及多模态医学问答系统的性能基准评估。
解决学术问题
该数据集有效解决了医学自然语言处理领域缺乏专家级评估基准的学术难题。通过提供涵盖不同身体系统和医学专业的标准化测试集,研究人员能够系统评估模型在复杂临床场景中的推理准确性。其引入的GPT评判机制为自动评估医疗问答系统提供了可靠方法,显著推进了医疗人工智能在可解释性和可靠性方面的研究进展。
实际应用
在实际医疗场景中,MedXpertQA为开发临床决策支持系统提供了重要测试基础。医疗机构可利用该数据集验证诊断辅助工具的准确性,医学教育机构则将其用于模拟专家级资格考试。制药企业可借助其评估药物咨询系统的可靠性,而远程医疗平台则通过该数据集优化智能问诊系统的表现,最终提升医疗服务的效率和质量。
数据集最近研究
最新研究方向
在医疗人工智能领域,MedXpertQA数据集正推动多模态医疗问答系统的深度发展。该数据集通过整合文本与图像信息,为评估大语言模型在复杂临床场景中的推理能力提供了标准化基准。当前研究聚焦于提升模型对非结构化医疗数据的理解能力,特别是在诊断推理和治疗方案生成方面的应用。随着GPT-4.1等先进评判机制的应用,研究者们正探索更可靠的自动评估框架,以降低对人工标注的依赖。这些进展不仅加速了医疗AI模型的迭代优化,也为构建可信赖的临床决策支持系统奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


