CookGen
收藏github2025-01-13 更新2025-01-14 收录
下载链接:
https://github.com/lambert-x/VideoAuteur
下载链接
链接失效反馈官方服务:
资源简介:
CookGen包含带有动作和字幕的长叙事视频。每个源视频被剪切成片段并与标记的“动作”匹配。我们使用来自Howto100M视频的ASR精炼伪标签和Youcook2视频的手动注释。所有视频片段的高质量字幕使用最先进的视觉语言模型(GPT-4和微调的视频字幕生成器)生成。
CookGen consists of long narrative videos paired with action annotations and subtitles. Each source video is segmented into clips and matched against annotated "actions". We employ ASR-refined pseudo-labels from Howto100M videos and manual annotations from Youcook2 videos. High-quality subtitles for all video clips are generated using state-of-the-art vision-language models, including GPT-4 and a fine-tuned video caption generator.
创建时间:
2025-01-13
原始信息汇总
VideoAuteur: 面向长叙事视频生成的数据集
数据集概述
VideoAuteur 是一个专注于长叙事视频生成的研究项目,旨在解决现有视频生成模型在生成长序列视频时面临的挑战。该项目提出了一个大规模烹饪视频数据集 CookGen,用于推动烹饪领域的长叙事视频生成。
CookGen 数据集
- 视频长度: 30-150 秒
- 剪辑时长: 5-30 秒
- 每个视频的剪辑数: 4-12 个剪辑
- 文本注释:
- 动作: 10-25 个单词(20-60 个标记)
- 字幕: 40-70 个单词(最多 120 个标记)
数据集来源
- Howto100M 视频: 使用 ASR 生成的伪标签进行标注
- Youcook2 视频: 使用手动标注
字幕生成
- 使用最先进的视觉语言模型(如 GPT-4 和微调的视频字幕生成器)为所有视频剪辑生成高质量的字幕。
VideoAuteur 管道
VideoAuteur 的生成管道包括两个主要组件:
1. 长叙事视频导演
- 使用交错自回归模型生成顺序输出
- 生成字幕、动作和视觉状态
- 特点:
- 优化的视觉潜在空间表示
- 专门的回归损失函数
- 为时间一致性优化的回归任务公式
2. 视觉条件视频生成
- 整合来自叙事导演的动作序列、字幕和视觉状态
- 超越传统的图像到视频方法
- 实现连续的视觉潜在条件
- 包括稳健的错误处理机制以确保输出稳定
演示
- 交错自回归导演生成
- 以语言为中心的导演生成
- 管道扩展(特斯拉汽车广告、电影预告片、自然纪录片)
引用
bibtex @article{xiao2024narrative, title={VideoAuteur: Towards Long Narrative Video Generation}, author={Xiao, Junfei and Cheng, Feng and Qi, Lu and Gui, Liangke and Cen, Jiepeng and Ma, Zhibei and Yuille, Alan and Jiang, Lu}, journal={arXiv preprint arXiv:2501.06173}, year={2024} }
致谢
特别感谢 Kelly Zhang、Ziyan Zhang、Yang Zhao 和 Jiaming Han 的支持和讨论。
免责声明
这是一个研究原型,并非字节跳动的官方支持产品。
搜集汇总
数据集介绍
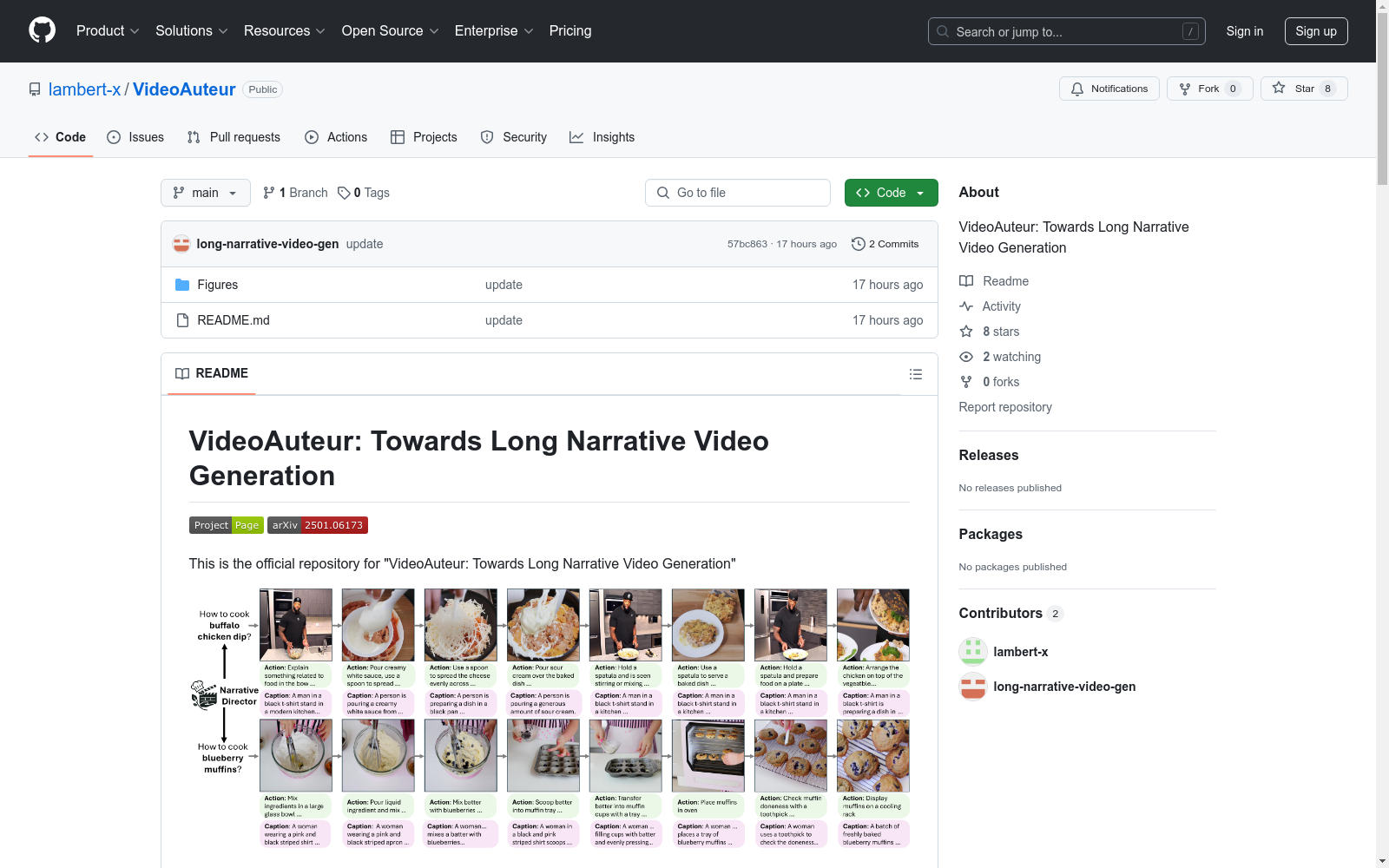
构建方式
CookGen数据集的构建过程体现了对长叙事视频生成领域的前沿探索。该数据集通过整合Howto100M视频的自动语音识别(ASR)伪标签和Youcook2视频的手动标注,确保了视频片段与动作标签的精确匹配。在此基础上,利用先进的视觉语言模型(如GPT-4和微调的视频字幕生成器)为每个视频片段生成高质量的文本描述,从而实现了视频内容与文本信息的深度对齐。
特点
CookGen数据集以其独特的长叙事视频生成能力脱颖而出。视频长度介于30至150秒之间,每个视频被分割为4至12个片段,片段时长为5至30秒。文本标注方面,动作描述包含10至25个单词(20至60个标记),而字幕则更为详细,包含40至70个单词(最多120个标记)。这种结构化的数据设计不仅支持视觉保真度,还通过语义对齐提升了视频生成的整体质量。
使用方法
CookGen数据集的使用方法围绕其长叙事视频生成的核心目标展开。用户可以通过整合动作序列、字幕和视觉状态,利用数据集提供的视觉条件视频生成技术,生成连贯且语义丰富的长视频。此外,数据集还支持微调技术,通过文本和图像嵌入的融合,进一步提升生成视频的视觉细节和语义一致性。具体实现可参考项目页面提供的演示,包括交错自回归导演生成和语言中心导演生成等扩展功能。
背景与挑战
背景概述
CookGen数据集由字节跳动的研究团队于2024年推出,旨在推动烹饪领域的长叙事视频生成研究。该数据集由Junfei Xiao等研究人员主导开发,核心研究问题聚焦于如何生成具有视觉细节和语义一致性的长叙事视频。CookGen数据集包含大量烹饪视频,每个视频被切割为多个片段,并配有详细的动作描述和高质量的文字注释。这些注释通过先进的视觉语言模型(如GPT-4)生成,确保了数据的准确性和丰富性。该数据集的推出为长叙事视频生成领域提供了重要的研究基础,推动了视频生成模型在语义连贯性和视觉质量上的提升。
当前挑战
CookGen数据集在构建过程中面临多重挑战。首先,长叙事视频生成需要解决视频片段之间的语义连贯性问题,确保生成的视频能够传达清晰且有意义的事件序列。其次,数据集的标注过程依赖于自动语音识别(ASR)和人工标注的结合,如何在保证标注质量的同时提高效率是一个关键挑战。此外,视频生成模型需要在视觉细节和语义一致性之间取得平衡,这对模型的训练和优化提出了更高的要求。最后,如何将文本和图像嵌入有效整合到视频生成过程中,以实现更高质量的输出,也是该领域亟待解决的技术难题。
常用场景
经典使用场景
CookGen数据集在长叙事视频生成领域具有重要应用,特别是在烹饪视频的生成中。该数据集通过提供详细的视频片段和高质量的文字注释,支持生成连贯且信息丰富的长视频序列。研究者可以利用这些数据训练和验证视频生成模型,以提升视频的视觉细节和语义一致性。
解决学术问题
CookGen数据集解决了长叙事视频生成中的关键问题,如视频片段的视觉保真度和文字注释的准确性。通过结合先进的视觉-语言模型和视频生成技术,该数据集显著提升了生成视频的视觉和语义一致性,为长叙事视频生成的研究提供了坚实的基础。
衍生相关工作
基于CookGen数据集,研究者开发了多种先进的视频生成模型和技术,如长叙事视频导演模型和视觉条件视频生成方法。这些工作不仅推动了长叙事视频生成领域的发展,还为其他相关领域如电影预告片和自然纪录片制作提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


